对话系统有哪些最新进展?这17篇EMNLP 2021论文给你答案
©原创 · 作者 | 王馨月
学校 | 四川大学
研究方向 | 自然语言处理

Neural Path Hunter

论文标题:
Neural Path Hunter: Reducing Hallucination in Dialogue Systems via Path Grounding
论文链接:
https://arxiv.org/abs/2104.08455
项目地址:
https://github.com/nouhadziri/Neural-Path-Hunter
基于大型预训练语言模型的对话系统天然能够提供流畅自然的响应,但这些模型通常会生成事实上不正确的陈述,从而阻碍了它们的广泛采用。这篇论文中,作者专注于提高响应真实性(faithfulness)的任务,从而减少神经对话系统对知识图谱 (KG)提供的已知事实的幻觉。作者提出了 Neural Path Hunter ,它遵循先生成再优化的策略,即使用 KG 的 k 跳子图修改生成的响应。
Neural Path Hunter 利用一个单独的 token 级事实评论家来识别可能的幻觉来源,然后是一个由两个神经 LM 组成的链的细化阶段,该阶段通过制作在 k 跳子图上传播的查询信号来检索正确的实体。论文提出的模型可以轻松应用于任何对话生成的响应,而无需重新训练模型。作者在 OpenDialKG 数据集上进行了验证,相比于基于 FeQA 的对话响应将真实性相对提高了 20.35% 。

上图是 Neural Path Hunter 的概览。NPH 遵循先生成再优化的方法,通过增加传统对话生成和额外的优化阶段,使对话系统能够通过查询 KG 来纠正潜在的幻觉。NPH 通过限制由 KG 上的有效路径支持的保护流来建立对话生成。为此,该模块结合了一个 token 级别的幻觉评论家,该评论家屏蔽了话语中关注的实体。
然后是一个预先训练的非自回归 LM,它为每个被屏蔽的实体规定了上下文表示,然后将其顺序馈送到自回归 LM 以获得输出表示。然后,这些输出表示可用于有效地启动对 KG 的查询——有效地将对话建模为在局部 k 跳子图上传播的信号,从而通过对话历史强制执行局部性——返回事实正确的实体。

上表是在应用 Neural Path Hunter 之前和之后,基于 GPT2-KG 测试响应的选定响应。红色表示幻觉实体提及,绿色表示检索到的正确实体提及。

DIALKI

论文标题:
DIALKI: Knowledge Identification in Conversational Systems through Dialogue-Document Contextualization
论文链接:
https://arxiv.org/abs/2109.04673
项目地址:
https://github.com/ellenmellon/DIALKI
确定在基于长文档的对话系统中使用的相关知识对于有效生成响应至关重要。这篇论文引入了一种知识识别模型 DIALKI,该模型利用文档结构来提供对话上下文化的段落编码,以更好地定位与对话相关的知识。 与之前的工作相比,DIALKI 在开放式问答中扩展了多段阅读器模型,以获得基础文档中多段不同跨度的密集编码,并将它们与对话历史联系起来。
具体来说,DIALKI 通过将给定的长文档分成段落或部分来提取知识,并使用对话上下文将它们单独上下文化。然后通过首先选择与对话上下文最相关的段落,然后选择所选段落中的最终知识串来提取知识。处理每个段落而不是整个文档大大缩短了知识上下文,同时保留了足够的用于推理的话语上下文。
DIALKI 还使用多任务目标来识别下一回合的知识,以及先前回合使用的知识,通过捕获下一个代理话语、先前话语和基础之间的相互依赖关系,帮助改进对话和文档表示的学习文档。作者证明了模型在两个基于文档的对话数据集上的有效性,并提供了分析,显示了对看不见的文档和长对话上下文的泛化。

上图是 DAILKI 模型的概览。模型应用 BERT 和知识上下文化机制来获得对话上下文和知识表示(左),用于执行下一个(主要)和历史(辅助)回合知识识别任务(右)。对于每一轮,DIALKI 通过选择相关段落以及段落中的开始/结束跨度来识别知识。
作者在 Doc2Dial 和 WoW 对话数据集上进行实验,在知识识别任务上相较于之前的工作提升了60%和20% 。

