

在本篇博文中,我们将详细介绍如何使用 Amazon Cloud Formation 与 Amazon Neptune 重建亚马逊云科技 COVID-19知识图谱(简称CKG),以及如何在亚马逊云科技账户中使用托管在 Amazon SageMaker 上的 Jupyter notebook。COVID-19 知识图谱能够帮助我们探索并分析托管在亚马逊云科技 COVID-19 数据湖中的 COVID-19 开放研究数据集(CORD-19)。该图谱的强度,由学术文献、作者、科学概念以及各机构间的关联决定。此外, COVID-19 知识图谱还为 CORD-19 的搜索页面提供技术基础。
亚马逊云科技 COVID-19 数据湖是一套公共集中存储库,其中容纳着关于新型冠状病毒(SARS-CoV-2)及其相关疾病 COVID-19 的传播、特征与其他公开信息的最新数据集。关于更多详细信息,请参阅用于 COVID-19 数据分析的公开数据湖以及探索亚马逊云科技 COVID-19 公开数据湖。
COVID-19 知识图谱由 Amazon Neptune、CORD-19 数据集以及来自 Amazon Comprehend Medical 提供的注释共同构建而成。截至2020年4月17日,CORD-19 数据集中共包含超过52000篇学术文献,其中41000篇为全文收录。这些数据来自多个渠道,包括 PubMed、bioArxiv 以及 medRxiv 等。在艾伦人工智能研究所与研究行业的密切合作之下,数据集规模仍在持续增长,信息规范化与数据质量改善工作也在稳步推进。这套数据集涉及多个学科,主要涵盖病毒学、转化医学以及流行病学层面的统计数据。

想要了解更多亚马逊云科技最新技术发布和实践创新,敬请关注在上海、北京、深圳三地举办的2021亚马逊云科技中国峰会!点击图片报名吧~上海站峰会已经圆满落幕,更多精彩内容,敬请期待北京、深圳分会吧!
图结构
COVID-19 知识图谱属于有向图。下表总结了其中各节点与边之间的关系。各有向边以指定的边权重从源节点指向目标节点。
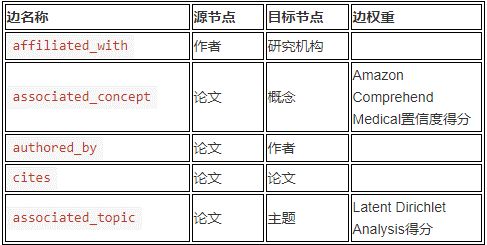
下图所示,为123中的示例图谱。请注意,从论文(Paper)节点到作者(Author)及概念(Concept)节点延伸出的连接,以及从作者(Author)节点到研究机构(Institution)节点间的连接。

图中的蓝色节点代表论文,由黄色节点所代表的作者撰写而成,而作者又隶属于绿色节点代表的研究机构。一篇论文可以有多位作者,而这些作者又可能隶属于多家研究机构。
概念节点(红色节点)是由 Amazon Comprehend Medical Detect Entities V2 通过提取各类医学信息所生成,具体包括医学状况、药物剂量、解剖信息、治疗程序以及药物类型等。
主题节点(上图中未显示)则是由经过扩展的 Latent Dirichlet 分配模型负责生成。这类生成模型按照观察到的内容对文件进行分组,并为每份文件分配一条主题向量混合指标。对于每一篇论文,该模型都会参考其中的纯文本标题、摘要以及正文部分,同时忽略掉表格、数字与书目等部分。
通过将作者、研究机构、论文以及论文主题等要素联系起来,这些节点共同构成了丰富的图谱体系。
解决方案概述
在亚马逊云科技数据湖中,我们可以使用内置的 Amazon CloudFormation 模板创建一个 Amazon CloudFormation 栈。Amazon CloudFormation 栈属于各项可独立作为单元进行管理的亚马逊云科技资源的集合。关于更多详细信息,请参阅如何使用栈。
要建立 COVID-19 知识图谱,我们需要利用预置模板创建一套 Amazon CloudFormation 栈。该模板负责创建必要的亚马孙云科技资源,并摄取数据以添加至图谱当中。
在亚马逊云科技账户当中完成 COVID-19 知识图谱构建之后,我们即可使用 Gremlin-Python 运行各类基础及高级查询。
基础查询包括对图谱的探索与搜索,目的在于对图谱内容建立初步认知,并熟练使用 gremlin-python 进行图谱查询。
在高级查询方面,本文中涉及的具体操作包括:
- 查询 COVID-19 知识图谱以获取与特定概念相关的论文。
- 根据作者的专业水平对论文进行排名,确定需要优先阅读的论文。
- 使用图查询机制创建相关论文推荐引擎,借此确定接下来需要阅读的论文。
先决条件
在开始本轮演练之前,大家首先需要满足以下先决条件:
- 访问亚马逊云科技账户。
- 具备创建 Amazon CloudFormation 栈的权限。
使用 Amazon CloudFormation 模板
要在您的亚马逊云科技账户当中配置图谱与示例查询 notebook,我们首先需要使用 Amazon CloudFormation 模板创建一个 Amazon CloudFormation 栈。
启动以下一键式模板,并在栈创建过程中出现提示时,使用以下参数(其他未提及的参数皆保留默认值):AutoIngestData: True
模板将自动完成以下操作:
- 创建一个 Amazon Neptune 数据库集群。
- 创建一个 Virtual Private Cloud(VPC)。
所有 Amazon Neptune 集群都必须在 VPC 内运行,因此该模板还将在 VPC 内设置私有与公共子网,确保 Amazon Neptune 在正常访问互联网的同时、免受未授权访问的影响。
- 创建一个 Amazon SageMaker notebook 实例,并通过权限设置允许其访问 VPC 当中的 Amazon Neptune 集群。
整套栈将大量 Python 库加载至 notebook 实例中,帮助用户与图形进行交互。
此 notebook 实例中还包含 Jupyter 演示 notebook,用于展示如何实现图谱查询。
- 将数据摄取至图谱当中。此图谱中的所有数据都将存储在公开亚马逊云科技 COVID-19 数据湖中。
在模板操作执行完成之后,我们可以访问 Amazon SageMaker notebook 实例与示例 Jupyter notebook。关于更多具体说明,请参阅访问 Notebook 实例。
Amazon Neptune 与 Gremlin
Amazon Neptune 全面兼容 Apache TinkerPop3 与 Gremlin 3.4.1,因此大家可以使用 Gremlin 图遍历语言直接查询 Amazon Neptune 数据库实例。Gremlin-Python 则在 Python 语言中实现了 Gremlin。关于 Gremlin 的更多详细信息,请参阅 GREMLIN 实战:Apache TInkerPop 教程。
我们可以通过 gremlin-python 直接查询 Amazon Neptune。关于更多详细信息,请参阅使用 Gremlin 访问 Amazon Neptune 图。
基础查询
以下列出的几项基础查询,展示了如何在 Amazon SageMaker Jupyter notebook 中使用 gremlin-python 实现基本的图浏览与搜索。通过前文介绍的操作,我们已经顺利完成 Amazon SageMaker notebook 实例的创建,大家可以在其中执行各类查询操作。需要注意的是,由于数据集仍在不断发展,因此您的实际输出可能与本文中列出的输出有所不同。
图探索
以下查询用于获取节点数量与每一种节点类型对应的数量。要提取图中的所有顶点,请使用 g.V() 与 hasLabel(NODE_NAME) 对图进行特定节点类型过滤,并使用 count() 获取节点数量。最终步骤 next() 将返回以下结果。
1nodes = g.V().count().next()
2papers = g.V().hasLabel('Paper').count().next()
3authors = g.V().hasLabel('Author').count().next()
4institutions = g.V().hasLabel('Institution').count().next()
5topics = g.V().hasLabel('Topic').count().next()
6concepts = g.V().hasLabel('Concept').count().
