Hadoop 2.7 伪分布式环境搭建(超详细)
1、安装环境
①、一台Linux CentOS6.7 系统
hostname ipaddress subnet mask geteway
Node1 192.168.139.150 255.255.255.0 192.168.139.2
②、hadoop 2.7 安装包
下载地址:http://mirrors.hust.edu.cn/apache/hadoop/common/hadoop-2.7.3/
2、安装 JDK
配置Java和Hadoop的环境变量
需要在/etc/profile和./etc/hadoop/hadoop-env.sh(目前在hadoop目录下)这两个文件的末尾加入以下变量:
export JAVA_HOME=/usr/lib/jvm/java-8-openjdk-amd64
CLASSPATH=$CLASSPATH.:$JAVA_HOME/lib:$JAVA_HOME/jre/lib
export PATH=$PATH:$JAVA_HOME/bin:$JAVA_HOME/jre/bin
export HADOOP_HOME=/usr/local/hadoop
export HADOOP_COMMON_LIB_NATIVE_DIR=$HADOOP_HOME/lib/native
修改第一个文件就是修改当前的环境变量,修改第二个文件就是修改ssh后的环境变量。
这些就是Java和Hadoop的环境变量,加载了这些环境变量即可在命令行运行特定命令,现在重新加载这配置文件:
. /etc/profile如果是公用的服务器,需要修改自己的目录下的环境配置,可以使用vim ~/.bashrc ,添加上述环境变量后,在使用source ~/.bashrc使其生效
3、配置本机 ssh 免密码登录
创建hadoop用户
# 以root用户登录
su root
# 创建一个hadoop组下的hadoop用户,并使用 /bin/bash 作为shell
useradd -m hadoop -G hadoop -s /bin/bash
# useradd 主要参数
# -c:加上备注文字,备注文字保存在passwd的备注栏中。
# -d:指定用户登入时的启始目录
# -D:变更预设值
# -e:指定账号的有效期限,缺省表示永久有效
# -f:指定在密码过期后多少天即关闭该账号
# -g:指定用户所属的起始群组
# -G:指定用户所属的附加群组
# -m:自动建立用户的登入目录
# -M:不要自动建立用户的登入目录
# -n:取消建立以用户名称为名的群组
# -r:建立系统账号
# -s:指定用户登入后所使用的shell
# -u:指定用户ID号
# 设置hadoop用户密码,按提示输入两次密码
# 学习阶段可简单设为"hadoop",若提示“无效的密码,过于简单”,则再次输入确认即可
passwd hadoop可为hadoop用户增加管理员权限,避免一些对新手来说比较棘手的权限问题。
visudo
# 找到 root ALL=(ALL) ALL 这行
# 大致在第98行,可先按一下键盘上的ESC键,然后输入 :98
# 在这行下面增加一行内容 hadoop ALL=(ALL) ALL
## Allow root to run any commands anywhere
root ALL=(ALL) ALL
hadoop ALL=(ALL) ALL
保存退出后以刚才创建的hadoop用户登录
配置SSH免密码登录
集群、单节点模式都需要用到 SSH 登陆,一般情况下,CentOS 默认已安装了 SSH client、SSH server,打开终端执行如下命令进行检验,查看是否包含了SSH client跟SSH server
[hadoop@iZwz9b62gfdv0s2e67yo8kZ hadoop]$ rpm -qa | grep ssh
libssh2-1.4.2-2.el6_7.1.x86_64
openssh-5.3p1-118.1.el6_8.x86_64
openssh-clients-5.3p1-118.1.el6_8.x86_64
openssh-server-5.3p1-118.1.el6_8.x86_64如果不包含,可以通过yum进行安装
sudo yum install openssh-clients
sudo yum install openssh-server测试下ssh是否可用
# 按提示输入密码hadoop,就可以登陆到本机
ssh localhost但这样登陆是需要每次输入密码的,我们需要配置成SSH无密码登陆比较方便。
首先输入 exit 退出刚才的 ssh,就回到了我们原先的终端窗口。
然后利用 ssh-keygen 生成密钥,并将密钥加入到授权中。
# 退出刚才的 ssh localhost
exit
# 若没有该目录,请先执行一次ssh localhost
cd ~/.ssh/
# pwd查看当前目录,应为"/home/hadoop/"
# ~ 代表的是用户的主文件夹,即 “/home/用户名” 这个目录
# 会有提示,都按回车就可以
ssh-keygen -t rsa
cat id_rsa.pub >> authorized_keys
chmod 600 ./authorized_keys此时再用 ssh localhost 命令, 无需输入密码就可以直接登陆了
[hadoop@iZwz9b62gfdv0s2e67yo8kZ .ssh]$ ssh localhost
Last login: Wed Feb 20 22:29:22 2017 from 127.0.0.1
Welcome to Alibaba Cloud Elastic Compute Service !
