单机版 Hadoop 安装经验笔记
目录
- 硬件条件
- 安装Java
-
- JDK下载
- 文件上传
- 解压
- 配置环境变量
- 检测是否安装成功
- 安装Hadoop
-
- Hadoop下载
- 文件上传、解压
- 配置环境变量
- 修改配置文件
-
- 1、修改core-site.xml
- 2、修改 hadoop-env.sh
- 3、修改 hdfs-site.xml
- 4、修改 mapred-site.xml
- 5、修改 yarn-site.xml
- 格式化 hadoop 文件
- 启动 Hadoop 、查看安装情况
- Hadoop 任务监控
- 总结
硬件条件
本篇笔记所使用的操作系统是安装在VMware Workstation15.5 pro的Ubuntu18.04-server(64位)
操作系统分配4GB内存和100G硬盘存储空间。系统安装的流程不做过多赘述。
操作流程使用到了xhell6和xftp6 目前这两款软件都有家庭/学生版供免费下载,没必要去下盗版软件
下载链接:
https://www.netsarang.com/en/free-for-home-school/
安装Java
JDK下载
选择了JDK1.8在2020年更新的8U251版本,应该目前已经更新到8U281了
下面给出下载链接:
https://www.oracle.com/java/technologies/javase/javase-jdk8-downloads.html
文件上传
使用xftp6将下载好的文件上传至Ubuntu下的指定路径当中:
我常使用 /opt 作为软件安装路径

解压
解压到当前路径下:
# 解压缩
tar -zxvf jdk-8u251-linux-x64.tar.gz解压完成后的截图

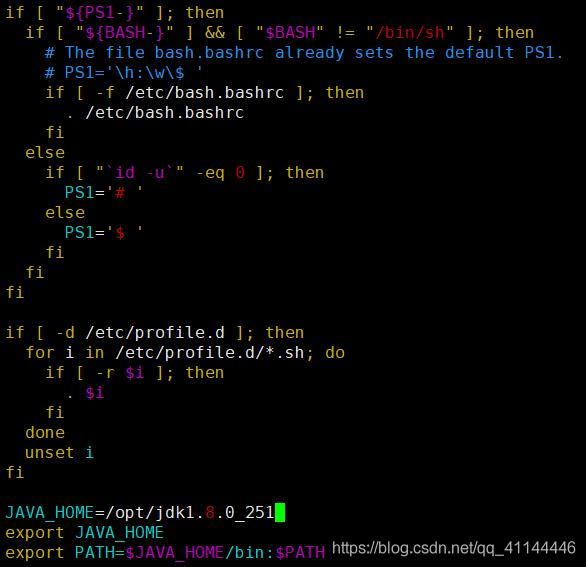
配置环境变量
cd /etc/
vi profile添加如下语句:
# Here is the Java Environment
JAVA_HOME=/opt/jdk1.8.0_251
export JAVA_HOME
export PATH=$JAVA_HOME/bin:$PATH添加完成截图
刷新环境变量配置
source /etc/profile检测是否安装成功
输入指令查看Java版本
java -version如下图所示,则安装完成,可以开始安装Hadoop

安装Hadoop
Hadoop下载
目前最新的Hadoop2版本应该是2.10.1,3版本也更新到了3.3.0。
下载路径:https://hadoop.apache.org/releases.html
文件上传、解压
使用xftp上传压缩包
# 解压文件
tar -zxvf hadoop-2.9.2.tar.gz解压完成后

配置环境变量
和前面安装JDK流程一样
cd /etc/
vi profile添加如下语句:
# Here is the Hadoop Environment
export HADOOP_HOME=/opt/hadoop-2.9.2
export PATH=$HADOOP_HOME/bin:$PATH添加完成截图

