java 提取文字内容_Java 提取PDF文本内容
概述
一般来说,我们无法对PDF文档格式的内容进行修改编辑,但当我们确有此需求时,可通过提取文本内容的方式来实现。本文就将介绍如何通过Java代码来提取PDF文档中的文本内容。
此教程用到的第三方控件是Free Spire.PDF for Java(免费版)。根据不同需求,它可以支持以下三方面的提取功能。
提取PDF文档中的所有文本内容
提取PDF指定页面的文本内容
提取PDF指定区域的文本内容
Jar包的获取及导入
在运行代码前,需将Free Spire.PDF for Java控件中的Jar包导入IDEA中。导入方式有两种:其一,在官网上下载产品包,解压后将lib文件夹下的Spire.Pdf.jar手动导入IDEA;其二,在IDEA中创建一个Maven项目,然后在pom.xml文件中键入以下代码,最后点击“Import Changes”即可。
com.e-iceblueid>
http://repo.e-iceblue.cn/repository/maven-public/url>
repository>
repositories>
e-icebluegroupId>
spire.pdf.freeartifactId>
3.9.0version>
dependency>
dependencies>
示例代码
示例1 提取PDF文档中的所有文本内容
import com.spire.pdf.PdfDocument;
import com.spire.pdf.PdfPageBase;
import java.io.*;
public class ExtractAllText{ public static void main(String[] args) { //创建PdfDocument实例
PdfDocument doc=new PdfDocument(); //加载PDF文档
doc.loadFromFile("C:UsersTest1DesktopSample.pdf"); //创建StringBuilder实例
StringBuilder sb=new StringBuilder(); PdfPageBase page; //遍历PDF页面,获取每个页面的文本并添加到StringBuilder对象
for(int i=0;itrue)); } FileWriter writer; try { //将StringBuilder对象中的文本写入到文本文件
writer = new FileWriter("output/ExtractAllText.txt"); writer.write(sb.toString()); writer.flush(); } catch (IOException e) { e.printStackTrace(); } doc.close(); }
}
提取效果:

示例2 提取PDF指定页面的文本内容
import com.spire.pdf.*;
import java.io.BufferedWriter;
import java.io.File;
import java.io.FileWriter;
import java.io.IOException;
public class ExtractTextFromParticularPage{ public static void main(String[] args) throws IOException { //加载PDF文档
PdfDocument pdf = new PdfDocument(); pdf.loadFromFile("C:UsersTest1DesktopSample.pdf"); //创建.txt文件,用于保存提取的文本
String result = "output/extractTextFromAParticularPage.txt"; File file=new File(result); if(!file.exists()){ file.delete(); } file.createNewFile(); FileWriter fw=new FileWriter(file,true); BufferedWriter bw=new BufferedWriter(fw); //获取第一页的文本
PdfPageBase page = pdf.getPages().get(0); String text = page.extractText(true); //String text = page.extractText(false);
bw.write(text); bw.flush(); bw.close(); fw.close(); }
}
提取效果:
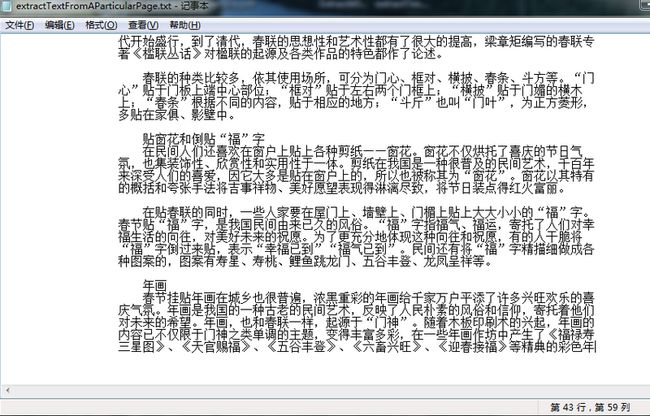
示例3 提取PDF指定区域的文本内容
import com.spire.pdf.*;
import java.awt.geom.Rectangle2D;
import java.io.BufferedWriter;
import java.io.File;
import java.io.FileWriter;
import java.io.IOException;
public class ExtractTextFromSpecificArea{ public static void main(String[] args) throws IOException { //加载PDF文档
PdfDocument pdf = new PdfDocument(); pdf.loadFromFile("C:UsersTest1DesktopSample.pdf"); //创建.txt文件,用于保存提取的文本
File file=new File("output/ExtractTextFromASpecifiedArea.txt"); if(!file.exists()){ file.delete(); } file.createNewFile(); FileWriter fw=new FileWriter(file,true); BufferedWriter bw=new BufferedWriter(fw); //获取第一页
PdfPageBase page = pdf.getPages().get(0); //提取第一页指定区域的文本
String text = page.extractText(new Rectangle2D.Float(80, 20, 500, 110)); bw.write(text); bw.flush(); bw.close(); fw.close(); }
}
提取效果:
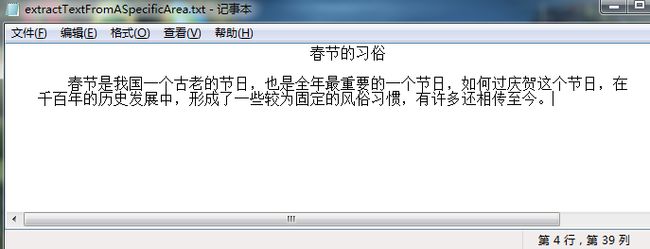
文章来源: segmentfault.com,作者:Millie_Yellow,版权归原作者所有,如需转载,请联系作者。
原文链接:segmentfault.com/a/1190000038215489