[hadoop@iZwz9b62gfdv0s2e67yo8kZ ~]$ exit
logout
Connection to localhost closed.
[hadoop@iZwz9b62gfdv0s2e67yo8kZ .ssh]$
4、安装 hadoop-2.7.3.tar.gz
①、将下载的 hadoop-2.7.3.tar.gz 复制到 /home/hadoop 目录下(可以利用工具 WinSCP)
②、解压,进入/home/hadoop 目录下,输入下面命令
| 1 |
|
③、给 hadoop-2.7.3文件夹重命名,以便后面引用
| 1 |
|
④、删掉压缩文件 hadoop-2.7.3.tar.gz,并在/home/hadoop 目录下新建文件夹 tmp
| 1 |
|
⑤、配置 hadoop 的环境变量(注意要使用 root 用户登录)同样可以配置到~/.bashrc里面
| 1 |
|
输入如下信息:

然后输入如下命令保存生效:
| 1 |
|
⑥、验证
在任意目录下,输入 hadoop,出现如下信息即配置成功

5、修改配置文件
①、/home/hadoop/hadoop-2.7.0/etc/hadoop目录下hadoop-env.sh
输入命令
![]()
修改 hadoop-env.sh 的 JAVA_HOME 值
![]()
②、/home/hadoop/hadoop2.7/etc/hadoop目录下的core-site.xml
注意下面第八行包含了hadoop目录信息,一定要改成你自己的
![]()
| 1 2 3 4 5 6 7 8 9 10 |
|
③、/home/hadoop/hadoop-2.7.0/etc/hadoop目录下的hdfs-site.xml
注意下面有两行代码包含了hadoop目录信息,一定要改成你自己的
![]()
dfs.replication
1
dfs.namenode.name.dir
file:/usr/local/hadoop/tmp/dfs/name
dfs.datanode.data.dir
file:/usr/local/hadoop/tmp/dfs/data
到此我们便配置完成一个 hdfs 伪分布式环境
启动 hdfs Single Node
①、初始化 hdfs 文件系统
| 1 |
|
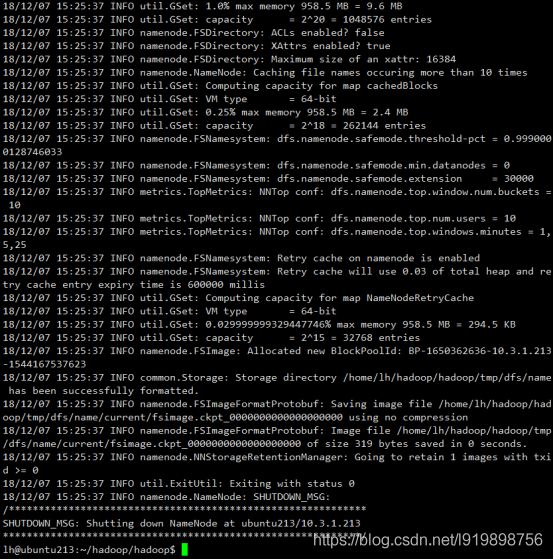
②、启动 hdfs
| 1 |
|
③、输入 jps 应该会有如下信息显示,则启动成功

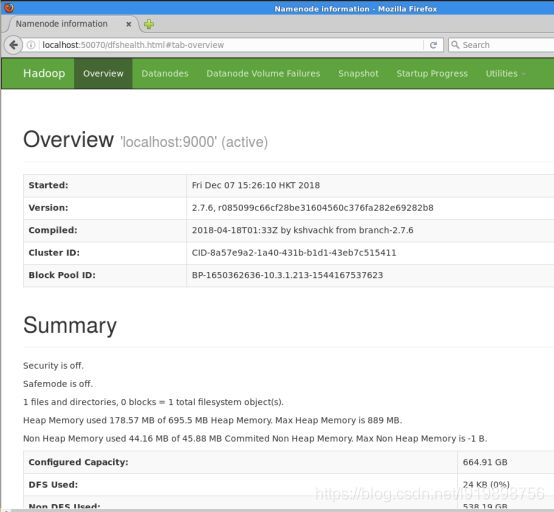
那么我们就可以 通过 http://localhost:50070 来访问 NameNode
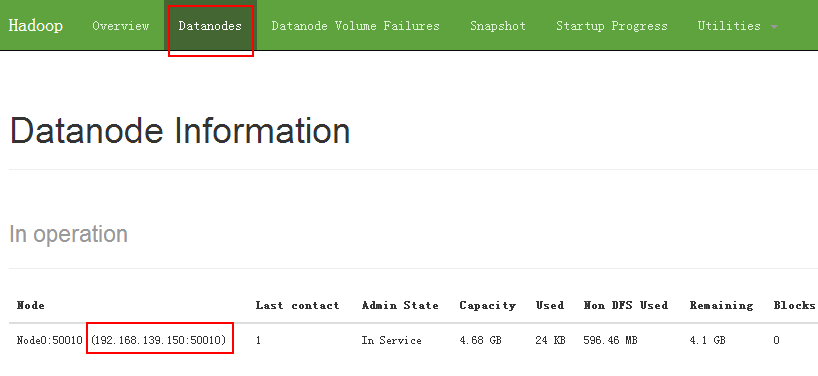
我们点开 Datanodes ,发现就一个 datanode ,而且 IP 是 NameNode 的
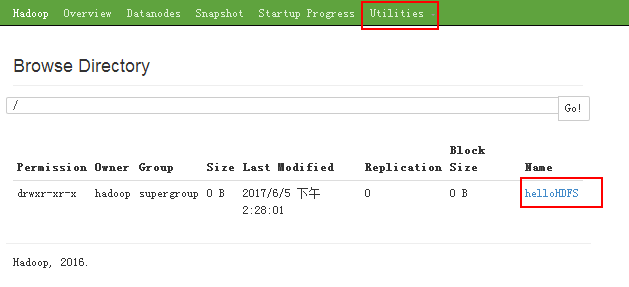
