图文详解神秘的梯度下降算法原理(附Python代码)
作者:FrigidWinter
简介:主攻机器人与人工智能领域的理论研究和工程应用,业余丰富各种技术栈。主要涉足:【机器人(ROS)】【机器学习】【深度学习】【计算机视觉】
专栏:
- 《机器人原理与技术》
- 《计算机视觉教程》
- 《机器学习》
- 《嵌入式系统》
- …
目录
- 1 引例
- 2 数值解法
- 3 梯度下降算法
- 4 代码实战:Logistic回归
1 引例
给定如图所示的某个函数,如何通过计算机算法编程求 f ( x ) m i n f(x)_{min} f(x)min?

2 数值解法
传统方法是数值解法,如图所示
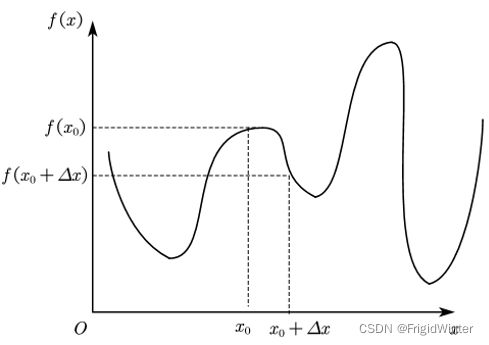
按照以下步骤迭代循环直至最优:
① 任意给定一个初值 x 0 x_0 x0;
② 随机生成增量方向,结合步长生成 Δ x \varDelta x Δx;
③ 计算比较 f ( x 0 ) f\left( x_0 \right) f(x0)与 f ( x 0 + Δ x ) f\left( x_0+\varDelta x \right) f(x0+Δx)的大小,若 f ( x 0 + Δ x ) < f ( x 0 ) f\left( x_0+\varDelta x \right)
④ 重复②③直至收敛到最优 f ( x ) m i n f(x)_{min} f(x)min。
数值解法最大的优点是编程简明,但缺陷也很明显:
① 初值的设定对结果收敛快慢影响很大;
② 增量方向随机生成,效率较低;
③ 容易陷入局部最优解;
④ 无法处理“高原”类型函数。
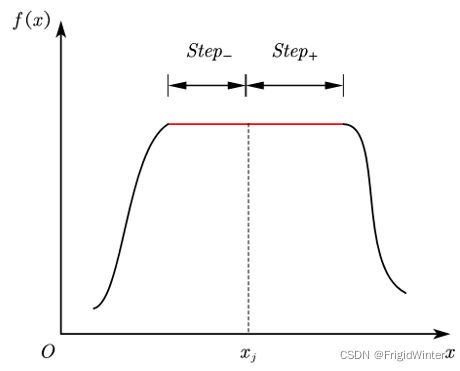
所谓陷入局部最优解是指当迭代进入到某个极小值或其邻域时,由于步长选择不恰当,无论正方向还是负方向,学习效果都不如当前,导致无法向全局最优迭代。就本问题而言如图所示,当迭代陷入 x = x j x=x_j x=xj时,由于学习步长 s t e p step step的限制,无法使 f ( x j ± S t e p ) < f ( x j ) f\left( x_j\pm Step \right)

若出现下图所示的“高原”函数,也可能使迭代得不到更新。
3 梯度下降算法
梯度下降算法可视为数值解法的一种改进,阐述如下:
记第 k k k轮迭代后,自变量更新为 x = x k x=x_k x=xk,令目标函数 f ( x ) f(x) f(x)在 x = x k x=x_k x=xk泰勒展开:
f ( x ) = f ( x k ) + f ′ ( x k ) ( x − x k ) + o ( x ) f\left( x \right) =f\left( x_k \right) +f'\left( x_k \right) \left( x-x_k \right) +o(x) f(x)=f(xk)+f′(xk)(x−xk)+o(x)
考察 f ( x ) m i n f(x)_{min} f(x)min,则期望 f ( x k + 1 ) < f ( x k ) f\left( x_{k+1} \right)
f ( x k + 1 ) − f ( x k ) = f ′ ( x k ) ( x k + 1 − x k ) < 0 f\left( x_{k+1} \right) -f\left( x_k \right) =f'\left( x_k \right) \left( x_{k+1}-x_k \right) <0 f(xk+1)−f(xk)=f′(xk)(xk+1−xk)<0
若 f ′ ( x k ) > 0 f'\left( x_k \right) >0 f′(xk)>0则 x k + 1 < x k x_{k+1}
在工程上,学习率 γ \gamma γ要结合实际应用合理选择, γ \gamma γ过大会使迭代在极小值两侧振荡,算法无法收敛; γ \gamma γ过小会使学习效率下降,算法收敛慢。
对于向量 ,将上述迭代公式推广为
x k + 1 = x k − γ ∇ x k {\boldsymbol{x}_{\boldsymbol{k}+1}=\boldsymbol{x}_{\boldsymbol{k}}-\gamma \nabla _{\boldsymbol{x}_{\boldsymbol{k}}}} xk+1=xk−γ∇xk
