1. Python 内置数据结构和算法
使用过哪些内置的常用的算法和数据结构
- sorted:排序
- dict、list、set、tuple
[图片上传失败...(image-5a36b9-1593096006911)]
2. collections 模块
官网地址:https://docs.python.org/zh-cn/3/library/collections.html
[图片上传失败...(image-1eac23-1593096006911)]
1、namedtuple
命名元组的工厂函数,添加了通过名字获取值的能力,通过索引值也是可以的:
collections.namedtuple(typename, field_names, *, rename=False, defaults=None, module=None)
# 返回一个新的元组子类,名为 typename 这个新的子类用于创建类元组的对象,可以通过域名来获取属性值,同样也可以通过索引和迭代获取值
>>> import collections
>>> Point = collections.namedtuple('Point', ('x', 'y'))
>>> p = Point(1, 2)
>>> p.x
1
>>> p.y
2
>>> p[0]
1
>>> p[1]
2
2、deque
collections.deque([iterable[, maxlen]])
返回一个新的双向队列对象,从左到右初始化(用方法 append()) ,从 iterable (迭代对象) 数据创建。如果 iterable 没有指定,新队列为空。
常用方法:
| 方法 | 说明 | 方法 | 说明 |
|---|---|---|---|
| append(x) | 添加 x 到右端 | appendleft(x) | 添加 x 到左端 |
| clear() | 移除所有元素,使其长度为0 | copy() | 创建一份浅拷贝。3.5 新版功能. |
| count() | 计算deque中个数等于 x 的元素。3.2 新版功能. | extend(iterable) | 扩展deque的右侧,通过添加iterable参数中的元素。 |
| pop() | 移去并且返回一个元素,deque最右侧的那一个。如果没有元素的话,就升起 IndexError 索引错误。 |
popleft() | 移去并且返回一个元素,deque最左侧的那一个。如果没有元素的话,就升起 IndexError 索引错误。 |
| remove(value) | 移去找到的第一个 value。 如果没有的话就升起 ValueError |
reverse() | 将deque逆序排列。返回 None 。3.2 新版功能. |
| maxlen` | Deque的最大尺寸,如果没有限定的话就是 None 。3.1 新版功能. |
更多方法:https://docs.python.org/zh-cn/3/library/collections.html#collections.deque
>>> de = collections.deque()
>>> de.append(1)
>>> de.append(2)
>>> de.pop()
2
3、Counter
字典的子类,提供了可哈希对象的计数功能(一般用于同级字符串中字符个数):
collections.Counter([iterable-or-mapping])
# 返回字符个数
>>> c = collections.Counter()
>>> c = collections.Counter('abcda')
>>> c
Counter({'a': 2, 'b': 1, 'c': 1, 'd': 1})
# 返回一个列表
>>> c.most_common()
[('a', 2), ('b', 1), ('c', 1), ('d', 1)]
4、OrderedDict
返回一个 dict 子类的实例,它具有专门用于重新排列字典顺序的方法。一般用于 实现 LURcache
collections.OrderedDict([items])
>>> od = collections.OrderedDict()
>>> od['name'] = 'rose'
>>> od['age'] = 18
>>> od['gender'] = 'female'
>>> list(od.keys())
['name', 'age', 'gender']
>>> list(od.values())
['rose', 18, 'female']
move_to_end(key, last=True) 方法
将一个元素移动到队尾(最右边),默认为 last=True,last=False 表示将元素移动到队头(最左边):
od = OrderedDict()
for i in range(5):
od[i] = i**2
print(od) # OrderedDict([(0, 0), (1, 1), (2, 4), (3, 9), (4, 16)])
od.move_to_end(1)
print(od) # OrderedDict([(0, 0), (2, 4), (3, 9), (4, 16), (1, 1)])
od.move_to_end(3, last=True)
print(od) # OrderedDict([(0, 0), (2, 4), (4, 16), (1, 1), (3, 9)])
od.move_to_end(2, last=False) # OrderedDict([(2, 4), (0, 0), (4, 16), (1, 1), (3, 9)])
print(od)
popitem(last=True) 方法
默认从队尾弹出一个元素,last=False 时弹出队头:
od = OrderedDict()
for i in range(5):
od[i] = i**2
print(od) # OrderedDict([(0, 0), (1, 1), (2, 4), (3, 9), (4, 16)])
od.popitem()
print(od) # OrderedDict([(0, 0), (1, 1), (2, 4), (3, 9)])
od.popitem(last=False)
print(od) # OrderedDict([(1, 1), (2, 4), (3, 9)])
5、defaultdict
字典的子类,提供了一个工厂函数,为字典查询提供一个默认值。重载了一个方法并添加了一个可写的实例变量。其余的功能与 dict 类相同。
collections.defaultdict([default_factory[, ...]])
