前言
- 本篇是关于 MIT 6.S081-2020-Lab8(Lock) 的实现;
- 我并没有在找到“全局最优解”的情况下通过 Buffer cache 的测试;
- 因此在 Exercise 2 我只提供了在找到“全局最优解”的前提下,我的各种代码尝试以及思路;
- 如果内容上发现有什么问题请不要吝啬您的键盘。
准备工作
要新看的内容不多,只有第八章(File system) 的前三个小节。
文件系统的层次模型

这张图特别地像计算机网络层次服务模型:当前层调用下层所提供的服务为上层提供更优质的服务。但实际上到文件系统,这里的意味没有那么强,更像是对 Disk 的抽象程度,越往下走越靠近外设磁盘,越往上走越靠近用户进程。很多时候文件系统的分层不是很严格,所以这张图的意义在于帮助你理解文件系统的结构。
磁盘通常是 SSD 或 HDD,SSD 访问一个 disk block 需要 100us 到 1ms 之间,而 HDD 则需要 10ms 左右。对于磁盘驱动程序而言,磁盘都是 Sector 的集合,一个 sector 的大小为 512B;对于操作系统内核而言,磁盘则是一系列的 Block 数组,一个 Block 的大小为 1024B。今天我们不需要去关注 Sector,因为磁盘驱动程序 kernel/virtio_disk.c 为内核做了很好的屏蔽,我们只需使用它的对外提供的读写磁盘某个 Block 的接口(顶半部:virtio_disk_rw())即可,给定 Block number 返回 Block cache。
/* kernel/buf.h */
struct buf {
int valid; // has data been read from disk?
int disk; // does disk "own" buf?
uint dev;
uint blockno;
struct sleeplock lock;
uint refcnt;
struct buf *prev; // LRU cache list
struct buf *next;
uchar data[BSIZE];
};
/* kernel/bio.c */
struct {
struct spinlock lock;
struct buf buf[NBUF];
// Linked list of all buffers, through prev/next.
// Sorted by how recently the buffer was used.
// head.next is most recent, head.prev is least.
struct buf head;
} bcache;
void
binit(void)
{
struct buf *b;
initlock(&bcache.lock, "bcache");
// Create linked list of buffers
bcache.head.prev = &bcache.head;
bcache.head.next = &bcache.head;
for(b = bcache.buf; b < bcache.buf+NBUF; b++){
b->next = bcache.head.next;
b->prev = &bcache.head;
initsleeplock(&b->lock, "buffer");
bcache.head.next->prev = b;
bcache.head.next = b;
}
}
为了加快读写访问速度,缓存的设计可以说是必需的。整个文件系统就一个 Buffer cache(struct bcache),Buffer cache 存储有多个 Block cache(struct buf),这些 Block cache 和 bcache.head 通过 binit() 一同形成环状双链表。Buffer cache 用到的 Block cache 置换算法是 LRU(Least Recently Used, bget())。bcache.head.prev 一侧将会是最远被使用过的 Block cache,而 bcache.head.next 将会是最近被使用的 Block cache。同时为了保证并发线程环境下 Block 内容的一致性,Buffer cache 配有一个 Spin Lock,所有 Buffer cache 共用一个 sleep-lock。为什么不都是自旋锁,以及 sleep-lock 的作用下一个部分会介绍。
Logging 层这里就不多做介绍了,因为这是下一个 Lab 的内容。
/* kernel/fs.h */
// On-disk inode structure
struct dinode {
short type; // File type
short major; // Major device number (T_DEVICE only)
short minor; // Minor device number (T_DEVICE only)
short nlink; // Number of links to inode in file system
uint size; // Size of file (bytes)
uint addrs[NDIRECT+1]; // Data block addresses
};
inode 层主要是为文件提供的一层抽象。每个 inode 都有唯一标识的 inode 号,每个 inode 的大小都为 64 bytes。只要给定一个 inode 号,我们就可以推算出这个 inode 位于磁盘中的哪一个 Block 的哪个字节开始的。根据这个地址拿到这个 inode 后,我们可以推算出这个 inode 所对应的文件的大小以及该文件被存储在哪几个 Block 中。