TransferQA

论文标题:
Zero-Shot Dialogue State Tracking via Cross-Task Transfer
论文链接:
https://arxiv.org/abs/2109.04655
对话状态跟踪(DST)的 zero-shot 迁移学习使我们能够处理各种面向任务的对话域,而无需收集域内数据。这篇论文中,作者提出了 TransferQA,这是一种可迁移的生成 QA 模型,它通过文本到文本转换器框架无缝地结合了提取 QA 和多选 QA,并在 DST 中跟踪分类槽和非分类槽。此外,还引入了两种构建无法回答的问题的有效方法,即否定问题采样和上下文截断,这使得模型能够处理零样本 DST 设置中的“none”值槽。
实验表明,本文提出的方法大大改善了 MultiWoz 上现有的零样本和少样本结果。此外,与 Schema-Guided Dialogue 数据集上的 baseline 相比,本文的方法在看不见的领域显示出更好的泛化能力。
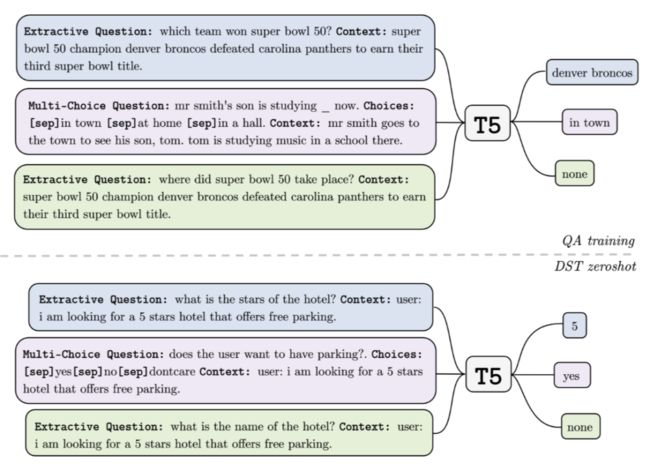
上图是零样本 DST 的跨任务传输的高级表示。在 QA 训练阶段(上图),统一生成模型(T5)在 QA 对提取问题(蓝色)、多项选择题(紫色)和否定提取问题(绿色)上进行预训练。在零样本 DST 的推理时间(下图),模型将槽值预测为综合制定的提取问题(对于非分类槽)和多项选择题(对于分类槽)的答案。

上图是用于在训练中添加无法回答的问题的负抽样策略。给定一个段落,从其他段落中随机抽取一个问题,并训练 QA 模型(T5)来预测“none”。
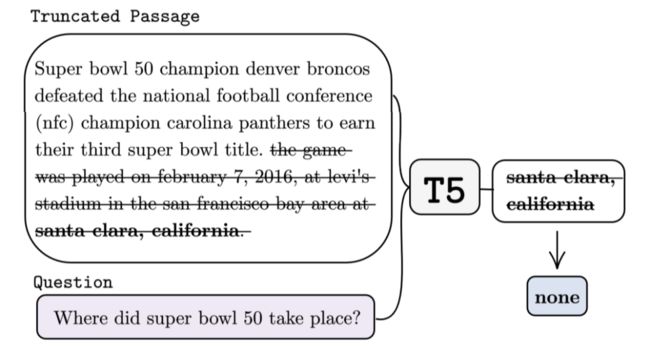
上图是用于生成 none 值的上下文截断策略。截断文章以确保上下文中不存在答案跨度,因此 QA 模型(T5)学会预测“none”。

KAT-TSLF

论文标题:
A Three-Stage Learning Framework for Low-Resource Knowledge-Grounded Dialogue Generation
论文链接:
https://arxiv.org/abs/2109.04096
项目地址:
https://github.com/neukg/KAT-TSLF
通过引入外部背景知识,神经对话模型可以在生成流畅和信息丰富的响应方面显示出巨大的潜力。然而,构建这种以知识为基础的对话很费力,而且现有模型在迁移到训练样本有限的新领域时通常表现不佳。因此,在资源匮乏的环境下构建知识型对话系统仍然是一个至关重要的问题。
这篇论文中,作者提出了一种基于弱监督学习的新型三阶段学习框架 TSLF,该框架受益于大规模无根据的对话和非结构化知识库。为了更好地与这个框架合作,作者还设计了一种带有解耦解码器的 Transformer 变体,它促进了响应生成和知识整合的分离学习。两个 baseline 的评估结果表明,论文中的方法可以在训练数据较少的情况下优于其他最先进的方法,即使在零资源场景中,仍然表现良好。
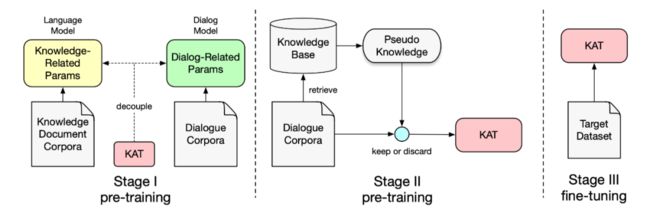
上图是论文中的 TSLF 流程的概览,共分三个阶段。
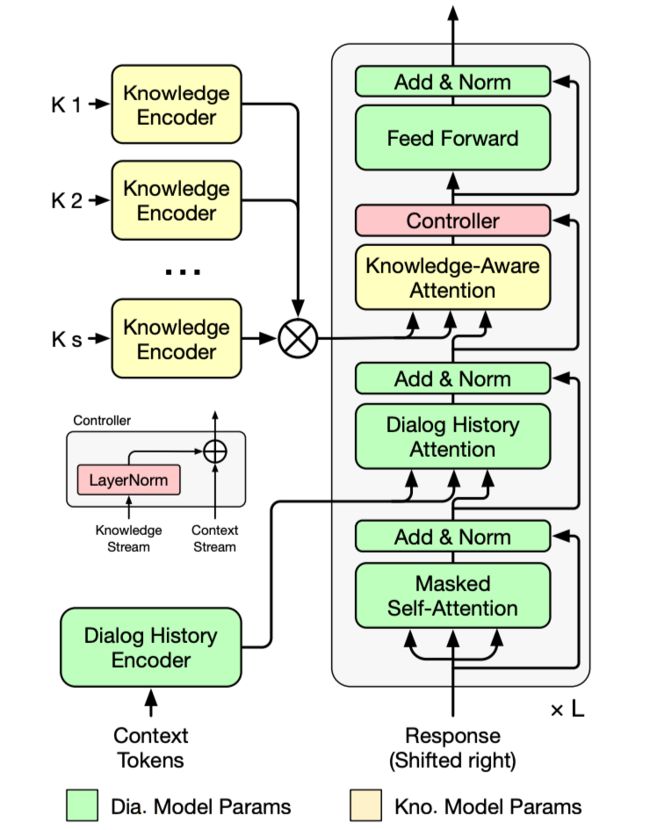
图中的 KAT,是 Knowledge-Aware Transformer。其架构如下图所示:

