MySQL索引类型可以分为聚簇索引和非聚簇索引两种。
先谈结论,再去理解:
innodb的次索引指向对主键的引用 (聚簇索引)
myisam的次索引和主索引都指向物理行 (非聚簇索引)聚簇索引
聚簇索引是对磁盘上实际数据重新组织以按指定的一个或多个列的值排序的算法。特点是存储数据的顺序和索引顺序一致。一般情况下主键会默认创建聚簇索引,且一张表只允许存在一个聚簇索引(理由:数据一旦存储,顺序只能有一种)。
聚簇索引和非聚簇索引的区别是:
聚簇索引(innodb)的叶子节点就是数据节点 而非聚簇索引(myisam)的叶子节点仍然是索引文件,只是这个索引文件中包含指向对应数据块的指针。
在《数据库原理》一书中是这么解释聚簇索引和非聚簇索引的区别的:聚簇索引的叶子节点就是数据节点,而非聚簇索引的叶子节点仍然是索引节点,只不过有指向对应数据块的指针。
INNODB和MYISAM的主键索引与二级索引的对比
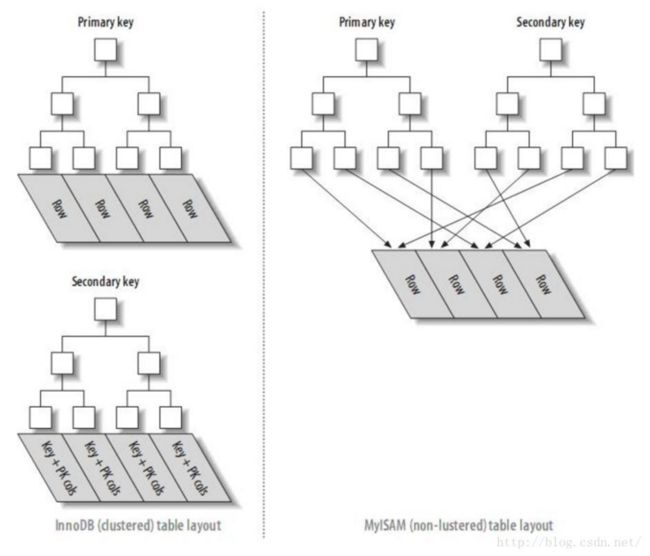
也就是InnoDB的主索引的节点与数据放在一起,次索引的节点存放的是主键的位置。
myisam的主索引和次索引都指向该数据在磁盘的位置。
InnoDB的的二级索引的叶子节点存放的是KEY字段加主键值。因此,通过二级索引询首先查到是主键值,然后InnoDB再根据查到的主键值通过主键索引找到相应的数据块。
而MyISAM的二级索引叶子节点存放的还是列值与行号的组合,叶子节点中保存的是数据的物理地址。所以可以看出MYISAM的主键索引和二级索引没有任何区别,主键索引仅仅只是一个叫做PRIMARY的唯一、非空的索引,且MYISAM引擎中可以不设主键也可以用下面这幅图理解:
首先是myisam的索引主次索引都指向物理行:

InnoDB的主索引叶子节点是主键和数据,次索引指向主键

innodb的主索引文件上 直接存放该行数据,称为聚簇索引,次索引指向对主键的引用
myisam中, 主索引和次索引,都指向物理行(磁盘位置).注意: innodb来说
1: 主键索引既存储索引值又在叶子中存储行的数据。
2: 如果没有主键,则会Unique key做主键
3: 如果没有unique,则系统生成一个内部的rowid做主键。
4: 像innodb中主键的索引,结构中既存储了主键值又存储了行数据,这种结构称为“聚簇索引”。
聚簇索引优势劣势
优势: 根据主键查询条目比较少时,不用回行(数据就在主键节点下)
劣势: 如果碰到不规则数据插入时,造成频繁的页分裂。
聚簇索引的页分裂过程
此时插入一个8,需要将13,16,17移动之后插入8
对于myisam引擎:只需要存储数据之后移动索引节点,
对于innoDb的聚簇索引:插入数据之后需要移动13,16,17.但是因为这三个节点上面有数据,也就造成了额外的开销。相当于三个节点搬家的同时带着数据搬家。
也可以用下图理解:
总结:
1: innodb的buffer_page 很强大.
2: 聚簇索引的主键值,应尽量是连续增长的值,而不是要是随机值,
(不要用随机字符串或UUID)
否则会造成大量的页分裂与页移动.