刷新配置信息
source /etc/profile查看版本
hadoop version如下图所示,则可进行下一步

修改配置文件
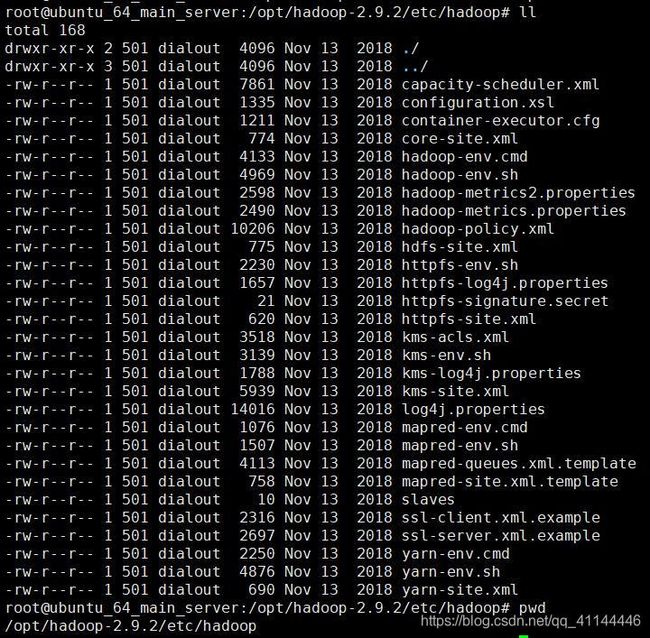
进入hadoop配置文件存储路径
cd /opt/hadoop-2.9.2/etc/hadoop路径下的文件如图:
1、修改core-site.xml
在
vi core-site.xml<configuration>
<property>
<name>fs.defaultFSname>
<value>hdfs://192.168.189.133:9000value>
property>
<property>
<name>hadoop.tmp.dirname>
<value>/opt/hadoop-2.9.2/Worksparcevalue>
property>
<property>
<name>hadoop.native.libname>
<value>falsevalue>
<description>
Should native hadoop libraries, if present, be used.
description>
property>
configuration>以上参数分别是设置:
fs.defaultFS:默认文件系统的名称
hadoop.tmp.dir:临时文件的基路径
hadoop.native.lib:是否使用本地库
配置好后截图如下

2、修改 hadoop-env.sh
配置JDK安装路径:
vi hadoop-env.shexport JAVA_HOME=/opt/jdk1.8.0_251添加完成后截图

3、修改 hdfs-site.xml
vi hdfs-site.xml在
<configuration>
<property>
<name>dfs.replicationname>
<value>1value>
property>
<property>
<name>dfs.secondary.http.addressname>
<value>192.168.189.133:50090value>
property>
configuration>以上参数分别是设置:
dfs.replication:上传文件的副本数量
dfs.secondary.http.address:HTTP状态监控地址
配置完成后截图

4、修改 mapred-site.xml
vi mapred-site.xml添加如下内容
<configuration>
<property>
<name>mapreduce.framework.namename>
<value>yarnvalue>
property>
configuration>以上参数分别是设置:
mapreduce.framework.name:使用什么执行MapReduce任务(默认local)
配置完成后截图

5、修改 yarn-site.xml
vi yarn-site.xml添加如下内容
<configuration>
<property>
<name>yarn.resourcemanager.hostnamename>
<value>192.168.189.133value>
property>
<property>
<name>yarn.nodemanager.aux-servicesname>
<value>mapreduce_shufflevalue>
property>
configuration>以上参数分别是设置:
yarn.resourcemanager.hostname:RM主机名
yarn.nodemanager.aux-services:NodeManager上运行的附属服务。需配置成mapreduce_shuffle,才可运行MapReduce程序
该配置文档的全部参数可参考
配置完成后截图

格式化 hadoop 文件
执行指令
切记以下指令仅可执行一次,执行两次及以上将导致集群出现问题
cd /opt/hadoop-2.9.2/sbin/
hadoop namenode -format启动 Hadoop 、查看安装情况
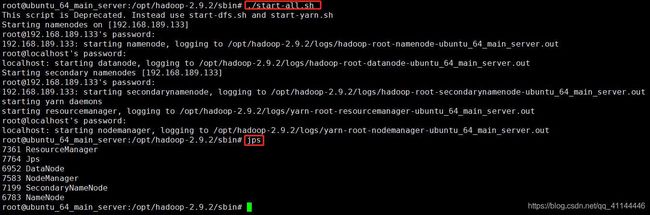
执行指令:
cd /opt/hadoop-2.9.2/sbin/
# start-all.sh相当于`start-dfs.sh`+`start-yarn.sh`
./start-all.sh初次执行会输入几次密码
可能出现输密码无论如何提示permission denied
我出现这个问题是更改 该文件夹权限 解决的(需要root)
cd /opt/hadoop-2.9.2/sbin/
chmod 777 ./最后使用经典Hadoop安装检查指令
jps如果出现以下六个进程则证明安装成功。
Hadoop 任务监控
如果在虚拟机安装时采用桥接NAT网络适配器模式的话,可以在本机脱网的情况下连接虚拟机监控任务执行情况和存储空间分配情况,IP使用虚拟机的网络地址,端口号默认50090
使用网址:192.168.189.133:50090
看到如下界面的话,单机版 hadoop就已经安装并启动成功了

总结
该笔记中使用的所有软件都是直接从开源官网中下载的,如果遇到下载速度问题,可以使用国内的开源镜像站进行下载。
参考:
1、https://blog.csdn.net/lu1171901273/article/details/86518494