CG-nAR

论文标题:
Thinking Clearly, Talking Fast: Concept-Guided Non-Autoregressive Generation for Open-Domain Dialogue Systems
论文链接:
https://arxiv.org/abs/2109.04084
项目地址:
https://github.com/RowitZou/CG-nAR
人类对话包含不断发展的概念,说话者自然而然地将多个概念联系起来以组成一个回应。然而,目前采用 seq2seq 框架的对话模型缺乏有效管理概念转换的能力,并且很难以顺序解码的方式将多个概念引入到响应中。为了提升对话的连贯性,复旦大学张奇老师团队设计了一个概念引导的非自回归模型(CG-nAR)来生成开放域对话。
模型包括一个多概念规划模块,该模块学习从概念图中识别多个相关概念,以及一个定制的插入变换器,执行概念引导的非自回归生成以完成响应。在两个公共数据集上的实验结果表明,CG-nAR 可以产生多样且连贯的响应,在自动和人工评估中均优于最先进的 baseline ,推理速度大大加快。

上图是 CG-nAR 框架的概览。(a) 多概念规划模块以之前的概念流和对话上下文为条件,从概念图中仔细选择多个相关概念。(b) 所选概念用于初始化后续非自回归生成的部分响应。

上图是来自不同系统的输出响应的对话案例。蓝色是对话流中观察到的概念,红色表示输出响应中与上下文相关的概念。可以看出 CG-nAR 具有不错的效果。

DAMS

论文标题:
Low-Resource Dialogue Summarization with Domain-Agnostic Multi-Source Pretraining
论文链接:
https://arxiv.org/abs/2109.04080
项目地址:
https://github.com/RowitZou/DAMS
随着日常生活中对话数据量的快速增长,对于对话摘要的需求越来越大。然而,由于带有注释摘要的对话数据不足,训练大型摘要模型通常是不可行的。复旦大学张奇老师团队提出了一种多源预训练范式(DAMS),以更好地利用外部摘要数据。
作者利用大规模域内非摘要数据来分别预训练对话 encoder 和摘要 decoder。然后使用对抗性评论对域外摘要数据对组合的 encoder-decoder 模型进行预训练,来促进与域无关的摘要。在两个公共数据集上的实验结果表明,在只有有限的训练数据的情况下,模型实现了有竞争力的性能,并且在不同的对话场景中具有很好的泛化能力。
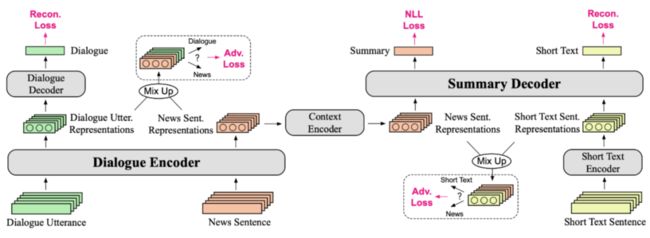
上图是 DAMS 的概览。DAMS 包括:(i) 使用对话的 encoder 预训练(绿色);(ii) 使用短文本的 decoder 预训练(黄色);(iii) 使用带有相应摘要(橙色)的通用文章进行联合预训练。

