前言
- 本篇是关于 MIT 6.S081-2020-Lab6(Copy-on-Write Fork for xv6) 的实现;
- 如果内容上发现有什么问题请不要吝啬您的键盘。
准备工作
先大概罗列一下实现 cow-fork 所要做的工作清单:
- 修改 uvmcopy() 函数;【√】
- 修改 copyout() 函数,因为它是直接对 pa 进行读写的;【√】
为 usertrap 函数添加处理 cow page write 的异常;【√】
- 可以将 2 和 3 两个处理 cow page 的逻辑提取出来。
- 在 kalloc.c 中维护一个 references 的引用数组,references[i] 代表第 i 个 page 被引用的次数。先是初始化 references 数组、再是为分配、释放 page 时,添加对 references 数组的操作。【√】
注意:
- kalloc() 后 out of memory 时,kill 整个 process;【√】
- It may be useful to have a way to record, for each PTE, whether it is a COW mapping.【√】
Implement copy-on write
先在添加维护 references 数组的代码:
/* kernel/kalloc.c */
int references[PA2IDX(PHYSTOP)];
struct spinlock r_lock;
void
kinit()
{
initlock(&kmem.lock, "kmem");
initlock(&r_lock, "refereces");
memset(references, 0, sizeof(int)*PA2IDX(PHYSTOP));
freerange(end, (void*)PHYSTOP);
}
void
kfree(void *pa)
{
struct run *r;
if(((uint64)pa % PGSIZE) != 0 || (char*)pa < end || (uint64)pa >= PHYSTOP)
panic("kfree");
if (reference_remove((uint64)pa) > 0)
return;
references[PA2IDX(pa)] = 0;
// Fill with junk to catch dangling refs.
memset(pa, 1, PGSIZE);
r = (struct run*)pa;
acquire(&kmem.lock);
r->next = kmem.freelist;
kmem.freelist = r;
release(&kmem.lock);
}
void *
kalloc(void)
{
struct run *r;
acquire(&kmem.lock);
r = kmem.freelist;
if(r) {
references[PA2IDX(r)] = 1;
kmem.freelist = r->next;
}
release(&kmem.lock);
if(r)
memset((char*)r, 5, PGSIZE); // fill with junk
return (void*)r;
}
int
reference_find(uint64 pa)
{
return references[PA2IDX(pa)];
}
int
reference_add(uint64 pa)
{
int ref;
acquire(&r_lock);
ref = ++references[PA2IDX(pa)];
release(&r_lock);
return ref;
}
int
reference_remove(uint64 pa)
{
int ref;
acquire(&r_lock);
ref = --references[PA2IDX(pa)];
release(&r_lock);
return ref;
}
再是添加处理 cow 异常中断的函数,这个函数将会在 copyout() 函数和 usertrap() 函数中被共同调用:
/* kernel/trap.c */
int
cow_handle(pagetable_t pagetable, uint64 va)
{
va = PGROUNDDOWN(va);
if(va >= MAXVA)
return -1;
pte_t *pte;
if ((pte = walk(pagetable, va, 0)) == 0)
return -1;
if ((*pte & PTE_V) == 0)
return -1;
if ((*pte & PTE_COW) == 0)
return 1;
char *n_pa;
if ((n_pa = kalloc()) != 0) {
uint64 pa = PTE2PA(*pte);
memmove(n_pa, (char*)pa, PGSIZE);
*pte = PA2PTE(n_pa) | ((PTE_FLAGS(*pte) & ~PTE_COW) | PTE_W);
kfree((void*)pa);
return 0;
} else {
return -1;
}
}/* kernel/trap.c */
void
usertrap(void)
{
...
syscall();
} else if (r_scause() == 13 || r_scause() == 15) {
uint64 va = r_stval();
if (va >= p->sz || cow_handle(p->pagetable, va) != 0)
p->killed = 1;
} else if((which_dev = devintr()) != 0){
...
}/* kernel/vm.c */
int
copyout(pagetable_t pagetable, uint64 dstva, char *src, uint64 len)
{
...
va0 = PGROUNDDOWN(dstva);
if (cow_handle(pagetable, va0) < 0)
return -1;
pa0 = walkaddr(pagetable, va0);
...