dinode.addrs[] 的前 NDIRECT 个元素都是 Direct block number。这 NDIRECT 个 Direct blocks 中存储有文件的最多前 sizeof(buf)*NDIRECT 个字节。如果文件的大小比较小,可能用不了 NDIRECT 个 Blocks 就能装的下来;如果文件的大小比较大,NDIRECT 个 Blocks 都装不下的话就需要 dinode.addrs[NDIRECT] 这个 Indirect block number 派上用场了。Indirect Block 充当索引 Block,其内含有一系列的 Block numbers,而这些 Block numbers 所指代的 Blocks 就负责装有那些 Direct Blocks 装不下的剩余的文件。所以,一个文件的大小最大为 sizeof(buf)*(NDIRECT+(sizeof(buf)/sizeof(buf.blockno))) 个字节。
/* kernel/fs.h */
struct dirent {
ushort inum;
char name[DIRSIZ];
};
如果用户看到的文件都是一些 inode 编号,然后通过这些 inode 编号来操作文件,那未免这个文件系统也太难用了,用户可能都不知道自己在操作哪个文件。
于是到了目录层,为用户提供了层次化的命名空间(hierarchical namespace) 的服务,可以给自己的文件取个好记的名字,并且以层级目录的方式将这些文件组织起来。为同时实现这两点,我们引入了新的数据结构:struct dirent。并且为了支持访问这些数据结构,我们扩展了 inode 的类型,所以现在 dinode.type 的取值不仅可以是 T_FILE,还可以是 T_DIR,这些宏都在 kernel/stat.h 中被定义。sizeof(dirent) 为 16 个字节,目录名称为 14 个字节,同时 dinode.link 代表有多少文件名指向这个 inode。
路径名层所提供的功能很简单:给定一个路径名,路径名层能够解析它并查找该路径下的文件。xv6 实现的解析算法是线性扫描。即如果给定路径名 /usr/rtm/xv6/fs.c:
- 文件系统会首先去找 root inode,root inode 的 inode number 固定为 1;
- 发现 root inode 的类型是
T_DIR,于是在 root inode 指向的 Blocks 中遍历搜索dirent.name为 usr 的目录; - 如果没找到就返回错误,找到了就那到 usr 的 inode 编号,递归执行上述步骤;
- 最终拿到
dirent.name为 fs.c 的目录,拿到 inode 编号后; - 发现 fs.c 的 inode 的类型是
T_FILE,查找成功。
文件描述符层提供了许多对 Unix 资源的抽象,包括文件、设备、管道、Socket 等等,利用这个最上层的文件系统接口,能够大大简化程序员访问这些资源的操作。起初文件描述符只是给文件用的,不过大家渐渐发现,对于设备、管道这类资源的操作和文件的操作都很像,不外乎就是打开、读写、关闭这些操作,因此就统一使用了文件系统提供的接口。
文件系统在 Disk 中的组织结构
文件系统会把磁盘看作是一整个 Block 数组,每个 Block 大小为 1KB:
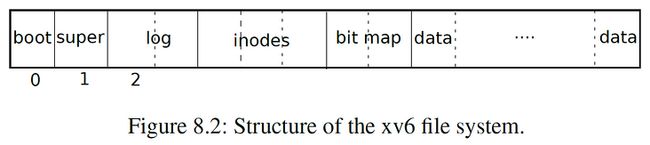
disk[0]要么没用,要么被用所 Boot Sector 来启动操作系统;disk[1]被称为 Super Block,里面存储有整个文件系统的 metadata,包括文件系统的大小、Data Blocks 的个数、inodes 的个数、Logging Blocks 的个数等等;disk[2]~disk[31]都是 Logging Blocks;disk[32]~disk[44]存储有 inode;disk[45]是 bitmap,当该 Block 的第 n 个 bit 置位时,代表 Block number 为 n 的 Block 正被占用;disk[46]~都是 Data Blocks,被占用的 Block 都存储有文件的内容或目录的内容。
Buffer cache layer
Buffer cache layer 所提供的服务有以下几点:
确保 Buffer cache 里同一个 Disk block 的拷贝(Block cache)不超过一个;
- 否则会出现数据的不一致性
确保同时访问一个 Block cache 的内核线程不超过一个;
- 通过给每个 Block cache 设立一个 sleep-lock 来实现
- 确保那些经常要访问的 Blocks 要在 Buffer cache 中有一份拷贝(Block cache)。
/* kernel/bio.c */
struct buf*
bread(uint dev, uint blockno)
{
struct buf *b;
b = bget(dev, blockno);
if(!b->valid) {
virtio_disk_rw(b, 0);
b->valid = 1;
}
return b;
}
void
bwrite(struct buf *b)
{
if(!holdingsleep(&b->lock))
panic("bwrite");
virtio_disk_rw(b, 1);
}
void
brelse(struct buf *b)
{
if(!holdingsleep(&b->lock))
panic("brelse");
releasesleep(&b->lock);
acquire(&bcache.lock);
b->refcnt--;
if (b->refcnt == 0) {
// no one is waiting for it.
