利用TextRank算法制作一个可以提取聊天关键词的QQ群机器人
文章目录
- 前言
- 效果
- TextRank算法
-
- PageRank算法
- TextRank算法
-
- 共现关系
- 滑动窗口
- 图构建
- 关键词抽取思路
- 实现过程
-
- 大体思路
- Nonebot框架介绍
- 技术细节
-
- 会话监听
- 数据预处理
- 分词
- 使用TextRank算法抽取关键词并生成词云
- 定时任务设定
- 代码库
- 参考资料
前言
发现自己已经很久没有更新博客了,读研的这些日子其实过得并没有想象中的那么顺利。这学期发现自己其实并不适合搞科研…唉,希望能顺利毕业吧。
言归正传,本篇博文将介绍如何利用TextRank算法实现一个可以提取QQ群聊天热词的机器人。制作这个机器人的初衷是:有的QQ群非常活跃,可能没一会儿,消息就99+了,这样时间久了,就不想去翻历史记录了。但是在这些历史记录中,可能藏有我们感兴趣的话题,利用这个聊天机器人,就可以提取一段时间(例如一天)以内的聊天热词,这样我们就可以快速地了解这一天群内的小伙伴讨论了什么话题。
由于我比较喜欢科幻,我就把这个机器人称为FG(Fifth Generation),这是刘慈欣长篇科幻小说《超新星纪元》里的一台超级计算机,负责协助管理那个只有孩子们的世界。本文后续也会使用FG来指代这个聊天机器人。
效果
在讲解FG实现的过程前,先看下FG的最终效果:
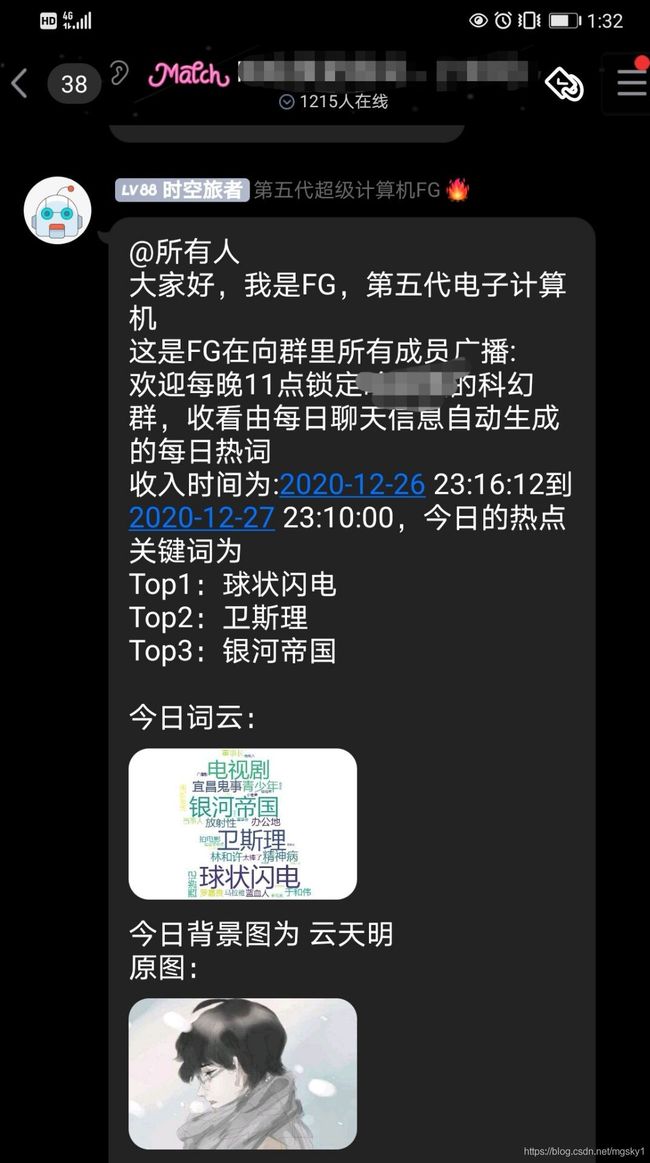
在FG的输出中,有这样几个元素
- 词云
- 前Top3个关键热词
这两个元素可以说是FG的核心功能之一了。之所以说之一,是因为FG还有其他技能,但这并不是本文讨论的重点。
TextRank算法
TexkRank算法起源于谷歌的PageRank算法,这里先简单介绍一下PageRank算法。
PageRank算法
PageRank算法最早是使用在搜索引擎的网页排序中,也就是可以把某一个搜索关键词相关的,最重要的网页排在前面。这个算法的主要思想是参考了民主投票的思想。
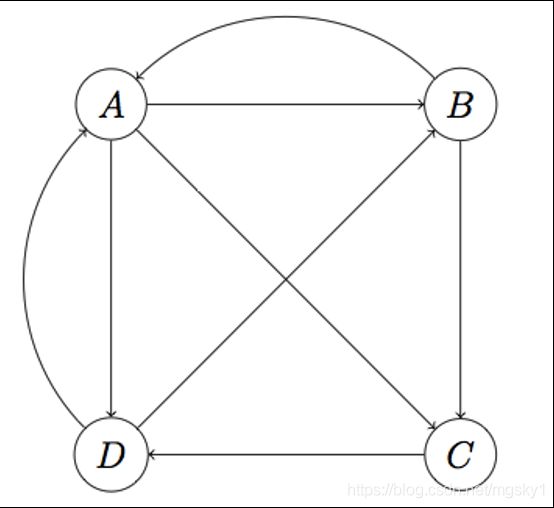
考虑这样的一幅图结构,图中的每一个节点表示一个网站,节点之间的有向边表示弧头的网站中有一个链接指向了弧尾的网站。
下面介绍PageRank的计算过程,在PageRank算法中,使用PR值来衡量一个网站的重要性:
- 刚开始的时候,假设所有网站的PR值都是一样的,为 1 n \frac{1}{n} n1,其中 n n n表示网站的总数量。例如上图, n = 4 n=4 n=4,于是每一个网站的初始PR值为 1 4 \frac{1}{4} 41
