Hadoop运行模式包括:本地模式、伪分布式模式以及完全分布式模式。我们本次主要完成搭建实际生产环境中比较常用的完全分布式模式,搭建完全分布式模式之前需要对集群部署进行提前规划,不要将过多的服务集中到一台节点上,我们将负责管理工作的namenode和ResourceManager分别部署在两台节点上,另外一台节点上部署SecondaryNamenode,所有节点均承担Datanode和Nodemanager角色,并且datanode和nodemanager通常存在同一节点上,所有角色尽量做到均衡分配。
集群部署规划如表1。
对集群角色的分配主要依靠配置文件制定,配置集群文件细节如下。
(1)核心配置文件core-site.xml,该配置文件属于Hadoop的全局配置文件,我们主要进行配置分布式文件系统的入口地址NameNode的地址和分布式文件系统中数据落地到服务器本地磁盘位置的配置,如下:
[atguigu@hadoop102 hadoop]$ vi core-site.xml
(2)Hadoop环境配置文件hadoop-env.sh,在这个配置文件中我们主要需要制定jdk的路径JAVA_HOME,避免程序运行中出现JAVA_HOME找不到的异常。
[atguigu@hadoop102 hadoop]$ vi hadoop-env.sh
export JAVA_HOME=/opt/module/jdk1.8.0_144
(3) HDFS配置文件hdfs-site.xml,在这个配置文件中主要进行配置HDFS文件系统属性配置。
[atguigu@hadoop102 hadoop]$ vi hdfs-site.xml
(4)YARN的环境配置文件yarn-env.sh,同样将JAVA_HOME路径配置指明。
[atguigu@hadoop102 hadoop]$ vi yarn-env.sh
export JAVA_HOME=/opt/module/jdk1.8.0_144
(5)关于YARN的配置文件yarn-site.xml,其中配置YARN的相关参数,主要配置一下两个参数。
[atguigu@hadoop102 hadoop]$ vi yarn-site.xml
(6)mapreduce的环境配置文件mapred-env.sh,同样将JAVA_HOME路径配置指明。
[atguigu@hadoop102 hadoop]$ vi mapred-env.sh
export JAVA_HOME=/opt/module/jdk1.8.0_144
(7)关于MapReduce的配置文件mapred-site.xml,主要配置一个参数,指明MapReduce的运行框架为YARN.
[atguigu@hadoop102 hadoop]$ cp mapred-site.xml.template mapred-site.xml
[atguigu@hadoop102 hadoop]$ vi mapred-site.xml
(8) 主节点NameNode和ResourceManager的角色在配置文件中已经做了配置,从节点的角色还需指定,配置文件slaves就是用来配置Hadoop集群中各个从节点角色的。如下,对slaves文件进行修改,即将3台节点全部指定为从节点,可以启动DataNode和NodeManager进程。
/opt/module/hadoop-2.7.2/etc/hadoop/slaves
[atguigu@hadoop102 hadoop]$ vi slaves
hadoop102
hadoop103
hadoop104
(9)在集群上分发配置好的Hadoop配置文件,这样3台节点即享有相同的Hadoop的配置,可准备通过不同的进程启动命令进行启动了。
[atguigu@hadoop102 hadoop]$ xsync /opt/module/hadoop-2.7.2/
(10)查看文件分发情况
[atguigu@hadoop103 hadoop]$ cat /opt/module/hadoop-2.7.2/etc/hadoop/core-site.xml
创建数据目录
根据core-site.xml中配置的分布式文件系统最终落地到各个数据节点上的本地磁盘位置信息/opt/module/hadoop-2.7.2/data/tmp,自行创建该目录。