b->next->prev = b->prev;
b->prev->next = b->next;
b->next = bcache.head.next;
b->prev = &bcache.head;
bcache.head.next->prev = b;
bcache.head.next = b;
}
release(&bcache.lock);
}
Buffer cache layer 对外的接口只有两个,一个是 bread(),另一个是 bwrite(),都在 kernel/bio.c 中有定义。内核线程对某个 Block cache 完成操作后,都必须要释放它的锁(brelse())。brelse() 不仅会释放 sleep-lock,还会将这个 Block cache 调整到 bcache.head.next 这个位置,代表它是被最近访问过的 Block cache。
bread()- 给定一个 Block number,返回对应的上锁的 Block cache;
- 如果命中了直接返回;
- 如果没命中就根据 RLU 算法选中一个空闲(
refcnt字段为 0 代表这个 Block cache 没有被任何一个内核线程正在占用)的 Block cache 后,选择将其重用并将valid字段设为 0 代表这个 Block cache 没有对应 Disk block 的数据,提示break()调用去从磁盘直接获取这个 Block 的数据。 - 如果没有命中,并且没有一个空闲的 Block cache,文件系统会直接 panic,是个比较粗暴的处理。
bwrite()- 如果某个内核线程修改了某个 Block cache 的内容,它必须在释放这个 Block cache 的 sleep-lock 之前调用
bwrite,来将指定 Block number 的 Block cache 强制写回 Disk 中。
- 如果某个内核线程修改了某个 Block cache 的内容,它必须在释放这个 Block cache 的 sleep-lock 之前调用
可以看到 bwrite() 的实现要更简单些,所以重点看 bread() 的实现。bread() 调用了一个 bget():
/* kernel/bio.c */
static struct buf*
bget(uint dev, uint blockno)
{
struct buf *b;
acquire(&bcache.lock);
// Is the block already cached?
for(b = bcache.head.next; b != &bcache.head; b = b->next){
if(b->dev == dev && b->blockno == blockno){
b->refcnt++;
release(&bcache.lock);
acquiresleep(&b->lock);
return b;
}
}
// Not cached.
// Recycle the least recently used (LRU) unused buffer.
