Dynamic TCP Initial Windows and Congestion Control Schemes through Reinforcement Learning笔记
原论文链接
文章目录
-
- Abstract
- 1. Introduction
- 2. Background
- 3. Core Idea and System Overview
- 4. RL for IW configuration
-
-
- The Online RL Algorithm
- user Grouping Algorithm
-
- 5. RL for CC configuration
-
- Overview
- A3C background
- training A3C offline
- Online Running of A3C
- 6. design and implementation
- 个人评价
Abstract
尽管经过了多年的改进,TCP的性能仍然不尽如人意。对于短流为主的服务(如web搜索、电子商务),TCP存在流启动问题,无法充分利用现代互联网的可用带宽:TCP从一个保守的静态初始窗口(IW, 2-4或10)开始,而大多数web流太短,无法在会话结束之前聚合到最佳的发送速率。对于以长流(如视频流、文件下载)为主导的服务,手动和静态配置的拥塞控制(CC)方案可能无法为最新的网络条件提供最佳性能。为了解决这两个问题,我们提出了TCP-RL协议,该协议使用 增强学习(RL) 技术来动态配置IW和CC,以提高TCP流传输的性能。基于在web服务的服务器端观察到的最新网络条件,TCP-RL通过 group-based RL 动态地配置适合于短流的IW,通过 deep RL 动态地配置适合于长流的CC方案。我们的大量实验表明,对于短流量,TCP-RL可以缩短平均传输时间约23%;对于长流量,并与14个CC方案的性能进行了比较,在给定的288种静态网络条件下,大约在85%情况下,TCP-RL 的性能能排在前5位,而大约90%的情况下,与相同网络条件下性能最好的CC方案相比,它的性能下降了不到12%。
1. Introduction
运用RL到实际生活中会有以下三个挑战,本文大部分内容都是围绕解决此三个Challenge而展开的:
- 如何只在服务器端测量新的TCP数据
- 如何将RL运用于高度可变的和不连续的互联网网络环境
- 如何从一个大的决策空间中搜索最优的TCP IW 或者CC
此paper的主要贡献:
- 为了解决挑战 1,我们修改了Linux内核和nginx软件程序用于存储TCP流的性能记录(比如,transmission time, throughput, loss rate, RTT),比较牛皮。
- 为了在配置IW的情况下处理挑战2,我们在grouped granularity(组粒度)上用了传统 model-free RL 方法,基本的想法就是运用 online exploration-exploitation 。另外我们提出了一个 bottom-up 的方法来根据相同的网络特征对用户流进行分组,最后比较了下以前的工作,TCP-RL能更好的利用历史数据来配置合适的IW。
- 为了在配置CC的情况下处理挑战2,TCP-RL准备在per-flow granularity(每个流的粒度)上利用deep RL的方法,他训练了一个离线网络,用于在线选择合适的CC。为了处理多变的网络环境,还建了个model用来detect网络的变化以便DRL更好地适应网络变化。
- 为了解决挑战3,在配置IW时,用了 sliding-decision-space 方法在决策搜索空间中快速收敛到最优的IW。在配置CC时,离线的神经网络可以在线选择合适的CC,而不用蛮力搜索。
- 据他们所知,利用这是第一次用RL来解决IW和CC配置问题的工作。并且仅需要改变发送端,而且TCP-RL已经在全球最大的搜索引擎之一(由作者单位,猜测是百度)中部署了一年多。大量实验表明,对于短流量,相比于传统的设置固定的IW=10,TCP-RL可以缩短平均传输时间约23%~29%;对于长流量,并与14个CC方案的性能进行了比较,在给定的288种静态网络条件下,大约在85%情况下,TCP-RL 的性能能排在前5位,而大约90%的情况下,与相同网络条件下性能最好的CC方案相比,它的性能下降了不到12%。
本paper的结构如下:
- part1 paper简要介绍
- part2 介绍背景
- part3 介绍核心思路并overview TCP-RL
- part4和5 分别介绍了配置IW和CC 的算法
- part6讲了下TCP-RL的实现细节
- part7和8 评估了下IW和CC 配置在TCP-RL上的性能
- part9 展示了相关工作
- part10 总结
2. Background
跳过
3. Core Idea and System Overview
- 配置IW(用于short-flow)的主要想法:提出根据相同的网络条件对用户进行分组,然后在每个用户组上采用online RL。作者认为在给定的时间和服务器上,用户的的网络特征(如subnet, ISP, province)极大的取决于client-server端到端的网络连接条件。所以在每个用户组上运行RL,会提升各个用户组的性能。存疑?继续往下看。
- 配置CC(用于long-flow)的主要想法:这个不像配置IW,而是要数据有数据,比如可以观察到网络状态(throughput, RTT, loss rate),所以训练了一个离线的神经网络用于state到action的映射。
TCP-RL Overview:

如上图所示TCP-RL的主要想法就是服务器端根据客户端给的performance(Throughput,RTT)来学习生成Parm,也就是IW or CC,客户端根据IW or CC做出发送调整,得到新的performance,如此往复。此过程不需要修改中间件(如,路由器、交换机和链路)。另外由于IW和CC可以独立配置,所以一般面向short-flow的服务器配置IW,面向long-flow的服务器配置CC。
- 对于IW的配置,需要区分前端服务器、brain 服务器和用户组。当某用户向前端服务器发送请求时,前端服务器会对此用户进行识别,判断属于哪个用户组。然后在向用户给出响应之前根据不同的用户组配置不同的IW。当向用户传完数据之后,前端服务器会给brain 服务器发送performance,brain服务器根据performance执行RL算法来更新不同用户组的IW,并每隔1分钟的发送至前端服务器。
- 在CC配置中,用户组是根据每个流作为粒度而区分的,并且brain服务器就是前端服务器本身。这个就比较简单了,就是先随机一个CC,然后得到一个state和reward,并将state和reward作为RL model的输入得到新的CC,如此往复,重复的间隔为1秒。RL model是离线的,会在part 5介绍。
4. RL for IW configuration
在配置IW中,本文设计了两种算法:The Online RL Algorithm 和 user Grouping Algorithm分别解决Challenge 3 和 2.
The Online RL Algorithm
将IW配置问题看成non-stationary multi-armed bandit problem,并通过the discounted UCB algorithm进行求解。
the discounted UCB algorithm如下图

图中有两个重要的公式 X ‾ t ( γ + i ) \overline{X}_t(\gamma+i) Xt(γ+i)和 c t ( γ + i ) c_t(\gamma+i) ct(γ+i),以下列出此俩公式的推导:
1、 X ‾ t ( γ + i ) \overline{X}_t(\gamma+i) Xt(γ+i)如下:
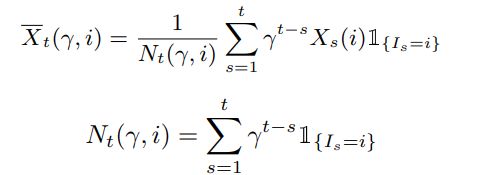
2、 c t ( γ + i ) c_t(\gamma+i) ct(γ+i)如下:
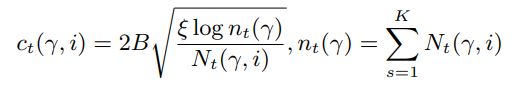
这两公式具体的符号说明看论文,在此不表。接下来讲下最关键的部分就是对于IW配置,如何定义reward function 和 arm(不清楚arm的可先去了解下non-stationary multi-armed bandit problem,RL中的一种场景)。
1、 reward function
目标是最大化 throughput和最小化RTT,reward function的定义如下:(省去分析部分,感兴趣可看原文)

