DML 语句
DML(Data Manipulation Language)语句:数据操纵语句。
用途:用于添加、修改、删除和查询数据库记录,并检查数据完整性。
常用关键字:insert、update、delete、select等。
DML 操作的对象是库表的数据(记录)。
主要包括插入(insert)、更新(update)、删除(delete)和查询(select)。
DML 语句是开发人员使用最频繁的操作。
1.插入记录
插入一条记录
insert into tablename (field1,field2,...,fieldn) values (value1,value2,...,valuen);
一次性插入多条数据
insert into tablename (field1,field2,...,fieldn) values (value1,value2,...,valuen), (value1,value2,...,valuen);
2.更新记录
更新单表数据
update tablename set field1=value1,filed2=value2,...fieldn=valuen [where condition]
同时更新多个表的数据
update t1,t2,...,tn set t1.field1=expr1,tn.field=exprn [where condition];
通常用于根据一个表的字段来动态地更新另外一个表的字段
在此说明:中括号 “[ ]” 代表的是可选参数,即可有可无的参数。
3.简单查询记录
简单的条件查询。符号“*”代表查询所有字段,如果只想看其中某些列,则写表的列名。
select * from tablename [where condition]; select field1,field2,...,fieldn from tablename [where condition];
别名
给列名或表名取别名的关键字:AS 或者不写关键字。如:
select field1 AS f1,field2 f2 from tablename; select t2.field1 AS f1,t1.field2 f2 from table1 as t1,table2 t2;
不取别名,则查询结果的列名为表原本的列名;
取别名,则查询结果的列名为别名

4.删除记录
删除单表记录
delete from tablename [where condition];
同时删除多个表的数据
delete t1,t2,...,tn from t1,t2,...,tn [where condition];
说明:不加where 条件则删除全表数据
单表“增改查删”操作案例:

多表“删除”操作案例:

再看个删除案例

最后再看个删除案例
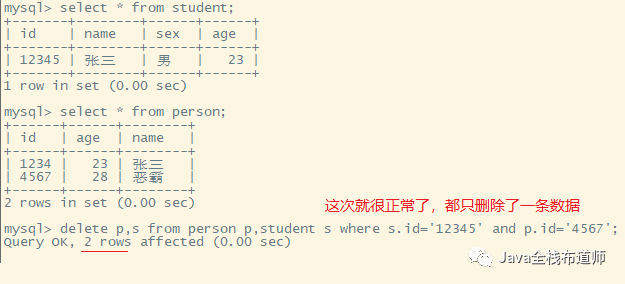
多表删除结论:
条件成立,则删除有条件表的对应数据,没条件的则全表删除;
条件不成立,则都不删除。
留个疑问:多表删除不给where 条件会怎样呢?
关于同时更新多个表数据的操作,可以自行探索,毕竟有思考的学习最有价值。
5.查询记录详解(DQL语句)
DQL(Data Query Language)即数据库查询语言。
数据库查询语句就像玩积木一样,一块一块的拼凑,每个中括号“[]”代表一块积木。
先通过递进的方式一条一条列出查询语法。
5.1.查询不重复的记录
select distinct filed from tablename;
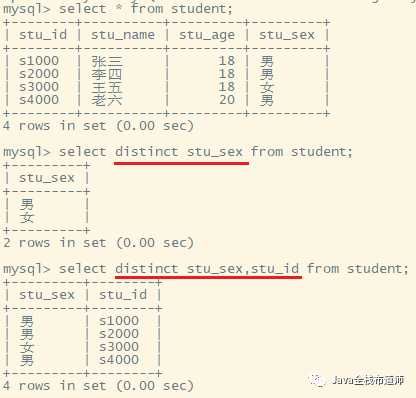
distinct 关键字是对 “查询结果集” 去重,再看个例子就明白了。

5.2.条件查询
--查询所有列: select * from tablename [where condition]; --查询指定列: select [field1,field2,...,fieldn] from tablename [where condition];
常用的条件(condition)
等于:field = xxx
大于:field > xxx
小于:field < xxx
不等于:field != xxx
不等于:field <> xxx
等于null:field is null
不等于null:field is not null
多个条件之间用逻辑运算符:and 和 or
模糊查询之"_":field like _x_xx_ 符号"_"代表匹配单个任意字符,可以在你喜欢的字符旁加上"_"
模糊查询之"%":field like %x%xx% 符号"%"代表匹配0~n个任意字符,可以在你喜欢的字符旁加上"%"
in语句查询:field in(value1,value2,...) 查询field 和 in 数组配得上的,不配就没有数据
not in语句查询:field not in(value1,value2,...) 查询field 和 in 数组配不上的,不配就有数据
其它常用条件具体怎么用,参考常用条件去操作。