for(b = bcache.head.prev; b != &bcache.head; b = b->prev){
if(b->refcnt == 0) {
b->dev = dev;
b->blockno = blockno;
b->valid = 0;
b->refcnt = 1;
release(&bcache.lock);
acquiresleep(&b->lock);
return b;
}
}
panic("bget: no buffers");
}
如果两个内核线程正在并发的执行 bget(),那么为了保证只有一个进程在访问 Buffer cache,进入函数的一开始就获取 Buffer cache 的锁。最后想要的 Block cache 后,需要获取这个 Block cache 的 Sleep lock 再返回。
/* kernel/sleeplock.c */
void
acquiresleep(struct sleeplock *lk)
{
acquire(&lk->lk);
while (lk->locked) {
sleep(lk, &lk->lk);
}
lk->locked = 1;
lk->pid = myproc()->pid;
release(&lk->lk);
}
void
releasesleep(struct sleeplock *lk)
{
acquire(&lk->lk);
lk->locked = 0;
lk->pid = 0;
wakeup(lk);
release(&lk->lk);
}
为什么要是 sleep-lock,跟 Buffercache 一起用一般的自旋锁不行么?其实这里至少有两种考量:
- 访问一个 Block 是个慢速操作(毫秒级),读时如果没命中需要读磁盘,如果修改了 Block cache 还要写回磁盘,跟 CPU 执行指令的速度(纳秒级)相比太慢了。于其一直自旋占用 CPU 忙等,还不如 sleep 把 CPU 资源让出去。
- 别忘了调度器会释放掉进程锁,所以 sleep 时候不会关闭中断,也就能响应磁盘发送的中断,这是一般自旋锁做不到的。sleep-lock 算是设计的非常精妙的一种锁了。
总的来说,bcache.lock 保护的信息是哪些 Block 被 cached 了,而 sleep-lock 则保护的是 Block cache 的在读写时的内容。
实验部分
Memory allocator
多个 CPU hart 共用一个在内存中的 freelist 资源,势必会造成非常严重的竞争。
因此在这个 Exercise 中,我们需要为每一个 CPU 单独分配一个 freelist 和一个配套的 lock。
所以我们给 kernel/kalloc.c 中的 struct kmem 扩展成一个长度为 NCPU 的 kmem 数组即可。
之后可以通过 cpuid() 函数来获取当前是哪个 CPU hart 在做相关分配和释放操作。
特别注意的是,当某个 CPU hart 下的 freelist 空掉了之后,在 kalloc() 时,它就要去看看其它 CPU hart 下的 freelist 是否有余量,有的话就直接拿过来返回即可。
初始化 kmems 的工作我们交给 cpuid() == 0 的 CPU hart 去做,因此一开始所有的 free page 都在该 CPU hart 下的 freelist 中。
/* kernel/kalloc.c */
struct kmem {
struct spinlock lock;
struct run *freelist;
};
struct kmem kmems[NCPU];
void
kinit()
{
for (int ncpu = 0; ncpu < NCPU; ++ncpu)
initlock(&kmems[ncpu].lock, "kmem");
freerange(end, (void*)PHYSTOP);
}
void
kfree(void *pa)
{
struct run *r;
if(((uint64)pa % PGSIZE) != 0 || (char*)pa < end || (uint64)pa >= PHYSTOP)
panic("kfree");
// Fill with junk to catch dangling refs.
memset(pa, 1, PGSIZE);
r = (struct run*)pa;
push_off();
int cid = cpuid();
acquire(&kmems[cid].lock);
r->next = kmems[cid].freelist;
kmems[cid].freelist = r;
release(&kmems[cid].lock);
pop_off();
}
void *
kalloc(void)
{
struct run *r;
push_off();
int cid = cpuid();
acquire(&kmems[cid].lock);
r = kmems[cid].freelist;
if(r)
kmems[cid].freelist = r->next;
else {
for (int _cid = 0; _cid < NCPU; ++_cid) {
if (_cid == cid)
continue;
acquire(&kmems[_cid].lock);
r = kmems[_cid].freelist;
if (r) {
kmems[_cid].freelist = r->next;
release(&kmems[_cid].lock);
break;
}
release(&kmems[_cid].lock);
}
}
release(&kmems[cid].lock);
pop_off();
if(r)
memset((char*)r, 5, PGSIZE); // fill with junk
return (void*)r;
}
Buffer cache
在原先的实现中,我们是以全局双链表的形式来维护 Block cache 的新旧访问程度的,即最老的块在 head 的 prev 侧,最新的块在 head 的 next 侧。
在这个 Exercise 中,为了降低竞争程度,我们需要摒弃这种双链表的设计,转而使用桶哈希表。为什么使用哈希表能降低竞争程度?因为给一个大链表一个锁和给每个小桶一个锁的粒度相比,很明显后者锁的粒度更小,直观地减小了竞争频率。
在只有 Buffer cache 的锁和 hash bucket 的锁的前提下,假设 evict 的方案是遵循原来的,即“从所有的 Block cache 中,找到最老的且引用数为 0 的那一个”,那么这将会与这个 Exercise 的目标产生矛盾。
矛盾的原因如下:我们称原来的 evict 方案是寻找“全局最优解”。那么当一个进程 miss 时,它就要防止任何进程尝试去访问更新 Buffer cache 里的任一一个 Block cache,否则就会出错。例如,当进程 A 找到这个“全局最优解时”,进程 B 命中了这个 Block cache 并修改了它的 ticks 和引用数。之后两个进程将会共用一个 Block cache,这简直是个灾难性的错误。
在设计进程间的同步时,把需求列出来会更加清晰:
- 当不同进程在尝试 hit 时,只要不是同一个 bucket 就可以并行执行,否则串行;
- 当有进程执行 evict 操作时,其它所有进程都要等待。
在去了解了锁的类型后,我发现读写锁最能满足这里的需求。所以打算来自己封装一个类似读写锁的锁,于是以下是这个 Exercise 的实现:
// Buffer cache.