>>> dd = collections.defaultdict(int)
>>> dd['a']
0
>>> dd['b']
0
>>> dd['b'] += 1
>>> dd
defaultdict(, {'a': 0, 'b': 1})
3. dict 底层结构
- 为了支持快速查找使用哈希表作为底层结构
- 哈希表平均查找时间复杂度为
O(1) - cpython 解释器使用二次探查解决哈希冲突问题
问题:哈希表原理,如何解决冲突的,哈希表如何扩容的
4. list 和 tuple 区别
- 都是线性结构,支持下标访问
- list 可变,tuple 保存的引用不可变
- list 不能作为字典 key,tuple 不可变
t = ([1], 2, 3)
t[2] = 4 # 报错
t[0].append(1)
5. LRUCache
由于缓存空间有限,当有新的数据需要加入缓存时,但缓存空间不足时,如何移除原有部分数据从而释放空间来插入新的数据?
LRU(Least Recently Used)算法就是当缓存空间满了的时候,将最近最少使用的数据从缓存空间中删除以增加可用的缓存空间来缓存新数据。
- 缓存剔除策略,当缓存空间不够用的时候需要一种方式剔除 key
- LRU 通过使用一个循环双端队列不断把最新访问的 key 放到表头实现
- 把不怎么使用的放在表尾,经常使用的放在最右边
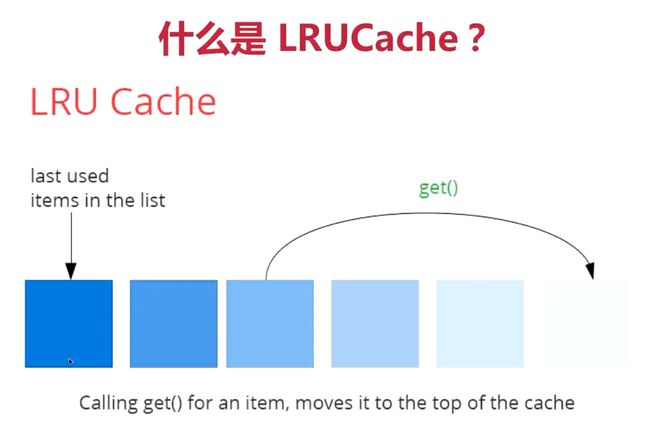
如何实现 LRUCache
字典用来缓存,循环双端链表用来记录访问顺序
- 利用 Python 内置的
dict + collections.OrderedDict实现 - dict 用来当做 k/v 键值对的缓存
- OrderedDict 用来实现更新最近访问的 key
from collections import OrderedDict
class LRUCache:
def __init__(self, capacity=128): # capacity = 128 表示最多有 128 个key、value
self.od = OrderedDict()
self.capacity = capacity
def get(self, key):
"""每次访问更新最新使用的 key"""
if key in self.od:
val = self.od[key]
self.od.move_to_end(key) # 移动到最后,如果不存在报 KeyError
return val
else:
return -1 # 不存在返回 -1
def put(self, key, value):
"""更新 k/v"""
# 更新时如果键队列中有,则删除队列中的,再更新到表头
if key in self.od:
del self.od[key]
self.od[key] = value # 更新 key 到表头
else: # 否则添加新的
self.od[key] = value
# 判断当前容量是否满了
if len(self.od) > self.capacity:
# 当Last参数为False时,说明其是以队列先进先出方式弹出第一个插入字典的键值对
# 而当Last参数为True时,则是以堆栈方式弹出键值对。
self.od.popitem(last=False)
测试代码:
l = LRUCache(5)
# 添加
for i in range(5, 10):
l.put(i, i**2)
print(l.od, l.od.keys())
# 获取
print(l.get(5))
print(l.get(7))
print(l.od, l.od.keys())
# 更新
l.put(6, 100)
print(l.od, l.od.keys())
运行结果:
OrderedDict([(5, 25), (6, 36), (7, 49), (8, 64), (9, 81)]) odict_keys([5, 6, 7, 8, 9])
25
49
OrderedDict([(6, 36), (8, 64), (9, 81), (5, 25), (7, 49)]) odict_keys([6, 8, 9, 5, 7])
OrderedDict([(8, 64), (9, 81), (5, 25), (7, 49), (6, 100)]) odict_keys([8, 9, 5, 7, 6])
在上面我们仅允许最多维护 5 对键值对,当取出 5 和 7时,再查看队列发现 5 和 7 被放到队列右边 。
参考文章:https://www.cnblogs.com/break-python/p/5459169.html
6. 算法常考点
- 排序+查找,重中之重
- 排序:冒泡、快速、归并、堆排序
- 查找:二分查找
- 独立手写代码,能够分析时间空间复杂度
7. 数据结构常考题
- 常见的数据结构:链表、队列、栈、二叉树