上图是用 SAMSum 测试集的对话例子生成的摘要,加*的表明使用了外部总结数据。

TUCORE-GCN

论文标题:
Graph Based Network with Contextualized Representations of Turns in Dialogue
论文链接:
https://arxiv.org/abs/2109.04008
项目地址:
https://github.com/BlackNoodle/TUCORE-GCN
基于对话的关系提取(RE)旨在提取对话中出现的两个参数之间的关系。由于对话具有人称代词出现次数高、信息密度低的特点,并且对话中的大部分关系事实都没有任何一个句子来支持,因此基于对话的关系抽取需要对于对话有全面的理解。
在这篇论文中,作者提出了通过关注人们理解对话的方式来建模的转向上下文感知图卷积网络(TUrn COntext awaRE Graph Convolutional Network, TUCORE-GCN)。此外,作者提出了一种新方法,将对话中的情绪识别(ERC)任务视为基于对话的 RE。基于对话的 RE 数据集和三个 ERC 数据集的实验表明,本文提出的模型在各种基于对话的自然语言理解任务中非常有效。

上图是 TUCORE-GCN 的整体架构。首先,通过将输入对话提供给上下文编码器来获得每个标记的上下文化表示。接下来,应用使用周围轮 mask 的 Masked Multi-Head Attention 来获得增强每个轮含义的表示。然后,TUCORE-GCN 构建对话图并应用 GCN 机制结合 BiLSTM。最后,分类模块使用来自前一个模块的信息来预测关系。
作者在 DialogRE、MELD、EmoryNLP 数据集上进行了实验,取得了很好的效果。

Unsupervised Conversation Disentanglement

论文标题:
Unsupervised Conversation Disentanglement through Co-Training
论文链接:
https://arxiv.org/abs/2109.03199
项目地址:
https://github.com/LayneIns/Unsupervised_dialo_disentanglement
对话解耦旨在将混合的消息分成分离的会话,这是理解多方对话的一项基本任务。在这篇论文中,作者探索在不参考任何人工注释的情况下训练对话解耦模型。
本文的方法建立在深度协同训练算法之上,该算法由两个神经网络组成:消息对分类器和会话分类器。前者负责检索两个消息之间的本地关系,而后者通过捕获上下文感知信息将消息分类为会话。两个网络分别使用从未注释语料库构建的伪数据进行初始化。在深度协同训练过程中,使用会话分类器作为强化学习组件,通过最大化消息对分类器给出的局部奖励来学习会话分配策略。
对于消息对分类器,通过从会话分类器预测的解耦会话中以高置信度检索消息对来丰富其训练数据。在大型电影对话数据集上的实验结果表明,与之前的监督方法相比,本文提出的方法实现了有竞争力的性能。

上图是本文提出的协同训练框架的示意图。一个消息对分类器(蓝色),可以检索两个消息之间的关系。关系分数将用作协同训练期间更新会话分类器的奖励。一个会话分类器(绿色),它可以通过检索消息和会话之间的关系来执行端到端的对话解耦。预测结果将用于构建新的伪数据,以在协同训练期间训练消息对分类器。

GOLD

论文标题:
GOLD: Improving Out-of-Scope Detection in Dialogues using Data Augmentation
论文链接:
https://arxiv.org/abs/2109.03079
项目地址:
https://github.com/asappresearch/gold
实用的对话系统需要强大的方法来检测范围外(out-of-scope, OOS)的话语,以避免对话中断和相关的失败。用标记的 OOS 示例直接训练模型会产生合理的性能,但获取此类数据是一个资源密集型过程。为了解决数据有限的问题,以前的方法侧重于更好地对范围内(in-scope, INS)示例的分布进行建模。
这篇文章引入了 GOLD(Generating Out-of-scope Labels with Data augmentation)作为一种正交技术,可以增强现有数据以训练在低数据状态下运行的更好的 OOS 检测器。GOLD 使用来自辅助数据集的样本生成伪标记候选者,并通过新颖的过滤机制仅保留最有益的候选者进行训练。
在三个目标基准的实验中,顶级 GOLD 模型在所有关键指标上都优于所有现有方法,相对于中值 baseline 性能实现了 52.4%、48.9% 和 50.3% 的相对收益。作者还分析了 OOS 数据的独特属性,以确定最佳应用 GOLD 方法的关键因素。
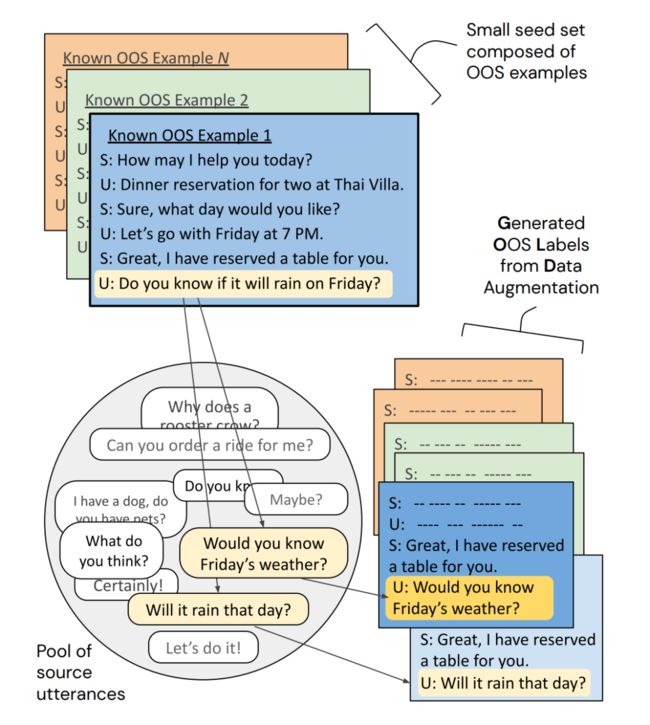
上图是 GOLD 增强数据的示意图。GOLD 通过从源数据集中提取话语并将这些句子与目标数据集中的已知 OOS 样本合并以生成伪标记的 OOS 示例来执行数据增强。
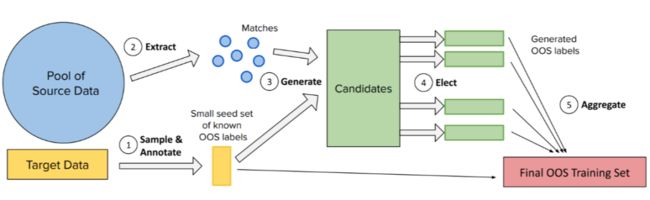
上图是完整的 GOLD 过程:(1)从未标记的目标数据中采样和注释一个小的种子集。(2) 从源数据集中提取相似匹配。(3) 通过将种子数据中的话语与匹配句子交换来生成候选词。(4) 选出最优秀的候选者成为伪标记的 OOS 示例。(5) 聚合所有选出的标签,形成最终的 OOS 训练集。