[atguigu@hadoop102 hadoop-2.7.2]$ mkdir /opt/module/hadoop-2.7.2/data/tmp
[atguigu@hadoop103 hadoop-2.7.2]$ mkdir /opt/module/hadoop-2.7.2/data/tmp
[atguigu@hadoop104 hadoop-2.7.2]$ mkdir /opt/module/hadoop-2.7.2/data/tmp
启动Hadoop集群
(1)如果集群是第一次启动,需要格式化NameNode
[atguigu@hadoop102 hadoop-2.7.2]$ hadoop namenode -format
(2)通过start-dfs.sh命令在配置了namenode的节点启动HDFS,即可同时启动所有的datanode和SecondaryNameNode节点。
[atguigu@hadoop102 hadoop-2.7.2]$ sbin/start-dfs.sh
[atguigu@hadoop102 hadoop-2.7.2]$ jps
4166 NameNode
4482 Jps
4263 DataNode
[atguigu@hadoop103 hadoop-2.7.2]$ jps
3218 DataNode
3288 Jps
[atguigu@hadoop104 hadoop-2.7.2]$ jps
3221 DataNode
3283 SecondaryNameNode
3364 Jps
(3)通过start-yarn.sh命令启动yarn,大数据培训即可同时启动ResourceManager和所有的Nodemanager节点。需要注意的是:NameNode和ResourceManger如果不是同一台机器,不能在NameNode上启动 yarn,应该在ResouceManager所在的机器上启动yarn。
[atguigu@hadoop103 hadoop-2.7.2]$ sbin/start-yarn.sh
通过jps命令可在各个节点上查看进程启动情况,显示如下所示即表示启动成功。
[atguigu@hadoop103 hadoop-2.7.2]$ sbin/start-yarn.sh
[atguigu@hadoop102 hadoop-2.7.2]$ jps
4166 NameNode
4482 Jps
4263 DataNode
4485 NodeManager
[atguigu@hadoop103 hadoop-2.7.2]$ jps
3218 DataNode
3288 Jps
3290 ResourceManager
3299 NodeManager
[atguigu@hadoop104 hadoop-2.7.2]$ jps
3221 DataNode
3283 SecondaryNameNode
3364 Jps
3389 NodeManager
Web UI查看集群是否启动成功
(1) 通过web端输入我们之前配置的NameNode节点地址和端口号50070我们可以查看HDFS文件系统,例如:浏览器中输入:http://hadoop102:50070 ,可以检查NameNode和DataNode是否正常。如图1所示
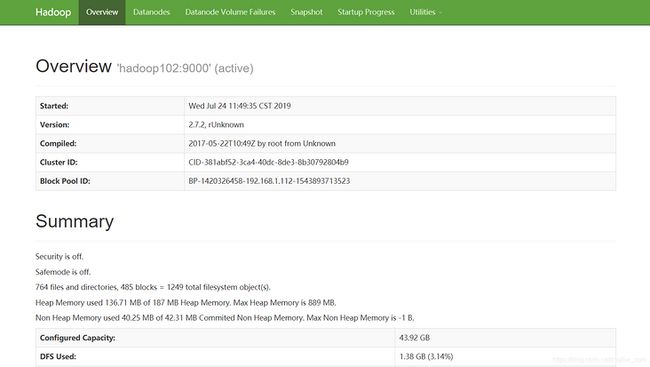
图1 NameNode的web端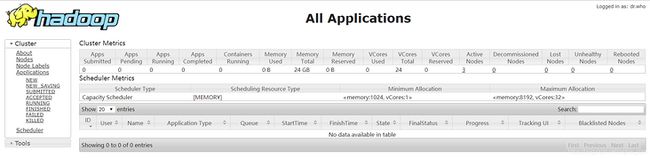
(2) 通过在web端输入配置ResourceManager节点地址和端口号8088,可以查看YARN上运行任务情况。例如:在浏览器输入:http://hadoop103:8088 ,即可查看本集群YARN运行情况。如图2所示。
图2 YARN的web端
- 运行PI实例检查集群是否启动成功
在集群任意节点上执行下面的命令,如果看到如图3所示的执行结果,则说明集群启动成功。
[atguigu@hadoop102 hadoop]$ cd /opt/module/hadoop-2.7.2/share/hadoop/mapreduce/
[atguigu@hadoop102 mapreduce]$ hadoop jar hadoop-mapreduce-examples-2.7.2.jar pi 10 10
最后输出为
Estimated value of Pi is 3.20000000000000000000

图3 PI实例运行结果