//
// The buffer cache is a linked list of buf structures holding
// cached copies of disk block contents. Caching disk blocks
// in memory reduces the number of disk reads and also provides
// a synchronization point for disk blocks used by multiple processes.
//
// Interface:
// * To get a buffer for a particular disk block, call bread.
// * After changing buffer data, call bwrite to write it to disk.
// * When done with the buffer, call brelse.
// * Do not use the buffer after calling brelse.
// * Only one process at a time can use a buffer,
// so do not keep them longer than necessary.
#include "types.h"
#include "param.h"
#include "spinlock.h"
#include "sleeplock.h"
#include "riscv.h"
#include "defs.h"
#include "fs.h"
#include "buf.h"
#define NBUCKET 13
struct entry {
struct buf *value;
struct entry *next;
uint ticks;
};
struct entry entries[NBUF];
struct bucket {
struct entry *e;
struct spinlock lock;
};
struct bucket table[NBUCKET];
int valid_cnt = 0;
struct entry *
remove(uint blockno)
{
int i = blockno % NBUCKET;
struct entry **p = &table[i].e;
struct entry *prev = 0;
struct entry *e = table[i].e;
for (; e; e = e->next) {
if (e->value->blockno == blockno) {
if (!prev)
*p = e->next;
else
prev->next = e->next;
return e;
}
prev = e;
}
return 0;
}
#define MAX_QUEUE_SIZE NBUF
struct entry *priority_queue[MAX_QUEUE_SIZE];
int
parent_index(int i)
{
return (i-1)/2;
}
int
left_child_index(int i)
{
return (2*i)+1;
}
int
right_child_index(int i)
{
return (2*i)+2;
}
void
swap_element(int i1, int i2)
{
struct entry *temp = priority_queue[i1];
priority_queue[i1] = priority_queue[i2];
priority_queue[i2] = temp;
}
uint current_queue_size = 0;
int
queue_push(struct entry *e)
{
if (current_queue_size == MAX_QUEUE_SIZE) return 1;
int current_idx = current_queue_size;
int parent_idx = parent_index(current_idx);
priority_queue[current_idx] = e;
while (current_idx != 0 && priority_queue[current_idx]->ticks < priority_queue[parent_idx]->ticks) {
swap_element(current_idx, parent_idx);
current_idx = parent_idx;
parent_idx = parent_index(current_idx);
}
++current_queue_size;
return 0;
}
struct entry *
queue_pop()
{
if (current_queue_size == 0) return 0;
struct entry *top_element = priority_queue[0];
int current_idx = 0;
swap_element(--current_queue_size, 0);
int left_child_idx;
int right_child_idx;
int min_child_idx;
uint left_child_ticks;
uint right_child_ticks;
uint current_ticks;
while (1) {
left_child_idx = left_child_index(current_idx);
right_child_idx = right_child_index(current_idx);
if (left_child_idx >= current_queue_size)
break;
left_child_ticks = priority_queue[left_child_idx]->ticks;
current_ticks = priority_queue[current_idx]->ticks;
if (right_child_idx >= current_queue_size) {
if (left_child_ticks < current_ticks)
swap_element(left_child_idx, current_idx);
break;
}
right_child_ticks = priority_queue[right_child_idx]->ticks;
min_child_idx = left_child_ticks < right_child_ticks ? left_child_idx : right_child_idx;
min_child_idx = priority_queue[min_child_idx]->ticks < current_ticks ? min_child_idx : current_idx;
if (min_child_idx == current_idx)
break;
else {
swap_element(min_child_idx, current_idx);
current_idx = min_child_idx;
}
}
return top_element;
}
void
queue_clear()
{