SPD

论文标题:
Detecting Speaker Personas from Conversational Texts
论文链接:
https://arxiv.org/abs/2109.01330
项目地址:
https://github.com/jasonforjoy/spd
角色 persona 对于对话响应预测很有用。然而,当前研究中使用的角色是预先定义的,很难在对话之前获得。为了解决这个问题,这篇文章研究了一项名为说话人角色检测(Speaker Persona Detection, SPD)的新任务,该任务旨在基于纯对话文本检测说话人角色。
在此任务中,从给定对话文本的候选人中搜索出最匹配的角色。这是一个多对多的语义匹配任务,因为 SPD 中的上下文和角色都由多个句子组成。这些句子之间的长程依赖和动态冗余增加了这项任务的难度。作者为 SPD 构建了一个数据集,称为 Persona Match on Persona-Chat(PMPC)。
此外,作者评估了通过分别连接两组句子以粗粒度建立的上下文到角色(context-to-persona, C2P)匹配网络的基线模型。并为此任务提出了话语到配置文件(utterance-to-profile, U2P)匹配网络。U2P 模型以精细的粒度运行,将上下文和角色都视为多个序列的集合。然后,对每个序列对进行评分,并通过聚合为上下文-角色对获得可解释的总分。评估结果表明,U2P 模型显着优于其基线模型。
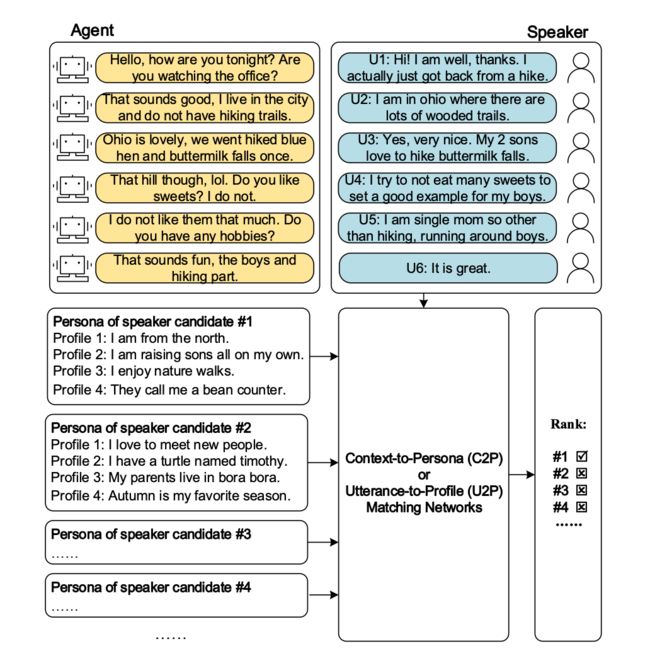
上图是 SPD 任务的示意图,匹配网络判断 persona 候选者是否与说话者的对话文本匹配。

