B站弹幕 爬虫+可视化
目录
前言
一、弹幕抓取(有数量限制)
二、弹幕抓取(无数量限制)
成果展示
词云图
饼状图
折线图
前言
想必小破站大家都很熟悉叭,里面充满了各种神奇的视频,其中的弹幕成为了许多人的快乐源泉。关于它的爬虫也有很多,但大部分都受限于弹幕池的数量,只能爬取到其中很少一部分的弹幕。
那么,有没有办法可以爬取到B站更多的弹幕呢?
我们主要用到以下几点知识
1 )爬虫技术
python库: requests , re, jieba,pyecharts,wordcloud
2)分析网站: bill网站特定视频
3)查找数据来源的api: 弹幕数据来源的api
一、弹幕抓取(有数量限制)
我们只需在billbill主页,随便点开一个视频,随后在地址栏的bilibili前加个i,就能获得b站提供的接口
![]()
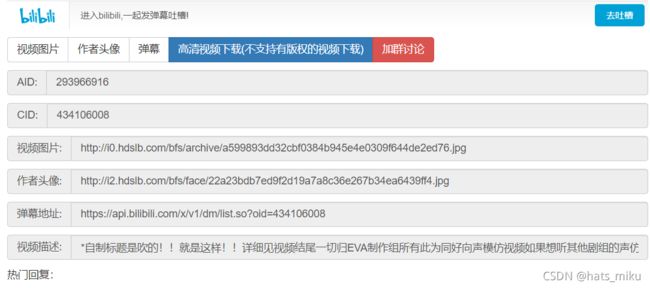
https://api.bilibili.com/x/v1/dm/list.so?oid={oid/cid}可以看到b站提供的接口需要一个名为oid的值,其实我们可以看到这个oid值的和cid的值一样,可以理解为oid=cid,我只要获得其中一个就行
# url = input('请输入B站视频链接: ')
url = 'https://www.bilibili.com/bangumi/play/ss12044/?from=search&seid=11755311719834625120&spm_id_from=333.337.0.0'
res = requests.get(url)
oid = re.findall(r'"cid":(.*?),', res.text)[1]有了cid之后,我们便可以通过刚才发现的弹幕接口爬取网页了,代码如下:
def get_data(oid):
url = f'https://api.bilibili.com/x/v1/dm/list.so?oid={oid}'
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/94.0.4606.71 Safari/537.36',
'cookie':'',
}
response = requests.get(url, headers=headers).content.decode('utf-8')
#print(response) #在控制台打印网页内容
return response那么有了网页,就可以利用正则可以弹幕都提前出来:
def parse_html(response):
pattern = re.compile('(.*?) ')
comments_list = re.findall(pattern, response)
#print(comments_list) #在控制台打印所匹配的内容
return comments_list存储数据
danmus = [','.join(item) for item in comments_list]
headers = ['stime', 'mode', 'size', 'color', 'date', 'pool', 'author', 'dbid', 'text']
headers = ','.join(headers)
danmus.insert(0, headers)
with open('danmus.csv', 'w', encoding='utf_8_sig') as f:
f.writelines([line+'\n' for line in danmus])
二、弹幕抓取(无数量限制)
完整代码可在我的github中下载:https://github.com/hats-miku/Bilibili-danmu-Reptile-visualization
成果展示
词云图