7
8print(f"papers: {papers}, authors: {authors}, institutions: {institutions}")
9print(f"topics: {topics}, concepts: {concepts}")
10print(f"Total number of nodes: {nodes}")以下代码为输出结果:
1papers: 42220, authors: 162928, institutions: 21979
2topics: 10, concepts: 109750
3Total number of nodes: 336887以下查询将返回边数与各种具体边类型的对应数量。要提取图中的所有边,请使用 g.E() 与 hasLabel(EDGE_NAME) 以过滤各边,并使用 count() 获取边计数。最终步骤 next() 将返回以下结果。
1paper_author = g.E().hasLabel('authored_by').count().next()
2author_institution = g.E().hasLabel('affiliated_with').count().next()
3paper_concept = g.E().hasLabel('associated_concept').count().next()
4paper_topic = g.E().hasLabel('associated_topic').count().next()
5paper_reference = g.E().hasLabel('cites').count().next()
6edges = g.E().count().next()
7
8print(f"paper-author: {paper_author}, author-institution: {author_institution}, paper-concept: {paper_concept}")
9print(f"paper-topic: {paper_topic}, paper-reference: {paper_reference}")
10print(f"Total number of edges: {edges}")
以下代码为输出结果:
1paper-author: 240624, author-institution: 121257, paper-concept: 2739666
2paper-topic: 95659, paper-reference: 134945
3Total number of edges: 3332151图搜索
以下查询会过滤图中的所有作者节点,并使用 valueMap(), limit() 及 toList() 从 COVID-19 知识图谱中抽取五位作者,最终返回一份字典:
1g.V().hasLabel('Author').valueMap('full_name').limit(5).toList()以下代码为输出结果:
1[{'full_name': ['· J Wallinga']},
2 {'full_name': ['· W Van Der Hoek']},
3 {'full_name': ['· M Van Der Lubben']},
4 {'full_name': ['Jeffrey Shantz']},
5 {'full_name': ['Zhi-Bang Zhang']}]下列查询用于过滤图中的各主题节点。该查询使用 hasLabel() 与 has() 过滤特定主题,随后由 both() 从该主题节点的传入与传出边获取论文节点, limit() 用于限制结果,而 values() 则用于从该主题节点处获取特定属性。最终步骤 toList() 将结果以列表形式返回:
1g.V().hasLabel('Topic').has('topic', 'virology').both()\
2.limit(3).values('title').toList()以下代码为对应输出结果:
1['Safety and Immunogenicity of Recombinant Rift Valley Fever MP-12 Vaccine Candidates in Sheep',
2 'Ebola Virus Neutralizing Antibodies Detectable in Survivors of theYambuku, Zaire Outbreak 40 Years after Infection',