current_queue_size = 0;
}
struct {
struct spinlock lock;
struct buf buf[NBUF];
} bcache;
struct rwlock {
uint evicting;
uint hitting;
struct spinlock *lock;
};
struct rwlock evict_lock;
struct spinlock _evict_lock;
void
initrwlock(struct rwlock *rwlk, struct spinlock *splk)
{
rwlk->lock = splk;
rwlk->hitting = 0;
rwlk->evicting = 0;
}
void
acquirerwlock(struct rwlock *rwlk, int hit)
{
acquire(rwlk->lock);
if (hit) {
while (rwlk->evicting == 1) {
release(rwlk->lock);
acquire(rwlk->lock);
}
++rwlk->hitting;
} else {
while (rwlk->evicting == 1 || rwlk->hitting != 0) {
release(rwlk->lock);
acquire(rwlk->lock);
}
rwlk->evicting = 1;
}
release(rwlk->lock);
}
void
releaserwlock(struct rwlock *rwlk, int hit)
{
acquire(rwlk->lock);
if (hit) {
--rwlk->hitting;
} else {
rwlk->evicting = 0;
}
release(rwlk->lock);
}
void
binit(void)
{
memset(entries, 0, sizeof(struct entry)*NBUF);
memset(table, 0, sizeof(struct bucket)*NBUCKET);
memset(bcache.buf, 0, sizeof(struct buf)*NBUF);
initlock(&bcache.lock, "bcache");
initlock(&_evict_lock, "bcache-evict");
initrwlock(&evict_lock, &_evict_lock);
struct buf *b;
for (b = bcache.buf; b < bcache.buf+NBUF; ++b)
initsleeplock(&b->lock, "buffer");
struct bucket *bkt;
for (bkt = table; bkt < table+NBUCKET; ++bkt)
initlock(&bkt->lock, "bcache-bucket");
}
// Look through buffer cache for block on device dev.
// If not found, allocate a buffer.
// In either case, return locked buffer.
static struct buf*
bget(uint dev, uint blockno)
{
// Is the block already cached?
struct buf *b;
int nbucket = blockno%NBUCKET;
struct entry *e;
acquirerwlock(&evict_lock, 1);
acquire(&table[nbucket].lock);
for (e = table[nbucket].e; e; e = e->next) {
b = e->value;
if (b->dev == dev && b->blockno == blockno) {
++b->refcnt;
release(&table[nbucket].lock);
releaserwlock(&evict_lock, 1);
acquiresleep(&b->lock);
return b;
}
}
release(&table[nbucket].lock);
releaserwlock(&evict_lock, 1);
// ------------------------------------------------------------
// Not cached.
// Recycle the least recently used (LRU) unused buffer.
acquirerwlock(&evict_lock, 0);
if (valid_cnt < NBUF) {
b = &bcache.buf[valid_cnt];
b->dev = dev;
b->blockno = blockno;
b->valid = 0;
b->refcnt = 1;
e = entries + valid_cnt;
e->value = b;
e->next = table[nbucket].e;
table[nbucket].e = e;
++valid_cnt;
releaserwlock(&evict_lock, 0);
acquiresleep(&b->lock);
return b;
}
// -------------------------------------------------------
for (e = entries; e < &entries[NBUF]; ++e)
queue_push(e);
while ((e = queue_pop()) != 0) {
b = e->value;
int _nbucket = b->blockno % NBUCKET;
if (b->refcnt == 0) {
queue_clear();
if (_nbucket != nbucket) {
remove(b->blockno);
e->next = table[nbucket].e;
table[nbucket].e = e;
}
b->dev = dev;
b->blockno = blockno;
b->valid = 0;
b->refcnt = 1;
releaserwlock(&evict_lock, 0);
acquiresleep(&b->lock);
return b;
}
}
panic("bget: no buffers");
}
// Return a locked buf with the contents of the indicated block.
struct buf*
bread(uint dev, uint blockno)
{
struct buf *b;
b = bget(dev, blockno);
if(!b->valid) {
virtio_disk_rw(b, 0);
b->valid = 1;
}
return b;
}
// Write b's contents to disk. Must be locked.
void
bwrite(struct buf *b)
{
if(!holdingsleep(&b->lock))
panic("bwrite");
virtio_disk_rw(b, 1);
}
// Release a locked buffer.