- 对于每一个网站,其出度的个数表示了这个网站“投”给其他网站的票数,也就是说,要将自己的PR值平均分给这些网站。例如上图,网站A有3个出度,那么A将自己的PR值平均分给网站B、C、D,每一个站点收到的值为 1 4 ∗ 1 3 = 1 12 \frac{1}{4} * \frac{1}{3} =\frac{1}{12} 41∗31=121
- 对于一个网站来说,其一次迭代后的PR值为其他网站“投”给自己票数的总和。例如上图中的网站B,收到了来自网站A和D的投票。因此,网站B的PR值为 1 12 + 1 8 = 5 24 \frac{1}{12} + \frac{1}{8} = \frac{5}{24} 121+81=245
- 重复第二步和第三步,直到每一个网站的PR值收敛即可
我们可以引入矩阵来加快计算的过程,这个矩阵叫做概率转移矩阵,其中的每一个元素代表了从某一个网站跳转到其他网站的概率。
上图的概率转移矩阵如下:
M = [ 0 1 / 2 0 1 / 2 1 / 3 0 0 1 / 2 1 / 3 1 / 2 0 0 1 / 3 0 1 0 ] M = \begin{bmatrix} 0&1/2& 0& 1/2\\ 1/3& 0& 0& 1/2\\ 1/3 & 1/2 & 0& 0\\ 1/3& 0& 1& 0 \end{bmatrix} M=⎣⎢⎢⎡01/31/31/31/201/2000011/21/200⎦⎥⎥⎤
注意与图邻接矩阵的区别:
- 邻接矩阵:行表示出度,列表述入度
- 概率转移矩阵:行表示入度,列表示出度。也就是说,每一列表示从该网站跳转到其他网站的概率
然后将所有网站的PR值构建一个列向量:
r a n k = [ 1 / 4 1 / 4 1 / 4 1 / 4 ] rank = \begin{bmatrix} 1/4\\ 1/4\\ 1/4\\ 1/4\\ \end{bmatrix} rank=⎣⎢⎢⎡1/41/41/41/4⎦⎥⎥⎤
然后利用矩阵的乘法运算,就可以批量求PR值了
M ∗ r a n k = [ 1 / 4 5 / 24 5 / 24 1 / 3 ] M * rank = \begin{bmatrix} 1/4 \\ 5/24\\ 5/24\\ 1/3\\ \end{bmatrix} M∗rank=⎣⎢⎢⎡1/45/245/241/3⎦⎥⎥⎤
将上述过程写成一个高大上的公式是这样的:
P R ( i ) = ∑ j ∈ i n ( i ) P R ( j ) ∣ o u t ( j ) ∣ PR(i) = \sum_{j\in in(i)}{\frac{PR(j)}{|out(j)|}} PR(i)=j∈in(i)∑∣out(j)∣PR(j)
