使用深度学习和 OpenCV 进行目标检测
基于深度学习的对象检测时,您可能会遇到三种主要的对象检测方法:
Faster R-CNNs (Ren et al., 2015)
You Only Look Once (YOLO) (Redmon et al., 2015)
Single Shot Detectors (SSD)(Liu 等人,2015 年)
Faster R-CNNs 可能是使用深度学习进行对象检测最“听说”的方法;然而,该技术可能难以理解(特别是对于深度学习的初学者)、难以实施且难以训练。
此外,即使使用“更快”的 R-CNN 实现(其中“R”代表“区域提议”),算法也可能非常慢,大约为 7 FPS。
如果追求纯粹的速度,那么我们倾向于使用 YOLO,因为这种算法要快得多,能够在 Titan X GPU 上处理 40-90 FPS。 YOLO 的超快变体甚至可以达到 155 FPS。
YOLO 的问题在于它的准确性不高。
最初由 Google 开发的 SSD 是两者之间的平衡。该算法比 Faster R-CNN 更直接。
MobileNets:高效(深度)神经网络
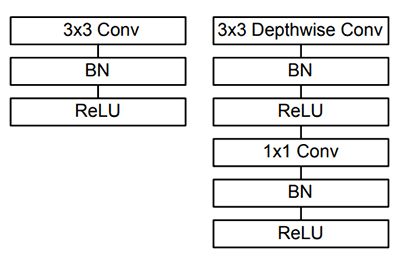
在构建对象检测网络时,我们通常使用现有的网络架构,例如 VGG 或 ResNet,这些网络架构可能非常大,大约 200-500MB。 由于其庞大的规模和由此产生的计算数量,诸如此类的网络架构不适合资源受限的设备。 相反,我们可以使用 Google 研究人员的另一篇论文 MobileNets(Howard 等人,2017 年)。我们称这些网络为“MobileNets”,因为它们专为资源受限的设备而设计,例如您的智能手机。 MobileNet 与传统 CNN 的不同之处在于使用了深度可分离卷积。 深度可分离卷积背后的一般思想是将卷积分成两个阶段:
- 3×3 深度卷积。
- 随后是 1×1 逐点卷积。
这使我们能够实际减少网络中的参数数量。 问题是牺牲了准确性——MobileNets 通常不如它们的大哥们准确…… ……但它们的资源效率要高得多。
使用 OpenCV 进行基于深度学习的对象检测
MobileNet SSD 首先在 COCO 数据集(上下文中的常见对象)上进行训练,然后在 PASCAL VOC 上进行微调,达到 72.7% mAP(平均精度)。
因此,我们可以检测图像中的 20 个对象(背景类为 +1),包括飞机、自行车、鸟、船、瓶子、公共汽车、汽车、猫、椅子、牛、餐桌、狗、马、摩托车、人、盆栽 植物、羊、沙发、火车和电视显示器。
在本节中,我们将使用 OpenCV 中的 MobileNet SSD + 深度神经网络 (dnn) 模块来构建我们的目标检测器。
打开一个新文件,将其命名为 object_detection.py ,并插入以下代码:
import numpy as np
import cv2
if __name__=="__main__":
image_name = '11.jpg'
prototxt = 'MobileNetSSD_deploy.prototxt.txt'
model_path = 'MobileNetSSD_deploy.caffemodel'
confidence_ta = 0.2
# 初始化MobileNet SSD训练的类标签列表
# 检测,然后为每个类生成一组边界框颜色
CLASSES = ["background", "aeroplane", "bicycle", "bird", "boat",
"bottle", "bus", "car", "cat", "chair", "cow", "diningtable",
"dog", "horse", "motorbike", "person", "pottedplant", "sheep",
"sofa", "train", "tvmonitor"]
COLORS = np.random.uniform(0, 255, size=(len(CLASSES), 3))
导入需要的包。
定义全局参数:
- image_name:输入图像的路径。
- prototxt :Caffe prototxt 文件的路径。
- model_path :预训练模型的路径。
- confidence_ta :过滤弱检测的最小概率阈值。 默认值为 20%。
接下来,让我们初始化类标签和边界框颜色。
# load our serialized model from disk
print("[INFO] loading model...")
net = cv2.dnn.readNetFromCaffe(prototxt, model_path)
# 加载输入图像并为图像构造一个输入blob
# 将大小调整为固定的300x300像素。
# (注意:SSD模型的输入是300x300像素)
image = cv2.imread(image_name)
(h, w) = image.shape[:2]
blob = cv2.dnn.blobFromImage(cv2.resize(image, (300, 300)), 0.007843,
(300, 300), 127.5)
# 通过网络传递blob并获得检测结果和
# 预测
print("[INFO] computing object detections...")