// Move to the head of the most-recently-used list.
void
brelse(struct buf *b)
{
if(!holdingsleep(&b->lock))
panic("brelse");
acquirerwlock(&evict_lock, 0);
int nbucket = b->blockno % NBUCKET;
for (struct entry *e = table[nbucket].e; e; e = e->next)
if (e->value->blockno == b->blockno) {
e->ticks = ticks;
break;
}
--b->refcnt;
releaserwlock(&evict_lock, 0);
releasesleep(&b->lock);
}
void
bpin(struct buf *b) {
int nbucket = b->blockno % NBUCKET;
acquire(&table[nbucket].lock);
++b->refcnt;
release(&table[nbucket].lock);
}
void
bunpin(struct buf *b) {
int nbucket = b->blockno % NBUCKET;
acquire(&table[nbucket].lock);
--b->refcnt;
release(&table[nbucket].lock);
}
一开始天真地用 malloc 分配 entry 内存,后来突然意识到内核内存布局里好像没有像用户进程一样的堆,内核只能一次性分配整整一页大小的内存块。但幸好 entry 数量和 Buffer cache 的数量是一一对应的,因此可以直接静态分配,于是又改了原来的实现,不然我还暂时真想不到该怎么动态分配 entry。
对于找到最老的且引用数为 0 的 Block cache 的方法,无论是用哪种排序算法(冒泡、归并、快排)都可以。我这里用优先队列是因为实现起来比较简单,而且开销不算太大(但推荐最好是开一个全局的排序数组,把 entries 快排更简洁一些,不同写入队和出队的操作)。在其它高级语言中都有内置的库去提供优先队列的实现,但遗憾的是在 C 只能重复造轮子了,需要注意的是这个优先队列是需要小顶堆实现的,也算是顺带温习数据结构的知识了。
我选了 13 作为哈希桶的数量,因为提示说桶的数量尽量是个质数。为什么最好是质数,我在参考链接附上了这个问题的答案。
初始化结束后,我们的哈希表中没有任何一个 entry,所以一个 bget() 一个都命中不了。这时按照原来的逻辑,程序将会去剔除掉一个引用数为 0 的 Block cache,但由于哈希表是空的,程序会认为剔除失败,直接 panic。这显然不合理,因为我们连一个 Block cache 都没有用,所以在剔除之前我们需要检查是否所有的 Block cache 都是 valid 的。随着系统运行,Buffer cache 很快就会被占满,所以这一步检查执行不了多少次。
重点来了!在运行 bcachetest 后,test0 和 test1 都能顺利执行,没有出现任何 panic 和死锁,但 test0 不意外地挂掉了。test0 给出我们的读写锁一共被竞争了 80多万次,这里 test0 的目标(小于 500次)可是差了将近 1000 倍。
我们不妨计算一下从上电到 test0 结束的这段时间内的 Buffer cache 的命中率。我用了两个计数器变量去记录这里的结果,结果显示 bget() 一共被请求了将近 32000 次,而其中 evict 操作则进行了不到 90次,命中率高达 99.72%。平均 357 次请求中才有一次 evict 请求。很明显,一次 evict 就会自旋很久,大部分的竞争次数都是从这儿来的。那好办,我们就不妨让请求 evict 的进程 sleep 过去,等到没有其它 bget() 请求时再 wakeup 它不就行了么。所以下面这个第二版是改进后的读写锁的获取和释放操作:
void
acquirerwlock(struct rwlock *rwlk, int hit)
{
acquire(rwlk->lock);
if (hit) {
while (rwlk->evicting == 1)
sleep(rwlk, rwlk->lock);
++rwlk->hitting;
} else {
while (rwlk->evicting == 1 || rwlk->hitting != 0)
sleep(rwlk, rwlk->lock);
rwlk->evicting = 1;
}
release(rwlk->lock);