其中, i n ( i ) in(i) in(i)表示指向节点i的节点集合, ∣ o u t ( j ) ∣ |out(j)| ∣out(j)∣表示指向节点i的节点集合中,第j个节点的出度。
上述就是传统的PageRank算法,但是这样存在两个问题:
- Rank Leak:等级泄漏,即遍历到后面,所有网站的PR值接近为0。用一句形象一点的话说,就像一桶水,由于桶上有裂缝,水漏光了。这种情况会在一个网页没有指向其他网页时发生。
- Rank Sink:等级沉没,即遍历到后面,PR值无法收敛。这种情况会在一个网页只有出度,没有入度的情况下发生。
为了解决这个问题,需要引入一个随机游走概率 d d d,这个概率 d d d表示用户会有 % d \%d %d的概率在网站内跳转,有 % 1 − d \%1-d %1−d的概率通过在浏览器中输入新网址,访问其他的网站。
改进后的单点迭代公式如下:
P R ( i ) = d ∗ ∑ j ∈ i n ( i ) P R ( j ) ∣ o u t ( j ) ∣ + ( 1 − d ) ∗ 1 N PR(i) = d * \sum_{j\in in(i)}{\frac{PR(j)}{|out(j)|}} + (1-d) * \frac{1}{N} PR(i)=d∗j∈in(i)∑∣out(j)∣PR(j)+(1−d)∗N1
其中 N N N为网站数量, d d d一般取0.85。
TextRank算法
讲完了PageRank算法,下面就要介绍TextRank算法了。在我看来,TextRank算法是PageRank算法在自然语言处理领域的一次成功应用。
TextRank算法的创新在于图构建,下面会介绍两个重要的概念,共现关系和滑动窗口。
共现关系
共现关系从字面上来看就是共同出现,也就是说,“共现”是指文献的特征描述信息共同出现的现象。在文献计量学中,关键词的共现方法常用来确定该文献所代表的学科中各主题词之间的关系。
例如在分析小说中人物之间的关系时,就可以使用共现关系。
滑动窗口
这个概念也比较容易理解,就是在文本上放置一个大小为 n n n的滑窗,让这个滑窗慢慢地滑过整片文章。
图构建
有了词共现关系和滑动窗口后,我们就可以开始构建图了,与PageRank算法不同,这里我们需要构建一个无向无权图。至于为什么要构造无向图,我的理解是无向图可以避免PageRank的那两个问题,另外一个原因是官方对无向图测试的比较多。
在TextRank算法中,图的顶点是候选关键词,对于图的边,做如下定义:
对于图中的任意两个节点,如果它们之间存在边,当且仅当它们所对应的关键词在滑动窗口中共同出现。
其中,官方实验表明,滑动窗口的大小越小,得到的结果会越精确。
下面就举例说明如何构建图:
假设有这样一句话:
宁波有什么特产能在上海世博会占有一席之地呢?