上图是论文提出的 PMPC 数据集的数据规模。


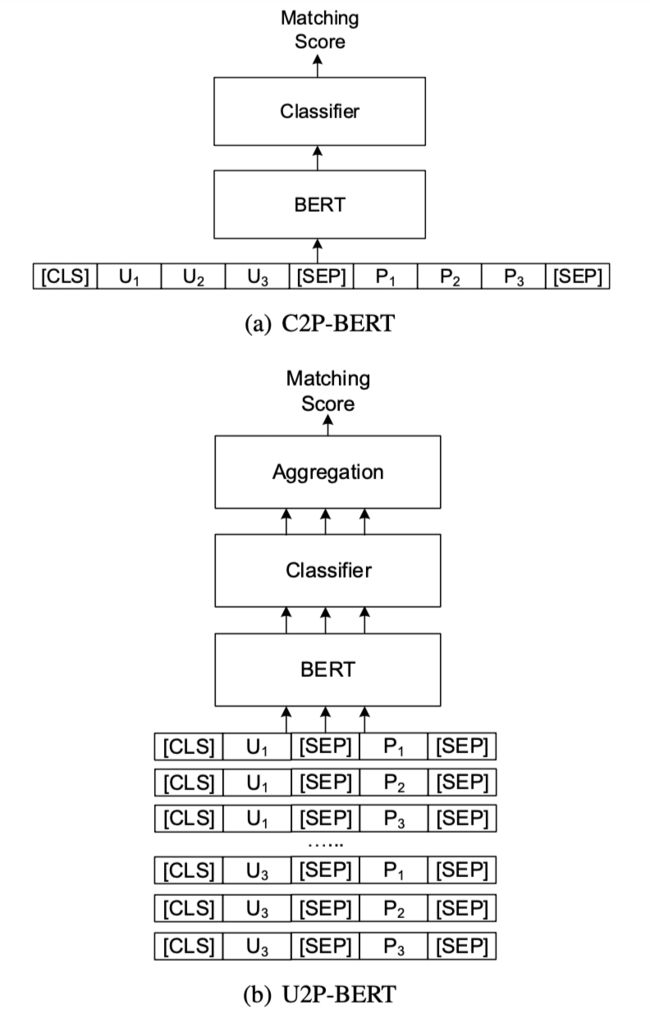
上图分别是 C2P、U2P 结合 BOW、transformer、ESIM、BERT 的模型架构。

CSA-NCT

论文标题:
Towards Making the Most of Dialogue Characteristics for Neural Chat Translation
论文链接:
https://arxiv.org/abs/2108.13990
这篇论文中中,作者从预训练目标以及上下文表示的格式的角度研究了 Seq2Seq 模型用于对话状态跟踪任务。作者证明了预训练目标的选择对状态跟踪质量有显着影响。特别是,掩码跨度预测比自回归语言建模更有效。
作者还探索将 Pegasus(一种基于跨度预测的文本摘要预训练目标)用于状态跟踪模型,结果显示,摘要任务的预训练对于对话状态跟踪也有很好的效果。此外,虽然循环状态上下文表示也能很好地工作,但模型可能很难从早期的错误中恢复过来。作者在 MultiWOZ 2.1-2.4、WOZ 2.0 和 DSTC2 数据集上进行了实验,观察结果一致。
论文中得出的发现如下:
涉及掩码跨度预测的预训练程序始终优于自回归语言建模目标。
摘要的预训练对于 DST 的效果出奇地好,尽管它似乎是一项无关紧要的任务。
通过包含先前预测的状态和恒定长度的对话历史,循环模型工作得相当好。然而,他们可能会遇到无法从早期错误中恢复的问题。

GME

论文标题:
Transferable Persona-Grounded Dialogues via Grounded Minimal Edits
论文链接:
https://arxiv.org/abs/2109.07713
落地对话模型生成基于某些概念的响应。受落地对话数据分布的限制,在此类数据上训练的模型在数据分布和落地概念类型方面面临可迁移性挑战。为了应对这些挑战,作者提出了基于给定概念的最小编辑框架,该框架最小化编辑现有响应。
专注于 persona,作者提出了落地最小编辑器(Grounded Minimal Editor, GME),它通过解耦和重新组合响应中与角色相关和与角色无关的部分来学习编辑。为了评估以角色为基础的最小编辑,作者引入了 PersonaMinEdit 数据集,实验结果表明 GME 大大优于 baseline。
为了评估可转移性,作者在 BlendedSkillTalk 的测试集上进行了实验,并表明 GME 可以编辑对话模型的响应,以在很大程度上提高他们的角色一致性,同时保留知识和同理心的使用。

上图是基于 persona 的最小编辑。

上图所示算法是 GME 的完整过程。在推理时,GME 首先通过屏蔽原始响应 中与角色相关的跨度来创建响应模板 ,然后将模板 、persona 和对话历史 重新组合成编辑后的响应 。设计模板来近似未观察到的变量 ,这将 GME 与以前基于检索的对话模型区分开来。再使用 来表示训练和推理的模板。
在训练期间,学习了两个模块:1)用于上述重组的生成器和;2)帮助在推理时创建响应模板的掩码分类器。注意,除了 persona 之外,GME 还可以应用于其他基本概念。

