以下内容调研截止到2021/11/5日
- IPFS简介
IPFS是一种内容可寻址、点对点、分布式文件系统。IPFS采用内容-地址寻址技术,即通过文件内容进行检索而不是通过文件的网络地址。简单来说,就是对文件内容进行hash运算,将hash值作为文件名保存在本地数据库中,所以,只要文件内容不变,则文件名也保持不变。
- IPFS文件存储形式
多个运行IPFS程序的节点构成IPFS存储网络,存储在IPFS网络中的数据被划分成多个块,存放在不同节点中。当节点请求网络中的数据时,会在节点本地缓存该文件。即每个节点都保存其下载过的文件的缓存,用来保证即使某一个存有该资源的节点推出IPFS网络,该资源仍然可以被其他节点访问。当用户把文件上传到IPFS节点存储时,节点会将文件分块后进行存储,每个文件块以Merkle有向无环图(如图1所示)的形式组织,而Merkle有向无环图的根哈希则用来表示该文件。同时采用分布式Hash表(如图2所示)实现通过hash值到文件内容的定位。
本地表中存储文件的K/V值。正如我们在前面所提到的,每个文件在保存到 IPFS 网络中都可能进行分片,即把大的文件分成小的碎片,每个碎片有自己的哈希,根据碎片的哈希生成对应的 Link,以碎片在文件中出现的顺序,使用这些 Link 生成连接数组,使用连接数组生成最终的顶层 Object 对象,以此来表示文件。每一个分块都可以作为Object对象进行访问。
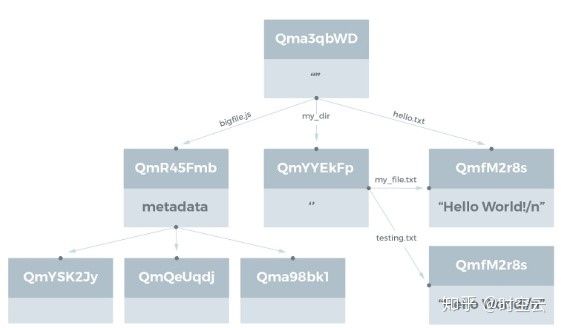
图1 Merkle有向无环图

图2 IPFS存储对象数据结构
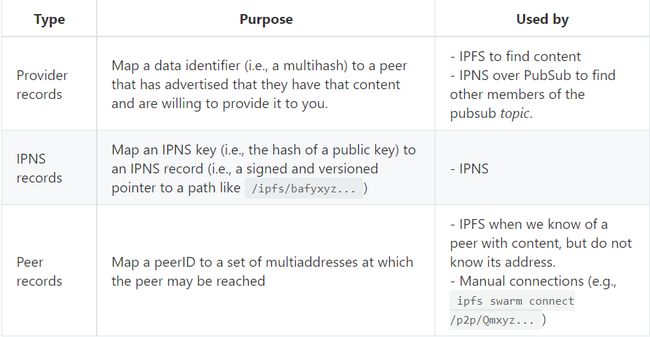
图3 分布式hash表
当存储小文件时,会直接将该文件存到DHT(分布式hash表)上。存储大文件时,会存储文件的根hash和对应节点的ID。DHT中存储三种类型的记录。
- 内容标识(用户正在寻找的内容CID)到节点标识的映射
- 节点标识到节点地址的映射
- ipns名称到ipns指针的映射
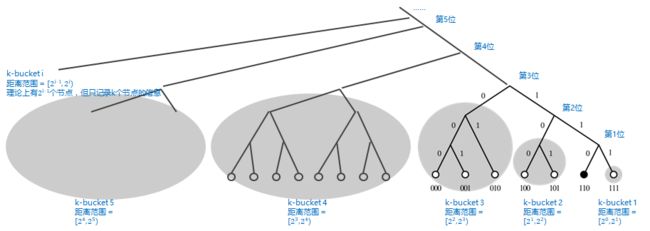
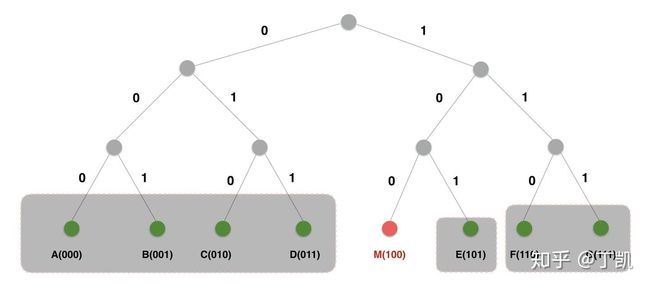
图4 K桶
如果一个节点的ID,前面所有位数相同,从倒数第n位开始不同,这样的节点只有2(i-1)个,与基础节点的距离范围为[2(i-1), 2i);对于0000110而言,这样的节点归为“k-bucket i”;
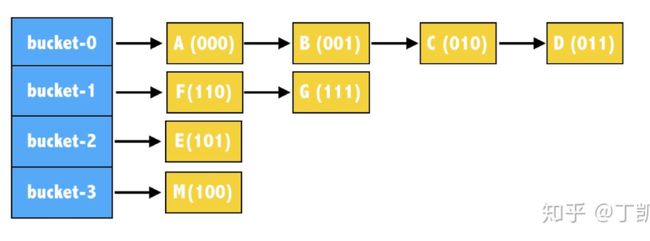
图5 M节点维护的路由表
Kademlia协议对每个桶内维护的节点数设置了一个上限,一旦桶内节点数超过,便根据一定的淘汰算法进行更新,一般上限设置为20。
搜索时间复杂度为O(log2n),n是指网络的规模。
当节点查到文件根hash时,同时也拿到了link数组,发起广播,询问谁有数组中的hash块,请发给我。
(1)新节点加入情况:
当有新节点N加入时,需要通过访问网络中的任一节点S ,以S作为中介加入网络,具体来说:
- 将S加入本地路由表,成为N的种子节点;
- N向S发起一次节点查询请求,查询的目的节点其实是自身;该请求的目的有二:第一告诉S新增了节点N,第二通过S发现集群中更多的节点。而发起了指向自身的查询请求也很有意思:其一是因为N此时还不知道系统更多的节点信息;其二是通过这种方式N可以快速地找到更多距离自己更接近的节点。
- S收到N的查询目标节点请求,首先将节点N加入自身的路由表中,然后给 N最多返回K个距离N更接近的节点信息;
- N收到S的响应,将响应中的节点加入自身路由表,然后对这些节点分别发起查询请求,当然,查询的目标还是自身。
- 最后,节点N在更新路由表的过程中,主动存储文件Hash值距离自己比访问节点更近的数据文件。
(2)节点离线:
节点离线在Kademlia协议中无需做特殊处理,如果某个节点离线,那么其离线事件最终会反馈到网络节点的路由表中,将其从路由表中剔除即可。
(3)数据冗余存储:
并不能保证在任一时刻目标节点N均一定存在或者在线,因此Kad网络规定:任一条目,依据其key的具体取值,该条目将被复制并存放在节点ID距离key值最近(即当前距离目标节点N最近)的k个节点当中;之所以要将重复保存k份,这完全是考虑到整个Kad系统稳定性而引入的冗余;
- 基于IPFS的文件下载方式
运行IPFS的节点,既是客户端又是服务器。客户端通过发送文件名到服务器,请求下载文件,服务器会根据文件名到分布式Hash表中查找对应的文件,查找成功后将文件发送给客户端,当文件下载完成后,客户端通过对文件内容进行hash运算,将hash值和文件名作比较就可以确定文件的完整性。
IPFS采用Kademlia协议实现节点路由及内容查询。当查询一个内容时,先计算hash值,再将该hash值与节点ID进行异或,得到距离,根据距离去对应的K桶中查找,若查找不到,询问谁是距离最近的节点,得到最近的节点,在该节点上再次执行该算法,直到找到对应节点。
找到对应节点后,再次查询该DHT表,找到该节点对应的ip地址等信息定位到该节点,再查询该节点的本地数据库,得到要查找的文件内容。
- 基于IPFS的EOS存储模块
通过在GitHub网站中EOS仓库中提问得出EOS并未实现基于IPFS的存储。以下内容摘自EOS存储白皮书及网上博客资料。
EOS存储的核心是IPFS,它提供了一个任何人都可以托管文件的去中心化网络,这些文件可以通过地址远程访问。区块生产者实际代表了21个超级节点,每个超级节点需要拥有支持高吞吐EOS交易量的数据中心,可以在全球范围提供文件托管服务,而且只要有至少一个超级节点在线,用户的文件就是可以访问的。
EOS设计了一套文件系统智能合约,发行了一种 token 叫TOK。它允许每个EOS客户端可以定义一个本地home目录,用于存放IPFS文件链接。链接内容主要包括本地home目录路径、文件名(文件内容的hash值)、文件大小。