我们对其进行分词操作(去除停顿词和语气词),得到以下分词结果:
宁波、特产、上海、世博会、占有、一席之地
假设滑动窗口的大小为5,那么我们可以构建这样的一副图

图中的黄框和蓝框表示两次滑动窗口的结果。
关键词抽取思路
将文字构建成图后,我们可以用一个标记对应图中的一个节点,然后利用以下公式迭代至收敛即可(这个公式与PageRank很像,但是 1 − d 1-d 1−d没有乘 1 N \frac{1}{N} N1)。
P R ( i ) = d ∗ ∑ j ∈ i n ( i ) P R ( j ) ∣ o u t ( j ) ∣ + ( 1 − d ) PR(i) = d * \sum_{j\in in(i)}{\frac{PR(j)}{|out(j)|}} + (1-d) PR(i)=d∗j∈in(i)∑∣out(j)∣PR(j)+(1−d)
公式中参数的含义是与PageRank一致的。
将每一个词的PR值迭代到收敛,然后将PR值从大到小排序,就可以抽取出目标文本的关键词。
实现过程
大体思路
经验告诉我们,对于同一个话题的讨论,往往会是上下文连续的,因此我们可以把聊天记录看做是一篇文章,然后利用关键词提取算法就可以提取出某一段时间内的热词了。思想还是非常简单直接的。
- 可能有的朋友会问为什么不使用词频统计,那是因为单纯的词频统计没有办法将词与词之间的联系表达出来,导致这种方式一般效果都不好,因此不采用词频统计。
提取出关键词后,可以利用词云进行可视化展示,词云是目前文本可视化最简单直观的方式,但是如果多个关键词的权重差不多,那么就难以分辨轻重,因此,FG将前3个热词使用文本的方式输出。
Nonebot框架介绍
Nonebot是一款基于Python的异步QQ机器人框架,在酷Q关停之前是酷Q的插件之一,现在已有大神将其移植到Mirai上,同样作为插件提供。
技术细节
会话监听
Nonebot会监听目标QQ群中所有群成员的会话,并会触发async def handleGroupMsg(session)方法,我们可以在这个方法中,将群内的聊天记录记录到磁盘。
在FG中,对于每一个监听的群,都会有一个独立的文件夹放置其文件。
- 由于在抽取关键词的过程中会有IO操作,为了避免对同一个文件既读又写的情况,在FG中设定了两个文件,
chatA.txt和chatB.txt,它们使用布尔变量进行控制,在进行关键词抽取前完成对文件的切换。
@bot.on_message('group')
async def handleGroupMsg(session):
groupInfo = configuration['groupInfo']
for each in groupInfo:
if each['groupId'] == str(session['group_id']):
# 读取每个群文件夹的pkl
dataDict = IOUtils.deserializeObjFromPkl(os.path.join(os.getcwd(),'cn','acmsmu','FG','data',each['groupId'],'var.pkl'))
# 确定flag的值
flag = dataDict['flag']
# 确定要往哪一个文件中写入聊天记录
msg = time.strftime('%Y-%m-%d %H:%M:%S', time.localtime()) + ' ' + str(session['user_id']) + '\n' + session['raw_message'] + '\n'
if flag:
with open(os.path.join(os.getcwd(),'cn','acmsmu','FG','data',each['groupId'],'chatA.txt'), 'a', encoding='utf-8') as fileA:
fileA.write(msg)
else:
with open(os.path.join(os.getcwd(),'cn','acmsmu','FG','data',each['groupId'],'chatB.txt'), 'a', encoding='utf-8') as fileB:
fileB.write(msg)
break
数据预处理
由于原始的聊天记录中,会包含一些链接、QQ号、CQ码(酷Q的历史遗留产物)、还有多余的空行,所以要对聊天记录进行清洗。
在清洗的过程中,需要记录聊天记录的开始时间,为后面输出做准备。
# 数据预处理
def __cleaning(self):
chatlog = ''
try:
with open(os.path.join(os.path.join(os.getcwd(),'cn','acmsmu','FG','data',self.__groupId,self.__useFile)),'r',encoding='utf-8')as f:
isFirst = True
for eachLine in f:
# 获取聊天记录开始时间
if isFirst:
res = re.search('^\d{4}-\d{2}-\d{1,2} \d{1,2}:\d{2}:\d{2}',eachLine)
pos = res.span()
self.__beginTime = eachLine[pos[0]:pos[1]]
isFirst = False
else:
if re.search('^\d{4}-\d{2}-\d{1,2} \d{1,2}:\d{2}:\d{2} \d{5,11}',eachLine) is None:
# 正则非贪婪模式 过滤CQ码
eachLine = re.sub('\[CQ:\w+,.+?\]','',eachLine)
#过滤URL
eachLine = re.sub('(https?|ftp|file)://[-A-Za-z0-9+&@#/%?=~_|!:,.;]+[-A-Za-z0-9+&@#/%=~_|]','',eachLine)
# 特殊情况过滤
eachLine = eachLine.replace('[视频]你的QQ暂不支持查看视频短片,请升级到最新版本后查看。','')
if eachLine == '\n':
continue
chatlog += eachLine
except:
traceback.print_exc()
return chatlog
分词
这里先做一个说明:
- 为了稳定性考虑,TextRank算法我是调库了,textrank4zh,不过我也自己实现了该算法,代码已放在代码仓库中。
在textrank4zh中,是使用jieba分词进行分词的。这一款工具支持自定义词典和停顿词,可以满足用户的定制需求,当然需要实现需要改动textrank4zh的源码,不是很方面,后期考虑将这个功能引入到FG的配置文件中。
使用TextRank算法抽取关键词并生成词云
TextRank算法没啥好说的了,聊天记录清洗完毕后,调用库函数就可以直接生成候选关键词的倒序序列了。词云我使用的wordcloud库,TextRank算法对于每一个候选关键词的PR值可以作为wordcloud的词频参数。
# 关键词抽取
tr4w = TextRank4Keyword()
tr4w.analyze(text=chatlog,lower=True,window=windowSize)
wordDic = dict()
for item in tr4w.get_keywords(keyWordNum,word_min_len=keyWordLen):
# 将PR值作为词频
wordDic[item.word] = item.weight
# 生成词云
wc = WordCloud(font_path=fontPath,mask=mask,background_color='white')
wc.generate_from_frequencies(wordDic)
定时任务设定
我们希望FG能在每天的固定时刻触发热词功能,因此需要一个定时器的设定,Nonebot就内置了定时任务的功能。
我这里是对每一个群设置不同的触发时间,时间在FG的配置文件中设置
for each in groupInfo:
hour = each['beginHour']
minutes = each['beginMinutes']
nonebot.scheduler.add_job(handleTimer, 'cron',hour=hour,minute=minutes,args=[each['timer'],each['groupId']])
print('定时器' + each['timer'] + '定时任务添加成功!')
其中handleTimer为处理定时任务的回调函数,可以在其中完成聊天记录文件的切换以及热词的生成。groupInfo为QQ群的基本配置信息,包括群号、热词生成触发时间(时、分、秒)等,这些配置信息会从配置文件中读入。
代码库
- FG的Github仓库地址,欢迎Star或者Fork或者提供一些改进建议:https://github.com/mgsky1/FG
- 目前FG为Nonebot生态中的示例项目
参考资料
1、共现关系-tian_panda的博客-CSDN
2、MIHALCEA R, TARAU P. TextRank: Bringing Order into Text