上图中,左边是训练示例和输入格式,右边是推理示例和输入格式。

DST-as-Prompting

论文标题:
Dialogue State Tracking with a Language Model using Schema-Driven Prompting
论文链接:
https://arxiv.org/abs/2109.07506
项目地址:
https://github.com/chiahsuan156/DST-as-Prompting
面向任务的对话系统通常使用对话状态跟踪来表示用户的意图,这涉及填充预定义槽的值,通常使用具有专用分类器的特定于任务的架构。最近,使用基于预训练语言模型的更通用的架构获得了良好的结果。
这篇文章,作者介绍了语言建模方法的一种新变体,它使用模式驱动的提示来提供用于分类和非分类槽的任务感知历史编码。我们通过使用模式描述(一种自然发生的域内知识来源)增强 prompting 来进一步提高性能。纯生成系统在 MultiWOZ 2.2 上实现 SOTA。

上图是多领域域场景的生成 DST 方法概述。前三张图说明了本文考虑的三种不同的生成方法,下图包括对话历史、域名、插槽名称、插槽的自然语言描述(类型、有效值集等)的具体示例。子图 (b)(c) 展示了提出的两个基于提示的 DST 模型,其中 (c) 中的方法包括考虑用于跟踪的插槽的额外自然语言描述。

Confirm-it

论文标题:
Looking for Confirmations: An Effective and Human-Like Visual Dialogue Strategy
论文链接:
https://arxiv.org/abs/2109.05312
在视觉对话任务中生成面向目标的问题是一个具有挑战性且长期存在的问题。最先进的系统被证明会产生问题,虽然语法上是正确的,但通常缺乏有效的策略,而且听起来对人类来说很不自然。受关于信息搜索和跨情境单词学习的认知文献的启发,作者设计了 Confirm-it,这是一个基于波束搜索重排序算法的模型,通过提出问题来确认模型对参照物的推测。将 GuessWhat?! 游戏作为案例研究,结果表明,Confirm-it 生成的对话比不重新排序的波束搜索解码更自然、更有效。

上图描述了 Confirm-it 使用的波束搜索重排序算法,以促进有效对话策略的生成。给定一个图像、一组候选对象、一个目标对象 和 B 的波束大小,在给定当前对话历史的每个对话回合中,模型预测候选对象集的概率分布。获得最高概率的候选者被认为是模型的假设 。QGen 输出 B 个问题,按概率排序。
这些问题中的每一个都由模型的内部 Oracle 回答,该 Oracle 接收 作为目标对象。在这 B 个问题中,Confirm-it 选择问题 Q,与内部 Oracle 提供的答案配对,增加模型对 的置信度,以 Guesser 分配的概率来衡量。外部 Oracle(知道真实目标对象 的人)回答 Q,并将这个新的问答对附加到对话历史中。

上图是 Confirm-it 的具体运作方式。

OneCommon

论文标题:
Reference-Centric Models for Grounded Collaborative Dialogue
论文链接:
https://arxiv.org/abs/2109.05042
项目地址:
https://github.com/dpfried/onecommon
在这篇文章中,作者提出了一个落地的神经对话模型,该模型在部分可观察的参考游戏中成功地与人们合作。基于一个设置,两个代理各自观察世界上下文的重叠部分,并且需要识别并商定他们共享的某个对象。因此,代理应该汇集他们的信息并准确地交流以解决任务。对话代理使用结构化参考解析器从合作伙伴的话语中准确地确定所指对象,使用循环记忆对这些所指对象设置条件,并使用实用的生成程序来确保合作伙伴能够解析代理产生的参考。
作者在 OneCommon 空间基础对话任务进行评估,其中涉及排列在板上的多个点,这些点的位置、大小和阴影不断变化。代理在任务方面的表现大大优于之前的技术水平,在自我对弈评估中成功完成任务的相对提高了 20%,在人类评估的成功上获得了 50% 的相对提高。

上图是本文的系统 (A) 与人类伙伴 (P) 生成的示例对话。参与者对共享板有不同但重叠的视图,其中包含不同形状和大小的点。合作伙伴必须通过对话进行协作,以便找到并选择一个对双方都可见的点。
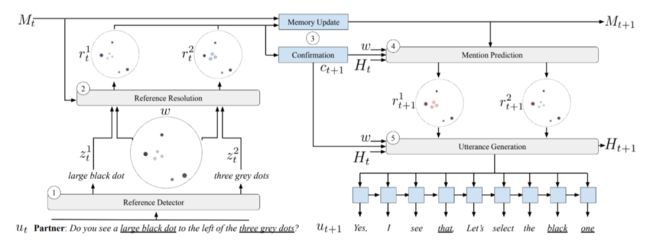
上图是模型的模块间的关系。在给定的回合中,代理首先使用参考检测器 (1) 识别其伙伴话语 中的参考表达。然后使用参考解析模块 (2) 解析每个参考,该模块使用参考段和世界上下文 的编码表示 。
然后使用所指对象来更新所指对象内存 ,并与代理自己的点进行交叉引用,以确认代理是否也可以看到它们(3)。给定所指内存 和确认变量 ,预测模块 (4) 生成一系列点配置 给参考。最后,话语生成模块 (5) 使用对话历史 、确认变量以及所选提及和世界上下文的参与表示来生成响应 。