为了使 X s ( i ) ∈ [ 0 , 1 ] X_s(i)\in[0,1] Xs(i)∈[0,1],所以每当 X s ( i ) > 1 X_s(i)>1 Xs(i)>1时,就需要在重新计算 X s ( i ) > 1 X_s(i)>1 Xs(i)>1之前,更新下 T h r o u g h p u t m a x 和 R T T s Throughput_{max}和RTT_s Throughputmax和RTTs。
2、 arms
传统的arms的集合是离散的,而在IW配置问题中,IW是连续的数字。为了配合离散的arms,作者利用创造性的思维设计了IW的离散状态,并称之为 sliding-decision-space。方法简单易用,但是能想到这点实属不易,所以称之为创造性思维不为过。作者先将n个IWs初始化一个arm list,比如[15,20,25,30]. 记arm list中最大的数值为 I W l a r g e IW_{large} IWlarge,最小的数值 I W s m a l l IW_{small} IWsmall,通过RL算法算出的最优IW为 I W b e s t IW_{best} IWbest。当 I W b e s t IW_{best} IWbest等于 I W l a r g e IW_{large} IWlarge或 I W s m a l l IW_{small} IWsmall时,更新arm list。更新规则如下图:
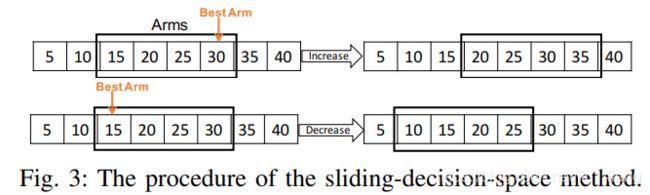
当 I W b e s t = I W l a r g e IW_{best}=IW_{large} IWbest=IWlarge时,更新arm list: a r m + = Δ arm += \Delta arm+=Δ; I W b e s t = I W s m a l l IW_{best}=IW_{small} IWbest=IWsmall时,更新armlist: a r m − = Δ arm -= \Delta arm−=Δ,此例中 Δ = 5 \Delta=5 Δ=5,其他情况不更新arm list。
user Grouping Algorithm
分组是因为不同的网络特性对应的网络状况是不一样的,而且分组也能在一定程度上增加学习样本的数量。但是分组也有困难,粒度过粗和过细都不行。算法详情如下:

不做具体解释,很好懂,原文有例子。上述判满足RL的条件是 J ≤ T J\leq T J≤T, 其中T 是自己设定的阈值,J为如下式子:
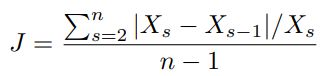
其中,X 就是之前说的奖励,n指的是n个time bins。具体符号说明看原文解释。
补充一下,到了第四步后,如果是蓝框的情况,则使用standard IW,绿框情况则应用RL来计算IW。从图可以看出是从底向上更新的,所以也就是文中常提到的 bottom-up 方法。
最后总结一下:做了两件事,为了解决Challenge 2,本文用到了model-free的RL方法来配置IW。为了解决细粒度下样本不够问题,提出一种自底向上的分组方法,也是为了找到满足RL context continuity requirement 的足够多的样本。
5. RL for CC configuration
Overview
大致介绍了下 CC configuration 的算法:训练一个离线的 RL model,用于在线选择合适的CC方案。另外为了解决网络的可变性,另外设计了一个 model 用于检测网络的变化,以便RL能够更好地适应网络的变化。RL的流程如下图所示:

具体细节后面会讲。
A3C background
RL 算法使用的是A3C, 算法具体含义请自行查阅资料。
- Input:state input, s t = ( t h r o u g h p u t t , R T T t , l o s s t ) s_t=(throughput_t,RTT_t,loss_t) st=(throughputt,RTTt,losst)
- Policy: π θ ( s t , a t ) \pi_\theta(s_t,a_t) πθ(st,at),
- Reward: r t = l o g ( t h r o u g h p u t t / R T T t ) r_t=log(throughput_t/RTT_t) rt=log(throughputt/RTTt)
training A3C offline
离线训练采用的是策略梯度下降算法,此算法的关键在于如何计算预期累计奖励(expected cumulative reward)的梯度的表示式,本文定义了一种表达式:

里面值得需要说的就是 A π θ ( s , a ) A^{\pi_\theta}(s,a) Aπθ(s,a)这个函数了,其定义如下:
![]()
其中的 γ \gamma γ代表discounting factor。V函数由critic network决定,TCP-RL的设计义如下图:
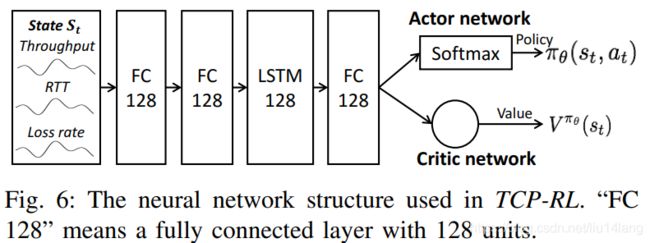
左边自不必多说,说说最后一层,分了两部分:actor network 和 critic network,分别输出相应策略的概率( π θ ( s t , a t ) \pi_\theta(s_t,a_t) πθ(st,at))和 V π θ ( s t ) V^{\pi_\theta}(s_t) Vπθ(st)。其中actor network是softmax输出,critic network是线性输出。
由以上设计图可知,我们需要将之前的损失函数加上与策略有关的损失函数,一边学习更好地策略。所以最终的目标梯度可写为:
![]()
这也是我们最终学习用的梯度。
Online Running of A3C
这个就比较简单了,刚开始的时候随机采用Action,过了几秒后根据收集的状态作为model的输入计算出Action。然后不断的重复此操作。另外还设计了一个神经网络专门用于检测网络状态是否发生变化,网络结构也比较简单,仅含有两层全连接层,输入是(last states, last action, current states), 输出是网络状态是否发生变化的概率。训练的话就是手动的造数据。如果检测到网络状态发生变化,则随机的采用一种新的CC方案。这样的目的是当网络状态发生变化后,会将之前的经验Action清空,重新获取新网络状态下的Action。
6. design and implementation
TCP-RL系统设计图如下:

简单介绍下上图主要的三个部分:
- Connection Manager:是web proxy(如nginx)里的一个实现模块。用于配置CC和IW,并且记录性能日志,注意CC存储的Neural Network,所以CC在线运行是在此实现的。
- Data Collector:收集和存储在fronted server 中所有的性能数据。
- Control Center:对于IW配置,会基于新的数据运行 User Grouping 和 RL算法;对于CC配置,在此训练离线RL model。另外在此会定期的更新IW table和Neural Network。
个人评价
总体来讲,此文分为两部分,不妨称之为IW部分和CC部分。
在IW部分中,作者使用了两个算法一个是用于解决non-stationary multi-armed bandit problem的the discounted UCB algorithm。另一个就是采用bottom-up的算法对用户进行分组,也称为user grouping algorithm。
在CC部分,作者也使用了两个算法,一个是传统的A3C算法用于解决相应RL场景问题。另一个是训练了一个神经网络用于检测计算机网络的变化,以便RL更能适应网络的变化。
- 首要印象就是,内容丰富,干货满满,非常紧凑。感觉稍微改改都能发两篇了,所以全文有点长,读起来有点吃力。
- 想法很独特,能将长流和短流区分开进行设计算法,而且每个算法都有对应的创新之处。
- 主要还应用到了实际场景,光这一点就值得学习。所以文中有些细节描述起来非常的具体,给人感觉就是非常有底气。
- 论文有些细节讲的比较好,比如CC配置时,开始的时候随机选取,过了几秒(如5秒)后再将收集的状态作为神经网络的输入,还有就是系统的设计的细节介绍的也比较好,此笔记未展开说明。
- 另外,图表也做得非常棒。
声明:本文并不是对论文进行全篇翻译(除摘要部分),而是自己对论文理解做的笔记,有误的话欢迎讨论交流。并且个人认为有些部分不重要会跳过,或提醒查看原论文。若转载请注明链接