关于InnoDB 存储引擎的有 聚集索引和非聚集索引,覆盖索引,回表,索引下推等概念,这些知识点比较多,也比较零碎,但是概念都是基于索引建立的,本文从索引查找数据讲述上述概念。
聚集索引和非聚集索引
在 MySQL 数据库中 InnoDB 存储引擎,B+ 树可分为聚集索引和非聚集索引。聚集索引也叫聚簇索引,非聚集索引也叫辅助索引或者二级索引。
建表的时候都会创建一个聚集索引,每张表都有唯一的聚集索引:
- 如果主键被定义了,那么这个主键就是作为聚集索引
- 如果没有主键被定义,那么该表的第一个唯一非空索引作为聚集索引
- 如果没有主键也没有唯一索引,InnoDB 内部会生成一个隐藏的主键作为聚集索引,这个隐藏的主键是一个 6 个字节的列,该类的值会随着数据的插入自增。
在创建表添加的索引都是非聚集索引,非聚集索引就是一个为了找到聚集索引的二级索引,通过二级索引索引找到主键,再查找数据。
创建一个表 T,表中有个一个主键id。表中有字段 k,并创建在 k 字段上创建索引。
mysql> create table T(
id int primary key,
k int not null,
name varchar(16),
index (k)
)engine=InnoDB;在表中插入数据分别为(100,1)、(200,2)、(300,3)、(500,5)、(600,6),分别用R1~R5表示。当创建表和插入数据后会生成两棵树: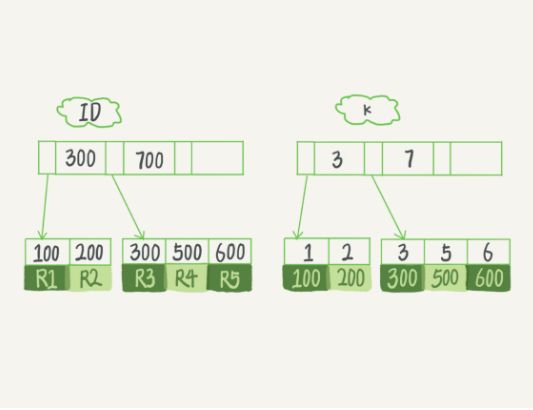
其中左边的是聚集索引,右边的是非聚集索引。非聚集索引叶子节点存储的是主键的值,聚集索引存储的是整行的数据。
执行 select * from T where k between 3 and 5,有以下的执行流程:
- 1、在 k 索引树上找到 k = 3,取得ID = 300
- 2、再到 ID 索引树查到 ID=300对应的R3
- 3、在 k 索引树取下一个值 k=5,取得ID=500
- 4、再回到 ID 索引树查到 ID=500对应的 R4
- 5、在 k 索引树取下一个值 k=6,不满足条件,查询结束
在这个过程中,从二级索引回答主键索引树查找的过程,称为回表。上面流程回表了两次,分别是步骤2和步骤4。
覆盖索引
如果执行的语句是 select ID from T where k between 3 and 5,这个时候只需要查 ID 的值,而 ID 的值已经在 k 索引树上了,这个时候就不需要回表,也就是说在这个查询中,索引 k “覆盖了”查询,这个称为覆盖索引。
由于覆盖索引可以减少树的搜索次数,提高查询性能,所以使用覆盖索引是一个常用的索引优化手段。
使用覆盖索引最常见的方法是创建联合索引,将需要查询的字段都放在联合索引上。
最左前缀原则
最左前缀原则,指的是在一个复合索引中(a,b,c),b+ 树会按照从左往右的顺序建立搜索树,b+ 树会优先比较 a,如果 a 相同在依次比较 b 和 c,最后得到检索数据,但是像查询(b,c)这样的数据没有 a 字段,b+树就不知道从哪个结点查起了。因为搜索树的第一个比较因子就是 a。
索引下推(icp)
索引下推是 mysql 5.6 新特性
创建一个表 use,其中主要有几个字段:id、name、age、address。建立联合索引(name,age)。
mysql> create table use(
id int primary key,
name varchar(16),
age int ,
index(name,age)
)engine=InnoDB;在表中分别插入数据,(ID3,张六,30),(ID4,张三,10),(ID5,张三,10),(106,张三,20)
要执行以下查询:
select * from user where name like '张%' and age=10上面说到 InnoDB 索引满足最左匹配原则,当不符合最左前缀,会怎么样呢?在这个搜索树中,只能用“张”,找到一个满足条件 103,然后再判断其他条件是否满足。
这条语句在 Mysql 5.6 之前和 Mysql 5.6 以及 Mysql 5.6 以后版本执行是不一致的。
Mysql 5.6 之前
- 在 5.6 之前是没有索引下推的,只能从 ID3 开始一个个回表,虚线表示回表。到主键索引上找数据行,再对比字段值,如下图:

- 5.6 引入了索引下推,可以在索引遍历过程中,对索引包含的字段先做判断,直接过滤到不满足条件的记录,减少回表次数。如下图:

有了索引下推后,InnoDB 在(name,age)索引内就判断了 age 是否等于 10,不等于 10 的直接跳过,所以上面只需要回表 2 次。
总结
本文从索引查询数据流程上介绍了数据库索引的概念,包括聚集索引、非聚集索引、覆盖索引、回表、最左匹配、索引下推,对于基础的掌握可以更快的做数据库的优化,比如减少回表的次数,最好使用聚集索引,或者覆盖索引。加快数据查询速度。
参考
如果觉得文章对你有帮助的话,请点个赞吧!