}
void
releaserwlock(struct rwlock *rwlk, int hit)
{
acquire(rwlk->lock);
if (hit) {
if (--rwlk->hitting == 0)
wakeup(rwlk->lock);
} else {
rwlk->evicting = 0;
wakeup(rwlk->lock);
}
release(rwlk->lock);
}
当然,如果你觉得 hit 操作没必要睡你也可以让它自旋。但无论哪个版本,在运行 bcachetest 后,程序直接卡住不动了。hit 操作是很频繁的,这使得没有进程有机会去进行 evict 操作。就算当前没有进行 hit 操作的进程,唤醒然后调度执行的开销是很大的,这期间很有可能又有新的 hit 进程进来,等到 evict 进程醒过来就发现 rwlk->hittng != 0 就又睡了。这里我检查了很多遍没有发现死锁的可能性,很可能是最后大部分进程都没有命中自己想要 Block cache 就都睡掉了,之后也没有进程去唤醒它们。
我们需要去更新策略,要让 evcit 操作的优先级比 hit 操作的优先级更高,即来了一个 evict 操作,如果当前有正在 hit 操作,等到 hit 操作执行完毕后立即响应这个 evict 操作,下面这是第三版改进后的读写锁的获取和释放操作,我们为读写锁增加了一个 evicted 字段:
struct rwlock {
uint evicting;
uint hitting;
uint evicted;
struct spinlock *lock;
};
struct rwlock evict_lock;
struct spinlock _evict_lock;
void
initrwlock(struct rwlock *rwlk, struct spinlock *splk)
{
rwlk->lock = splk;
rwlk->hitting = 0;
rwlk->evicting = 0;
rwlk->evicted = 1;
}
void
acquirerwlock(struct rwlock *rwlk, int hit)
{
acquire(rwlk->lock);
if (hit) {
while (rwlk->evicting != 0)
sleep(rwlk, rwlk->lock);
++rwlk->hitting;
} else {
++rwlk->evicting;
while (rwlk->evicted == 0 || rwlk->hitting != 0)
sleep(rwlk, rwlk->lock);
rwlk->evicted = 0;
}
release(rwlk->lock);
}
void
releaserwlock(struct rwlock *rwlk, int hit)
{
acquire(rwlk->lock);
if (hit) {
if (--rwlk->hitting == 0 && rwlk->evicting == 0)
wakeup(rwlk);
} else {
--rwlk->evicting;
rwlk->evicted = 1;
wakeup(rwlk);
}
release(rwlk->lock);
}
bcachetest 运行顺利,而我们的竞争次数也创新高,达到了 tot= 50236847 这个史无前例的数字。我人都傻了,因为前面分析的和实际不符。把第三版改成全部自旋,竞争次数还有 tot= 487775 这个多;改成 hit 自旋、evict 互斥时,竞争次数为 tot= 49768743;改成 evict 自旋,hit 互斥时,竞争次数为 tot= 22981816。
到这里我真的是万策尽了,终于实在忍不住看了看其他人写的关于这个实验的文章,反正至少我目前看到的当中,都是采用了“局部最优解”的方法通过测试的,虽然我没有找到在找到“全局最优解”的情况下通过测试,但我很难认同这么做就是正确的。因此到这里我只能提供一个思路,自己一个人做这种实验做到这里已经是极限了。
后记
这个锁实验是真的难,不知道是不是我做难了还是有更简单的方法。之前的 Hard 的 Exercise 都是实际编码量不多,但比较难想出来。但这次实验的 Exercise 2 写了三百行左右,还特别难调试,想了好久好久(断断续续大概有三天时间)。期间我中间尝试过用各种方案,先是自旋锁、再是互斥锁、然后读写锁(自旋锁实现),最后在是读写锁(互斥锁实现),还有其它的一些 Bug。这期间竞争频数有过 80多万次、2000多万次、1万多次、5000多万次等,实在是考验人的耐心。我没把这些所有都记录下来是因为太多了……