我们使用命令创建一个文件
![]()
那么在网页上我们就能看到这个文件
④、关闭 hdfs
| 1 |
|
运行例子
命令查看
可以通过./bin/hdfs dfs -help命令来查看使用方法:
在 HDFS 中创建用户目录
先通过./bin/hdfs dfs -mkdir -p /user/hadoop命令创建一个用户目录
例子一 解析配置文件
本次实验可以就地取材,选择hadoop的配置文件为材料,使用伪分布式hadoop平台来解析。先用put命令把配置文件都放入hdfs的一个新建文件夹input:
./bin/hdfs dfs -mkdir /user/hadoop/input
./bin/hdfs dfs -put ./etc/hadoop/*.xml /user/hadoop/input/
./bin/hdfs dfs -ls input
然后运行例子,解析input里面的配置文件,并将解析结果放入output文件夹:
./bin/hadoop jar ./share/hadoop/mapreduce/hadoop-mapreduce-examples-*.jar grep /user/hadoop/input/* /user/hadoop/output 'dfs[a-z.]+'
把output里面的解析结果通过cat命令输出:
./bin/hdfs dfs -cat /user/hadoop/output/*
把output里面的解析结果从hdfs中取出(这个操作是常用的,尽管在伪分布式里面没什么意义,但是在真实环境下特别有用):
./bin/hdfs dfs -get /user/hadoop/output ./output
例子二 WordCount
wordcount是一个hadoop内置的范例程序,用于统计单词数量。
首先,要删除例子一留下的实验痕迹:
./bin/hdfs dfs -rm -r -f /user/hadoop/output /user/hadoop/input
然后和实验一一样,创建hadoop的输入文件夹,同时就地取材一个可读文件:
./bin/hdfs dfs -mkdir /user/hadoop/input
./bin/hdfs dfs -put LICENSE.txt /user/hadoop/input/LICENSE.txt
./bin/hdfs dfs -ls /user/hadoop/input
运行例子,结果放置在output文件夹:
./bin/hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-2.8.0.jar wordcount /user/hadoop/input /user/hadoop/output
./bin/hdfs dfs -cat /user/hadoop/output/*
可以看到,屏幕是被刷了好几遍,因为输出太多了,我们可以统计一下输出了有多少行:
./bin/hdfs dfs -cat /user/hadoop/output/* | wc -l