关键词学习——激活函数
关注并星标
从此不迷路
计算机视觉研究院

公众号ID|ComputerVisionGzq
学习群|扫码在主页获取加入方式
计算机视觉研究院专栏
作者:Edison_G
最近好多新同学加入了我们,关于一些激活函数的内容,给需要的同学们分享一下!
一、前言
一般激活函数有如下一些性质:
非线性
当激活函数是线性的,一个两层的神经网络就可以基本上逼近所有的函数。但如果激活函数是恒等激活函数的时候,即f(x)=x,就不满足这个性质,而且如果MLP使用的是恒等激活函数,那么其实整个网络跟单层神经网络是等价的;
可微性
当优化方法是基于梯度的时候,就体现了该性质;
单调性
当激活函数是单调的时候,单层网络能够保证是凸函数;
f(x)≈x
当激活函数满足这个性质的时候,如果参数的初始化是随机的较小值,那么神经网络的训练将会很高效;如果不满足这个性质,那么就需要详细地去设置初始值;
输出值的范围
当激活函数输出值是有限的时候,基于梯度的优化方法会更加稳定,因为特征的表示受有限权值的影响更显著;当激活函数的输出是无限的时候,模型的训练会更加高效,不过在这种情况小,一般需要更小的Learning Rate。
Sigmoid
常用的非线性的激活函数,数学形式如下:

Sigmoid 函数曾经被使用的很多,不过近年来,用它的人越来越少了。主要是因为它的缺点(输入较大或较小的时候,最后梯度会接近于0),最终导致网络学习困难。其对x的导数可以用自身表示:

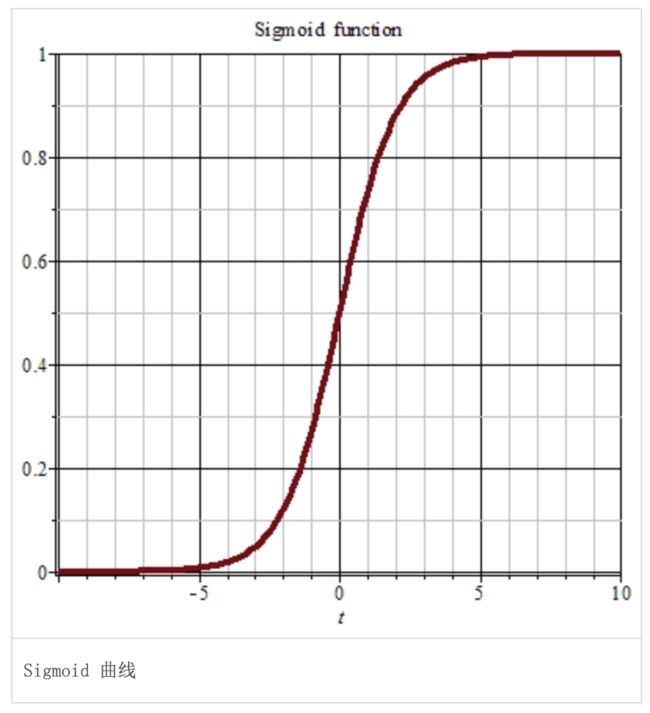
所以,出现了另一种激活函数:ReLU
ReLU
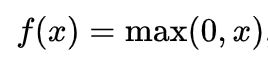
优点:
使用 ReLU得到的SGD的收敛速度会比 sigmoid/tanh 快。这是因为它是linear,而且ReLU只需要一个阈值就可以得到激活值,不用去计算复杂的运算。
缺点:训练过程该函数不适应较大梯度输入,因为在参数更新以后,ReLU的神经元不会再有激活的功能,导致梯度永远都是零。
为了针对以上的缺点,又出现Leaky-ReLU、P-ReLU、R-ReLU三种拓展激活函数。
Leaky ReLUs
该函数用来解决ReLU的缺点,不同的是:
f(x)=αx,(x<0)
f(x)=x,(x>=0)这里的 α 是一个很小的常数。这样,即修正了数据分布,又保留了一些负轴的值,使得负轴信息不会全部丢失。
Parametric ReLU
对于 Leaky ReLU 中的α,通常都是通过先验知识人工赋值,可以观察到损失函数对α的导数是可以求得的,可以将它作为一个参数进行训练。
《Delving Deep into Rectifiers: Surpassing Human-Level Performance on
ImageNet Classification》
该文章指出其不仅可以训练,而且效果特别好。
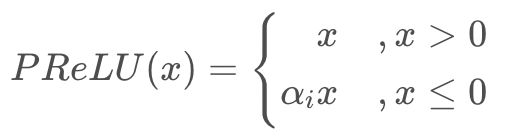
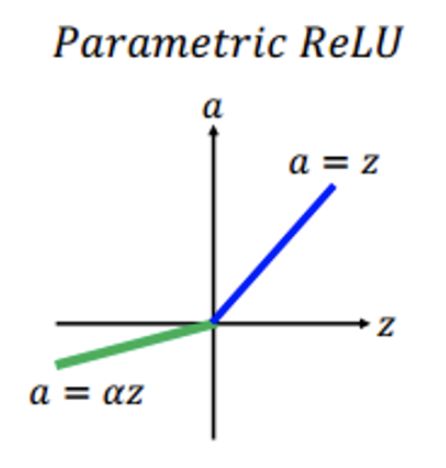
PReLU函数中,参数α通常为0到1之间的数字,并且通常相对较小。
如果αi = 0,则PReLU(x)变为 ReLU。
如果αi > 0,则PReLU(x)变为Leaky ReLU。
如果αi是可学习的参数,则PReLU(x)为PReLU函数。
PReLU函数的特点:
在负值域,PReLU的斜率较小,这也可以避免Dead ReLU问题。
与ELU相比,PReLU 在负值域是线性运算。尽管斜率很小,但不会趋于0。
原文使用了Parametric ReLU后,最终效果比不用提高了1.03%。
Randomized ReLU
Randomized Leaky ReLU 是 Leaky ReLU 的随机版本(α 是随机选取)。它首次是在NDSB 比赛中被提出。
核心思想就是,在训练过程中,α是从一个高斯分布U(l,u)中随机出来的,然后再测试过程中进行修正(与Dropout的用法相似)。
数学表示如下: 
在测试阶段,把训练过程中所有的αji取个平均值。NDSB冠军的α是从 U(3,8) 中随机出来的。
© The Ending
转载请联系本公众号获得授权
![]()
计算机视觉研究院学习群等你加入!
计算机视觉研究院主要涉及深度学习领域,主要致力于人脸检测、人脸识别,多目标检测、目标跟踪、图像分割等研究方向。研究院接下来会不断分享最新的论文算法新框架,我们这次改革不同点就是,我们要着重”研究“。之后我们会针对相应领域分享实践过程,让大家真正体会摆脱理论的真实场景,培养爱动手编程爱动脑思考的习惯!

扫码关注
计算机视觉研究院
公众号ID|ComputerVisionGzq
学习群|扫码在主页获取加入方式