}最后就是在 fork() 函数调用 uvmcopy() 的代码:
/* kernel/vm.c */
int
uvmcopy(pagetable_t old, pagetable_t new, uint64 sz)
{
pte_t *pte;
uint64 va, pa;
for (va = 0; va < sz; va += PGSIZE) {
if ((pte = walk(old, va, 0)) == 0)
panic("uvmcopy: pte should exist");
if((*pte & PTE_V) == 0)
panic("uvmcopy: page not present");
pa = PTE2PA(*pte);
if (*pte & PTE_W)
*pte = (*pte | PTE_COW) & ~PTE_W;
if(mappages(new, va, PGSIZE, pa, (uint)PTE_FLAGS(*pte)) < 0)
goto err;
reference_add(pa);
}
return 0;
err:
uvmunmap(new, 0, va / PGSIZE, 1);
return -1;
}后记
以下是记录了我从开始理解实验内容后,到通过 usertests 的完整踩坑历程:
for (int i = 0; i < 512; i++)
new[i] = old[i];如果用上面这样的形式拷贝 user memory,无论是分配还是释放进程内存时,不仅要考虑 page 的引用,还要考虑 pagetable 的引用。虽然能够节约许多 pagetable 所占用的空间,但是太复杂了,想了半天放弃了。
所以,为了简单起见,这里就选择 mappages 函数来实现。因为如果系统内连分配进程页表的内存空间都没有了,那么离内存完全耗尽也就不远了,早si晚si都得si (bushi
要想过 cowtest,只需把大体的逻辑给正确地写出来就能过了。
问题是要想过 usertests,就需要一些数据合法性的处理,尤其是在处理 cow 中断异常那块儿,但基本仿照 walkaddr() 函数的处理逻辑就能过关。
顺带一提,测试 usertests 时,test sbrkbugs 就是会产生 panic,不要认为是测试挂了……
在 usertests 的最后,输出了 FAILED -- lost some free pages 31928 (out of 31937)。这时要想找出来这一两个 pages 没有被回收的原因是比较困难的。
debug 的过程是颇为痛苦,我一度以为是因为我分配和释放 page 时的逻辑不对。但观察到两个 usertests 输出的 lost free pages 的数量有时是一个,有时是两个。这让我想到了可能是我没有对引用数组的增删操作加锁有关,于是随即加上了自旋锁测了下 usertests,发现还是挂了一个 sbrkfail,并且只有这一个测试点挂掉了,把 sbrkfail 注释掉了之后发现能完整地通过 usertests,没有出现 lost free pages 的问题(并且此时不加锁就会又出现 lost free pages 的问题),证明至少加锁的这个思路是对的。
之前没加锁的时候,sbrkfail 还是能通过的,加锁后又不能了,但锁还是要加的,因此就看上锁和释放锁的时机对不对了。举个例子,从 ++references[i] 到 return references[i] 这两条语句之间,用可能有别的父子进程去在对 references[i] 进行操作,因此我把改变后的引用数用一个 ref 变量保存了下来。这次终于通过了所有的 usertests。最后贴一个通过 make grade 的截图(虽然不知道为什么 usertest 超时了也给全分):
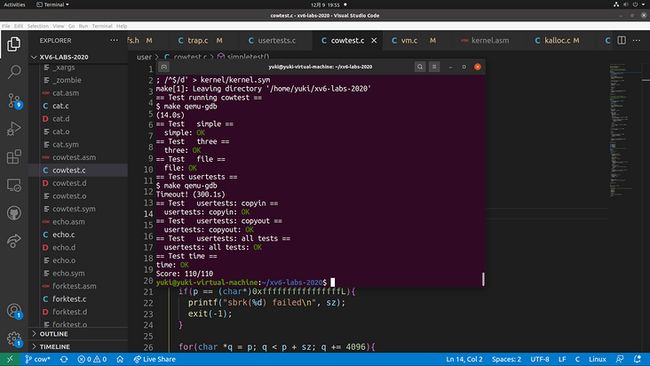
总的来说,因为自己还没学到锁,提示也没给,所以没往那儿多想,踩了个大坑。
优化的空间很明显还是有的:
- 速度上,可以把
cow_handle()中,检验 va 的合法性的代码搬到函数调用处去,因为否则在copyout中,同一个的 va 将会在copyout()和cow_handle()中 walk 页表两次,没有必要。 - 空间上,就不要在全局开一个
PA2IDX(PHYSTOP)这么大的 references 数组了,开一个长度是PA2IDX(PHYSTOP-KERNBASE)的足矣,因为一个进程实际物理地址空间大小不会超过PHYSTOP-KERNBASE。
太菜了,在回家放假前再做一篇多线程的实验的可能性微存(?