3 'Respiratory Viruses and Mycoplasma Pneumoniae Infections at the Time of the Acute Exacerbation of Chronic Otitis Media']高级查询
下图所示,为我们可以从 COVID-19 知识图谱中获取的各种信息类型。大家可以使用 COVID-19 知识图谱进行论文排名,并提取单一论文的相关信息(后文将具体解释)。
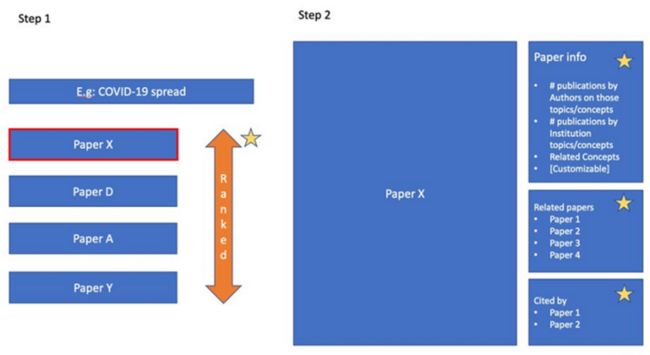
围绕特定概念进行论文排名
对于此类用例,我们可以查询 COVID-19 知识图谱以获取病毒抗性相关论文,并按第一作者对论文者排名。要查找关于该主题的所有论文,请使用以下代码:
1concept = 'viral resistance'
2papers = g.V().has('Concept', 'concept', concept).both().values('SHA_code').toList()
3
4print(f"Number of papers related to {concept}: {len(papers)}")
以下代码为相应输出结果:
1Number of papers related to viral resistance: 74要进行论文排名,请使用以下代码:
1def author_prolific_rank(graph_results, groupby='SHA_code'):
2 P = g.V()\
3 .has('Paper', 'SHA_code', within(*graph_results))\
4 .group().by(__.values(groupby))\
5 .by(
6 __.out('authored_by').local(__.in_('authored_by').simplePath().count()).mean()
7 ).order(local).by(values, desc).toList()[0]
8
9 return P
10
11def sha_to_title(sha):
12 title_list = g.V().has('Paper', 'SHA_code', sha)\
13 .values('title').toList()
14
15 return ''.join(title_list)
16author_ranked = author_prolific_rank(papers)author_ranked_df = pd.DataFrame(
17 [author_ranked], index=['Score']
18).T.sort_values('Score', ascending=False).head()
19author_ranked_df['title'] = author_ranked_df.index.map(sha_to_title)
20
21for row in author_ranked_df.drop_duplicates(subset='title').reset_index().iterrows():
22 print(f"Score: {round(row[1]['Score'], 2)}\tTitle: {row[1]['title']}")
以下代码为对应的输出结果:
1Score: 27.5 Title: Surveillance for emerging respiratory viruses
2Score: 11.45 Title: Third Tofo Advanced Study Week on Emerging and Re-emerging Viruses, 2018
3Score: 10.5 Title: The Collaborative Cross Resource for Systems Genetics Research of Infectious Diseases
4Score: 10.0 Title: RNA interference against viruses: strike and counterstrike
5Score: 9.0 Title: Emerging Antiviral Strategies to Interfere with Influenza Virus Entry
相关论文推荐
在此类用例中,我们希望根据当前阅读的论文,确定接下来有必要阅读的其他相关论文。要开发这样一套推荐引擎,基本思路自然是使用图查询机制。论文与概念,在图中为通过边连接的两类节点。各项概念由 Amazon Comprehend Medical 利用机器学习派生而来,其中包含一项置信度得分 conf,用于表示机器学习对于概念c在论文p中的置信度量化指标。
