1.查看乳腺癌数据集,划分数据集
from sklearn.datasets import load_breast_cancer
cancer=load_breast_cancer()
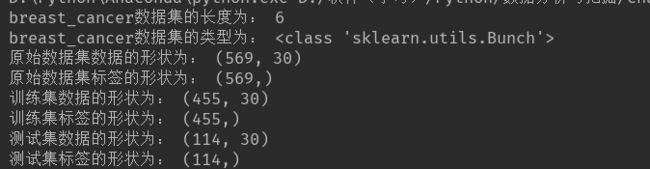
print('breast_cancer数据集的长度为:',len(cancer))
print('breast_cancer数据集的类型为:',type(cancer))
cancer_data = cancer['data']
cancer_target = cancer['target']
cancer_names = cancer['feature_names']
cancer_desc = cancer['DESCR']
print('原始数据集数据的形状为:',cancer_data.shape)
print('原始数据集标签的形状为:',cancer_target.shape)
from sklearn.model_selection import train_test_split
cancer_data_train, cancer_data_test,cancer_target_train, cancer_target_test = \
train_test_split(cancer_data, cancer_target, test_size=0.2, random_state=42)
print('训练集数据的形状为:',cancer_data_train.shape)
print('训练集标签的形状为:',cancer_target_train.shape)
print('测试集数据的形状为:',cancer_data_test.shape)
print('测试集标签的形状为:',cancer_target_test.shape)
2.离差标准化
import numpy as np
from sklearn.preprocessing import MinMaxScaler
Scaler = MinMaxScaler().fit(cancer_data_train)
cancer_trainScaler = Scaler.transform(cancer_data_train)
cancer_testScaler = Scaler.transform(cancer_data_test)
print('离差标准化前训练集数据的最小值为:',np.min(cancer_data_train))
print('离差标准化后训练集数据的最小值为:',np.min(cancer_trainScaler))
print('离差标准化前训练集数据的最大值为:',np.max(cancer_data_train))
print('离差标准化后训练集数据的最大值为:',np.max(cancer_trainScaler))
print('离差标准化前测试集数据的最小值为:',np.min(cancer_data_test))
print('离差标准化后测试集数据的最小值为:',np.min(cancer_testScaler))
print('离差标准化前测试集数据的最大值为:',np.max(cancer_data_test))
print('离差标准化后测试集数据的最大值为:',np.max(cancer_testScaler))
3.对乳腺癌数据集 PCA降维
from sklearn.decomposition import PCA
pca_model = PCA(n_components=10).fit(cancer_trainScaler)
cancer_trainPca = pca_model.transform(cancer_trainScaler)
cancer_testPca = pca_model.transform(cancer_testScaler)
print('PCA降维前训练集数据的形状为:',cancer_trainScaler.shape)
print('PCA降维后训练集数据的形状为:',cancer_trainPca.shape)
print('PCA降维前测试集数据的形状为:',cancer_testScaler.shape)
print('PCA降维后测试集数据的形状为:',cancer_testPca.shape)
4.对波士顿房价数据集处理数据
from sklearn.datasets import load_boston
boston = load_boston()
boston_data = boston['data']
boston_target = boston['target']
boston_names = boston['feature_names']
print('boston数据集数据的形状为:',boston_data.shape)
print('boston数据集标签的形状为:',boston_target.shape)
print('boston数据集特征名的形状为:',boston_names.shape)
from sklearn.model_selection import train_test_split
boston_data_train, boston_data_test, \
boston_target_train, boston_target_test = \
train_test_split(boston_data, boston_target,
test_size=0.2, random_state=42)
print('训练集数据的形状为:',boston_data_train.shape)
print('训练集标签的形状为:',boston_target_train.shape)
print('测试集数据的形状为:',boston_data_test.shape)
print('测试集标签的形状为:',boston_target_test.shape)
from sklearn.preprocessing import StandardScaler
stdScale = StandardScaler().fit(boston_data_train)
boston_trainScaler = stdScale.transform(boston_data_train)
boston_testScaler = stdScale.transform(boston_data_test)
print('标准差标准化后训练集数据的方差为:',np.var(boston_trainScaler))
print('标准差标准化后训练集数据的均值为:',
np.mean(boston_trainScaler))
print('标准差标准化后测试集数据的方差为:',np.var(boston_testScaler))
print('标准差标准化后测试集数据的均值为:',np.mean(boston_testScaler))
from sklearn.decomposition import PCA
pca = PCA(n_components=5).fit(boston_trainScaler)
boston_trainPca = pca.transform(boston_trainScaler)
boston_testPca = pca.transform(boston_testScaler)
print('降维后boston数据集数据测试集的形状为:',boston_trainPca.shape)
print('降维后boston数据集数据训练集的形状为:',boston_testPca.shape)