其中 ∇ x = ( ∂ f ( x ) ∂ x 1 , ∂ f ( x ) ∂ x 2 , ⋯ ⋯ , ∂ f ( x ) ∂ x n ) T \nabla _{\boldsymbol{x}}=\left( \frac{\partial f(\boldsymbol{x})}{\partial x_1},\frac{\partial f(\boldsymbol{x})}{\partial x_2},\cdots \cdots ,\frac{\partial f(\boldsymbol{x})}{\partial x_n} \right) ^T ∇x=(∂x1∂f(x),∂x2∂f(x),⋯⋯,∂xn∂f(x))T为多元函数的梯度,故此迭代算法也称为梯度下降算法
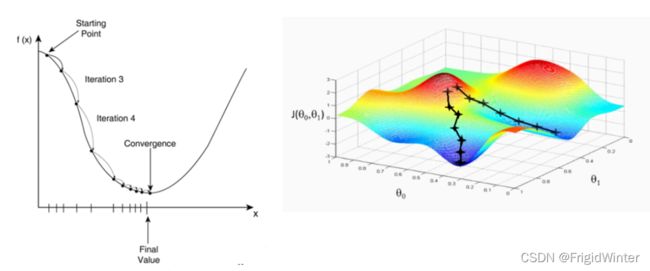
梯度下降算法通过函数梯度确定了每一次迭代的方向和步长,提高了算法效率。但从原理上可以知道,此算法并不能解决数值解法中初值设定、局部最优陷落和部分函数锁死的问题。
4 代码实战:Logistic回归
import pandas as pd
import numpy as np
import os
import matplotlib.pyplot as plt
import matplotlib as mpl
from Logit import Logit
'''
* @breif: 从CSV中加载指定数据
* @param[in]: file -> 文件名
* @param[in]: colName -> 要加载的列名
* @param[in]: mode -> 加载模式, set: 列名与该列数据组成的字典, df: df类型
* @retval: mode模式下的返回值
'''
def loadCsvData(file, colName, mode='df'):
assert mode in ('set', 'df')
df = pd.read_csv(file, encoding='utf-8-sig', usecols=colName)
if mode == 'df':
return df
if mode == 'set':
res = {}
for col in colName:
res[col] = df[col].values
return res
if __name__ == '__main__':
# ============================
# 读取CSV数据
# ============================
csvPath = os.path.abspath(os.path.join(__file__, "../../data/dataset3.0alpha.csv"))
dataX = loadCsvData(csvPath, ["含糖率", "密度"], 'df')
dataY = loadCsvData(csvPath, ["好瓜"], 'df')
label = np.array([
1 if i == "是" else 0
for i in list(map(lambda s: s.strip(), list(dataY['好瓜'])))
])
# ============================
# 绘制样本点
# ============================
line_x = np.array([np.min(dataX['密度']), np.max(dataX['密度'])])
mpl.rcParams['font.sans-serif'] = [u'SimHei']
plt.title('对数几率回归模拟\nLogistic Regression Simulation')
plt.xlabel('density')
plt.ylabel('sugarRate')
plt.scatter(dataX['密度'][label==0],
dataX['含糖率'][label==0],
marker='^',
color='k',
s=100,
label='坏瓜')
plt.scatter(dataX['密度'][label==1],
dataX['含糖率'][label==1],
marker='^',
color='r',
s=100,
label='好瓜')
# ============================
# 实例化对数几率回归模型
# ============================
logit = Logit(dataX, label)
# 采用梯度下降法
logit.logitRegression(logit.gradientDescent)
line_y = -logit.w[0, 0] / logit.w[1, 0] * line_x - logit.w[2, 0] / logit.w[1, 0]
plt.plot(line_x, line_y, 'b-', label="梯度下降法")
# 绘图
plt.legend(loc='upper left')
plt.show()