net.setInput(blob)
detections = net.forward()
从磁盘加载模型。
读取图片。
提取高度和宽度(第 35 行),并从图像中计算一个 300 x 300 像素的 blob。
将blob放入神经网络。
计算输入的前向传递,将结果存储为 detections。
# 循环检测结果
for i in np.arange(0, detections.shape[2]):
# 提取与数据相关的置信度(即概率)
# 预测
confidence = detections[0, 0, i, 2]
# 通过确保“置信度”来过滤掉弱检测
# 大于最小置信度
if confidence > confidence_ta:
# 从`detections`中提取类标签的索引,
# 然后计算物体边界框的 (x, y) 坐标
idx = int(detections[0, 0, i, 1])
box = detections[0, 0, i, 3:7] * np.array([w, h, w, h])
(startX, startY, endX, endY) = box.astype("int")
# 显示预测
label = "{}: {:.2f}%".format(CLASSES[idx], confidence * 100)
print("[INFO] {}".format(label))
cv2.rectangle(image, (startX, startY), (endX, endY),
COLORS[idx], 2)
y = startY - 15 if startY - 15 > 15 else startY + 15
cv2.putText(image, label, (startX, y),
cv2.FONT_HERSHEY_SIMPLEX, 0.5, COLORS[idx], 2)
# show the output image
cv2.imshow("Output", image)
cv2.imwrite("output.jpg", image)
cv2.waitKey(0)
循环检测,首先我们提取置信度值。
如果置信度高于我们的最小阈值,我们提取类标签索引并计算检测到的对象周围的边界框。
然后,提取框的 (x, y) 坐标,我们将很快使用它来绘制矩形和显示文本。
接下来,构建一个包含 CLASS 名称和置信度的文本标签。
使用标签,将其打印到终端,然后使用之前提取的 (x, y) 坐标在对象周围绘制一个彩色矩形。
通常,希望标签显示在矩形上方,但如果没有空间,我们会将其显示在矩形顶部下方。
最后,使用刚刚计算的 y 值将彩色文本覆盖到图像上。
运行结果:

使用 OpenCV 检测视频
打开一个新文件,将其命名为 video_object_detection.py ,并插入以下代码:
video_name = '12.mkv'
prototxt = 'MobileNetSSD_deploy.prototxt.txt'
model_path = 'MobileNetSSD_deploy.caffemodel'
confidence_ta = 0.2
# initialize the list of class labels MobileNet SSD was trained to
# detect, then generate a set of bounding box colors for each class
CLASSES = ["background", "aeroplane", "bicycle", "bird", "boat",
"bottle", "bus", "car", "cat", "chair", "cow", "diningtable",
"dog", "horse", "motorbike", "person", "pottedplant", "sheep",
"sofa", "train", "tvmonitor"]
COLORS = np.random.uniform(0, 255, size=(len(CLASSES), 3))
# load our serialized model from disk
print("[INFO] loading model...")
net = cv2.dnn.readNetFromCaffe(prototxt, model_path)
# initialze the video stream, allow the camera to sensor to warmup,
# and initlaize the FPS counter
print('[INFO] starting video stream...')
vs = cv2.VideoCapture(video_name)
fps = 30 #保存视频的FPS,可以适当调整
size=(600,325)
fourcc=cv2.VideoWriter_fourcc(*'XVID')
videowrite=cv2.VideoWriter('output.avi',fourcc,fps,size)
time.sleep(2.0)
定义全局参数:
- video_name:输入视频的路径。
- prototxt :Caffe prototxt 文件的路径。
- model_path :预训练模型的路径。
- confidence_ta :过滤弱检测的最小概率阈值。 默认值为 20%。
接下来,让我们初始化类标签和边界框颜色。
加载模型。
初始化VideoCapture对象。
设置VideoWriter对象以及参数。size的大小由下面的代码决定,需要保持一致,否则不能保存视频。
接下就是循环视频的帧,然后输入到检测器进行检测,这一部分的逻辑和图像检测一致。代码如下:
# loop over the frames from the video stream
while True:
ret_val, frame = vs.read()
if ret_val is False:
break
frame = imutils.resize(frame, width=1080)
print(frame.shape)
# grab the frame dimentions and convert it to a blob
(h, w) = frame.shape[:2]
blob = cv2.dnn.blobFromImage(cv2.resize(frame, (300, 300)), 0.007843, (300, 300), 127.5)
# pass the blob through the network and obtain the detections and predictions
net.setInput(blob)
detections = net.forward()
# loop over the detections
for i in np.arange(0, detections.shape[2]):
# extract the confidence (i.e., probability) associated with
# the prediction
confidence = detections[0, 0, i, 2]
# filter out weak detections by ensuring the `confidence` is
# greater than the minimum confidence
if confidence > confidence_ta:
# extract the index of the class label from the
# `detections`, then compute the (x, y)-coordinates of
# the bounding box for the object
idx = int(detections[0, 0, i, 1])
box = detections[0, 0, i, 3:7] * np.array([w, h, w, h])
(startX, startY, endX, endY) = box.astype("int")
# draw the prediction on the frame
label = "{}: {:.2f}%".format(CLASSES[idx],
confidence * 100)
cv2.rectangle(frame, (startX, startY), (endX, endY),
COLORS[idx], 2)
y = startY - 15 if startY - 15 > 15 else startY + 15
cv2.putText(frame, label, (startX, y),
cv2.FONT_HERSHEY_SIMPLEX, 0.5, COLORS[idx], 2)
# show the output frame
cv2.imshow("Frame", frame)
videowrite.write(frame)
key = cv2.waitKey(1) & 0xFF
# if the `q` key was pressed, break from the loop
if key == ord("q"):
break
videowrite.release()
# do a bit of cleanup
cv2.destroyAllWindows()
vs.release()
运行结果:
https://www.bilibili.com/video/BV19i4y197kh?spm_id_from=333.999.0.0
以上就是基于深度学习和OpenCV实现目标检测的详细内容,更多关于深度学习 OpenCV目标检测的资料请关注脚本之家其它相关文章!