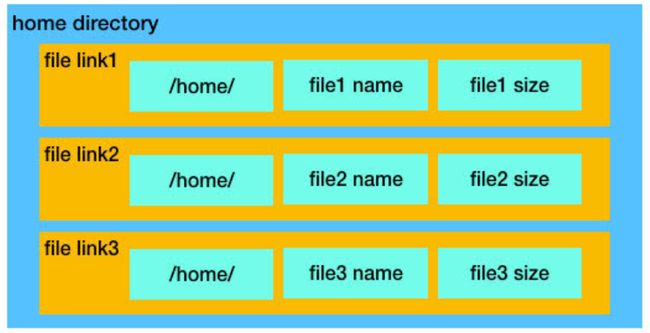
图6 目录结构
用户上传文件时,将文件链接打包成交易信息,签名后广播给区块生产者,然后用户通过EOS存储软件定义的标准化REST应用程序接口将文件上传到其中一个区块生产者。区块生产者会验证文件和文件名匹配,然后将交易广播发送到整个区块链系统,其他的区块生产会通过IPFS网络复制那个文件。这样用户就成功的上传了一个文件,同时在的home目录下保存了该文件的链接。和使用EOS资源类似,当用户需要存东西的时候,系统就会锁定一部分的TOK,当然如果用户不需要存东西了,系统就会解锁TOK。
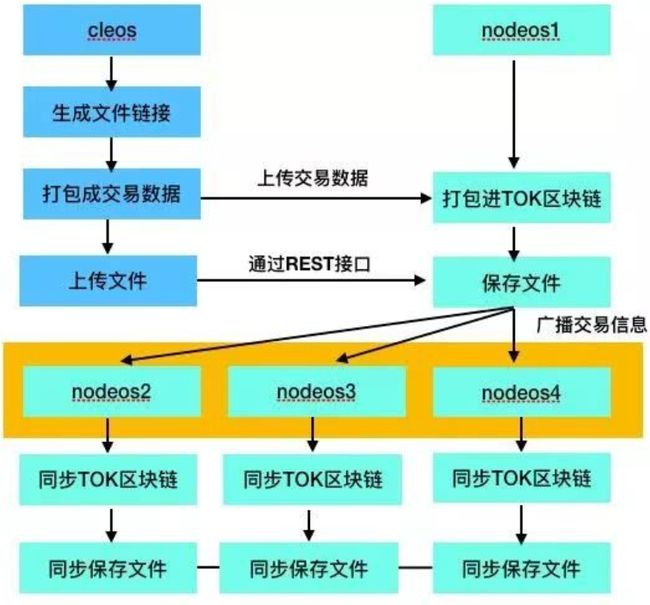
图7 上传流程
文件上传成功后,当客户端需要下载文件时,只需要将文件名发给生产者服务器,然后,服务器通过IPFS检索到对应的文件发送给客户端即可。一般来说,IPFS文件系统中的文件都是只读的,因为文件内容的细微修改就会导致客户端校验失败。
- 长安链采用的链下数据存储方案
长安链暂未使用IPFS进行存储。长安链现已实现使用LevelDB、RocksDB、MySQL进行存储。同时长安链会将区块的历史数据归档在链下数据库中进行存储,采用MySQL数据库进行存储,存储状态数据和非状态数据。
- 状态数据,仅存储最新的数据快照,无历史版本。
- 非状态数据,如:区块、交易、历史读写集。
长安链采用MySQL数据库实现链下存储,IPFS存储格式后续会进行支持。
- 长安链IPFS使用方式
长安链暂时还没有实现基于IPFS的存储系统,但长安链采用了基于IPFS的组网方式。
长安链基于IPFS提供的DHT,实现TLS的证书认证服务。
长安链支持自动发现、自动连接的组网方式,默认在线的每个节点都可以作为种子节点为其他节点提供网络发现服务,每个种子节点都会记录网内节点地址信息。当有新节点连接到某个种子节点时,新节点会向该种子节点查询网内其他可连接节点的地址,拿到其他节点地址后,新节点会主动尝试与这些节点建立连接;另外,种子节点在接受了新节点链接后,会通过网络发现服务将该新节点的地址通知给其他在线的种子节点,其他节点在获得该新节点地址后,也会主动尝试与该新节点建立连接。
- 采用IPFS存储的代表性区块链
EOS、Filecoin(github上点赞数1.9K)等。
- IPFS与MySQL扩容方案对比
IPFS是一个对标HTTP协议的内容寻址协议,底层采用leveldb作为数据库。
若采用MySQL实现存储量弹性扩展,首先是查询性能较K/V数据库较低,二是SQL语句过于灵活,难以控制。
- IPFS存储优势
- 存储负载均衡
- 分布式存储,去中心化,P2P通信
- 文件分块存储,解决重复存储问题
HDFS:中心化、距离的度量是物理距离。一个HDFS集群是由一个NameNode和若干个DataNode组成的。其中NameNode作为主服务器,管理文件系统的命名空间和客户端对文件的访问操作;集群中的DataNode管理存储的数据。