5.3.聚合查询
--最简单的聚合查询: select [field1,field2,...,fieldn] fun_name from tablename group by field; --完整语法: select [field1,field2,...,fieldn] fun_name from tablename [where condition] [group by field1,field2,...,fieldn [with rollup]] [having condition];
说明:
fun_name 表示聚合函数,常用有:求和sum()、记录数count(*)、平均值avg()、最大值max()、最小值min();
[where condition] 就是上面讲的条件查询;
[group by field1,field2,...,fieldn [with rollup]]
group by 关键字表示对field字段进行分类聚合;
with rollup 关键字表示是否对分类聚合后的结果进行再汇总
[having condition] 对分类聚合后的查询结果集进行条件的过滤
where 和 having 的区别:
- where 是分组前的条件过滤;having 是分组后的条件过滤。
- where 是用原表列名做条件过滤;having 是用查询结果集列名做条件过滤。
优先选择where 条件过滤,这样可以减少结果集,进而提高分类聚合的效率。
中括号"[]"代表可选的意思,也就是说group by 前面的[where condition] 可有可无,后面的[with rollup] 和 [having condition] 也是可有可无。
group by 和distinct 的区别: group by 是对指定列进行分组;distinct 是对查询结果进行去重。

加入where 和 having的例子:

列名为avg(stu_age) 看着有点怪怪,给他取个别名就一目了然:

5.4.排序查询
--最简单的排序查询: select * from tablename order by field; --完整语法: select [field1,field2,...,fieldn] fun_name from tablename [where condition] [group by field1,field2,...,fieldn [with rollup]] [having condition] [order by field1 [desc|asc], field2 [desc|asc],...,fieldn [desc|asc]]; DESC 代表降序(从大到小);ASC 代表升序(从小到大),asc为默认排序。也就是说你只要记住desc 就可以了。碰巧的是desc 是查询表设计的关键字,而且语法很简单:desc tablename;
单列排序:

多列排序:用符号 “,” 隔开即可

5.5.limit查询
又称为限制查询、范围查询、分页查询
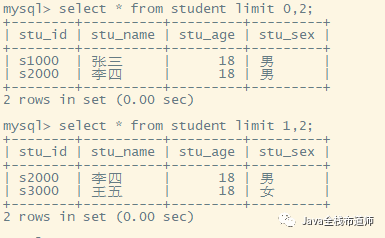
--最简单的limit查询:offset_start和数组下标一样,从0开始算 select * from tablename limit offset_start,row_count; --完整语法:这条sql是单表查询的完整版 select [field1,field2,...,fieldn] fun_name from tablename [where condition] [group by field1,field2,...,fieldn [with rollup]] [having condition] [order by field1 [desc|asc], field2 [desc|asc],...,fieldn [desc|asc]] [limit offset_start,row_count];
例子1:从第1条开始,查询两条数据
例子2:从第2条开始,查询两条数据
=========================
= 以上就是关于单表查询的语法 =
= 以下则是关于两表联查的语法 =
=========================
5.6.连表查询
在需要关联多个表数据时使用。 学习左连接和内连接即可。
左连接:选出左表所有的记录,不管右表有没有和它匹配;左表是主,关联右表信息
select * from t1 left join t2 on t1.field1=t2.field2;
内连接:仅选出两张表中互相匹配的记录,没有匹配则结果为空
select * from t1 inner join t2 on t1.field1=t2.field2; select * from t1,t2 where t1.field1=t2.field2;

5.7.子查询
在需要另外一个查询结果作为查询条件时使用。子查询用“()” 括起来。
如:查询学生“张三”的成绩

某些情况下,子查询可以转化为连表查询。如上面的例子可以写成连表查询:

5.8.记录联合
将两个过多个表的查询结果合并成结果集输出。合并的条件是多个表的查询结果字段数要相同,注意是查询结果字段数不是表字段数。
select f1,f2,...,fn from t1 union/union all select f1,f2,...,fn from t2 ... union/union all select f1,f2,...,fn from tn
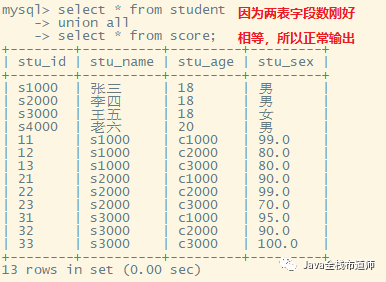
查询结果字段数不等,则报错
![]()
固定查询结果集字段数

5.9.select语句的执行顺序
自行证明该执行顺序是否正确,也算是对前面所学知识的一个巩固。
(7) SELECT
(8) DISTINCT
(1) FROM
(3)
JOIN (2) ON
(4) WHERE
(5) GROUP BY
(6) HAVING
(9) ORDER BY
(10) LIMIT
6.总结
到此为止,关于日常操作最为频繁的表数据的插入(insert)、更新(update)、删除(delete)和查询(select)语句就讲完了。最为繁杂的查询语句,又名为DQL语句,是DML语句中的重点。
到此这篇关于MySQL基础教程之DML语句的文章就介绍到这了,更多相关MySQL基础之DML语句内容请搜索脚本之家以前的文章或继续浏览下面的相关文章希望大家以后多多支持脚本之家!