上图是在对话系统的人工评估期间收集的示例对话。作者为每个系统展示了一个不成功(左)和一个成功(右)的例子。

ConDigSum

论文标题:
Topic-Aware Contrastive Learning for Abstractive Dialogue Summarization
论文链接:
https://arxiv.org/abs/2109.04994
项目地址:
https://github.com/Junpliu/ConDigSum
与新闻报道和百科全书文章等结构良好的文本不同,对话内容通常来自两个或多个对话者,彼此交换信息。在这种情况下,对话的主题可能会随着进展而变化,并且某个主题的关键信息通常分散在不同说话者的多个话语中,这对抽象地总结对话提出了挑战。
为了捕获对话的各种主题信息并概述捕获主题的显着事实,这篇文章提出了两个主题感知对比学习目标,即一致性检测和子摘要生成目标,它们有望隐式地对主题变化进行建模并处理对话摘要任务的信息分散挑战。提出的对比目标被设计为主要对话摘要任务的辅助任务,通过替代参数更新策略联合起来。大量实验表明,这篇文章所提出的简单方法明显优于 baseline,并实现了新的最先进性能。

上图是对话及其配对摘要的示例。、 和 分别代表参考主题片段、当前情况、到达时间和吃的食物。相应的摘要由三个句子 、 和 组成。每个 对应一个片段 (i = 1, 2, 3)。 和 是主题间片段。

上图是具有对比目标的模型结构。这项工作提出通过以对比的方式对话语连贯性进行建模来隐式捕获对话主题信息。构建连贯性检测目标是为了推动模型更多地关注更连贯且可能包含来自相同主题的显着信息的片段。此外,由于目标是为对话中的每个主题生成更好的摘要,作者还引入了小结生成目标,这有望迫使模型识别最显着的信息并生成相应的摘要。
请注意,这两个目标都是以对比方式构建的,不需要额外的人工注释或额外的算法。这两个对比目标可以通过交替参数更新策略与主要对话摘要任务相结合,从而形成最终模型 CONDIGSUM。

PCR

论文标题:
Exophoric Pronoun Resolution in Dialogues with Topic Regularization
论文链接:
https://arxiv.org/abs/2109.04787
项目地址:
https://github.com/hkust-knowcomp/exo-pcr
将代词解析为其所指对象长期以来一直被研究为一个基本的自然语言理解问题。以前关于代词共指解析(pronoun coreference resolution, PCR)的工作主要侧重于将代词解析为文本中的提及,而忽略了外部场景。
外显代词在日常交流中很常见,说话者可能会直接使用代词来指代环境中存在的某些物体,而无需先介绍物体。虽然对话文本中没有提到这些对象,但它们通常可以通过对话的一般主题来消除歧义。论文作者建议共同利用对话的本地上下文和全局主题来解决文本外 PCR 问题。大量实验证明了添加主题正则化以解析外显代词的有效性。

上图是在有(绿)和没有(红)对话主题的帮助下解决日常对话中的外显代词的例子。

上图是本文任务的一个例子。代词与其文本内和文本外的所指对象相关联,黄色是外显代词,绿色是内指代词。
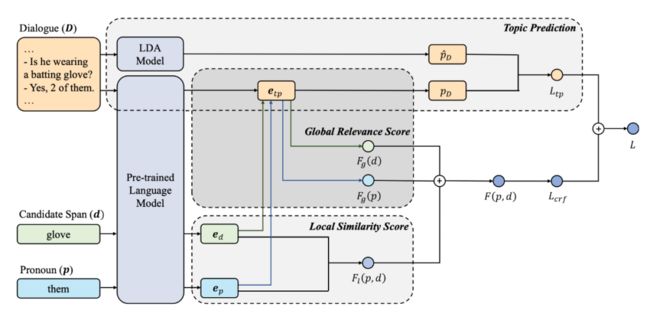
上图是这篇文章提出的模型,共包含三个主要组成部分:局部相似性得分计算、全局相关性得分计算和主题预测。局部评分模块根据它们的文本表示计算代词 p 和候选跨度 d 之间的相似性。全局评分模块衡量它们与全局对话主题的相关性。为了帮助主题嵌入更好地捕捉主题信息,主题预测模块使用对话嵌入来拟合 LDA 预测的主题向量作为辅助任务。

上图是文本外 PCR 的案例研究。目标代词(黄)和正确的文本外对象(绿)及其提示用不同的颜色标记。
·
·