要确定两篇论文是否相互关联,我们首先需要定义一个相似度评分S。在 COVID-19 知识图谱当中,不同论文节点之间由概念节点实现连通。
要根据特定论文P生成一份论文列表,我们需要在P与 COVID-19 知识图谱中其他论文之间生成相似度评分,而后对结果进行排名。相似度评分越高的论文,其与论文P之间的相关性就越高。
两篇论文之间的相似性评分,为两篇论文间所有路径的加权总和。以矩阵形式,候选论文P.的得分为向量P与P.的点积,其中向量P与候选论文P.的大小分别为[N_{概念}, 1] 。论文与概念i间的边权重表示为元素e.,如果二者之间没有边连接,则记为0。
下图所示,为示例中的推荐框架。
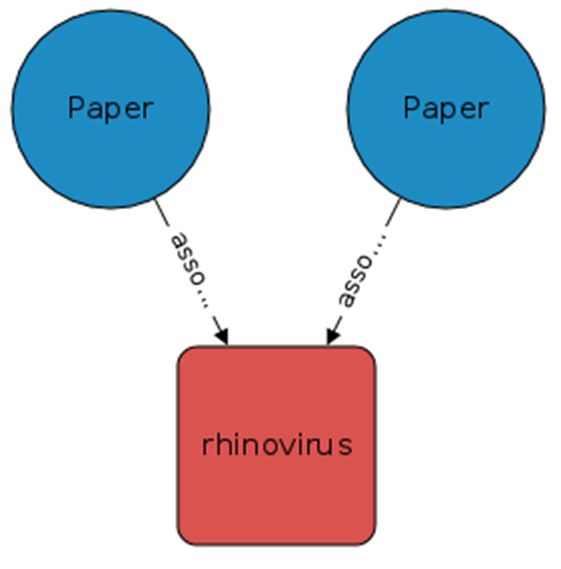
在此图中,两篇论文之间的连通路径为术语 “rhinovirus”。每一条论文-概念边都拥有一条置信度得分 conf。
对于两篇论文之间的每一条路径,我们可以将其置信度得分相乘。要计算两篇论文之间的相似度得分,则需要对所有置信度得分的乘积进行相加。
首先,获取以下论文的相关论文,详见下列操作代码:
1sha = "f1716a3e74e4e8139588b134b737a7e573406b32"
2title = "Title: Comparison of Hospitalized Patients With ARDS Caused by COVID-19 and H1N1"
3print(f"Title: {title}")
4print(f"Unique ID: {sha}") 使用此前定义的算法查询知识图谱,详见以下操作代码:
1Title: Comparison of Hospitalized Patients With ARDS Caused by COVID-19 and H1N1
2Unique ID: f1716a3e74e4e8139588b134b737a7e573406b32下表总示,为整理得出的输出结果:

总结
亚马逊云科技 COVID-19 数据湖免费托管在 Amazon Simple Storage Service(Amazon S3) 之上,指向这类公开数据湖存储桶的数据请求不会产生 Amazon S3 标准费用,大家可以直接免费使用。但在通过 Amazon CloudFormation 栈在亚马逊云科技账户当中构建 COVID-19 知识图谱时,使用由 Amazon SageMaker 托管的 Amazon Neptune 与 Jupyter notebook 可能产生相应费用。关于更多详细信息,请参阅 Amazon Neptune 计费标准与 Amazon SageMaker 计费标准。
为了避免重复计费,请在演练完成之后删除 Amazon CloudFormation 栈。关于具体说明,请参阅在 Amazon CloudFormation 控制台上删除栈。另外,请确保删除 root 栈(我们之前创建完成的栈)以删除所有嵌套栈。
您也可以使用 Amazon CloudFormation 模板构建知识图谱,并使用第三方图可视化工具 Tom Sawyer 图数据库浏览器等实现图谱可视化。关于更多详细信息,请参阅使用 Amazon Neptune、Amazon Comprehend Medical 以及 Tom Sawyer 图数据库浏览器进行 COVID-19 科学研究。
相信在各参与方与科学学科之间的通力合作之下,我们终将赢得这场 COVID-19 抗疫战役的胜利。使用 COVID-19 知识图谱,我们可以提出并回答与 COVID-19 科学文献相关的各类问题。我们坚信,将数据、技术与科学等领域的成果同开放精神结合起来,我们必定可以激发洞见、促进合作,最终遏制、缓解并消涂 COVID-19 疫情。
原文链接(英文版):
https://aws.amazon.com/cn/blo...
本篇作者

Miguel Romero
亚马逊云科技机器学习解决方案实验室数据科学家
他构建的各类解决方案旨在帮助客户轻松采用机器学习与AI解决方案处理各类业务问题。他目前主要负责为体育界客户开发与赛事播放相关的预测模型,借此提高粉丝群体的参与度。

Colby Wise
亚马逊云科技机器学习解决方案实验室数据科学家兼经理。
他主要负责帮助来自各行各业的亚马逊云科技客户加速AI与云服务采用进度。

George Price
亚马逊云科技机器学习解决方案实验室深度学习架构师
他主要负责帮助亚马逊云科技客户构建模型与架构。在此之前,他还曾担任Amazon Alexa项目软件工程师。