- 使用内置结构实现高级数据结构,如:内置的 list/deque 实现栈
- LeetCode 或 剑指 offer 上常见的题
7.1 链表
- 如何使用 Python 表示链表结构
- 链表常见操作:插入、删除、反转、合并多个链表
- LeetCode 练习常见链表题目
7.1.1 链表反转
class ListNode:
def __init__(self, x):
self.val = x
self. next = None
class Solution:
def reverLList(self, head):
"""
:type head: ListNode
:rtype: ListNode
"""
pre = None
cur = head
while cur:
nextnode = cur.next
cur.next = pre
pre = cur
cur = nextnode
return pre
[图片上传失败...(image-1464dc-1593096006911)]
7.1.2 删除一个链表节点
- 熟悉链表定义和常见操作
- 常考题:删除一个链表节点
- 合并两个有序链表
# 不知道 5 前面的数组 4, 1, 5, 9,删除 5
class ListNode:
def __init__(self, x):
self.val = x
self.next = None
class Solution:
def deleteNode(self, node):
nextnode = node.next
after_next_node = node.next.next
node.val = nextnode.val
node.next = after_next_node
7.1.3 合并两个有序链表
1-2-4 1-3-4
输出:1-1-2-3-4-5
class ListNode:
def __init__(self, x):
self.val = x
self.next = None
class Solution:
def mergeTwoLists(self, l1, l2):
root = ListeNode(None)
cur = root
while l1 and l2:
if l1.val < l2.val:
node = ListNode(l1.val)
l1 = l1.next
else:
node = ListNode(l2.val)
l2 = l2.next
cur.next = node
cur = node
# l1 或 l2 可能还有剩余元素
cur.next = l1 or l2
return root.next
7.2 队列
先进先出
- 使用 Python 实现
- append、pop 操作,如何做到先进先出
- 使用 list 或者
collections.deque实现队列 - list 效率不如 deque,头部插入需要将元素换后移动,deque 为双堆队列,头尾都可以插入
from collections import deque
class Queue:
def __init__(self):
self.items = deque()
def append(self, val):
return self.items.append(val)
def pop(self):
return self.items.popleft()
def empty(self):
return len(self.items) == 0
def test_queue():
q = Queue()
q.append(0)
q.append(1)
7.3 栈
后进先出
- Python 如何实现
- push 和 pop 操作,如何做到后进先出
- 使用 list 或
collections.deque实现
要求:空的队列不能调用 pop() 和 top() 方法
from collections import deque
class MyStack:
"""后进先出"""
def __init__(self):
"""
Initialize your data structure here.
"""
self.item = deque()
def push(self, x: int) -> None:
"""
元素 x 入栈
"""
self.item.append(x)
def pop(self) -> int:
"""
移除栈顶元素
"""
if not self.empty():
return self.item.pop()
def top(self) -> int:
"""
获取栈顶元素
"""
if not self.empty():
return self.item[-1]
def empty(self) -> bool:
"""
返回栈是否为空
"""
return len(self.item) == 0
如何实现两个栈实现一个队列?
使用 list 或者 deque(双端队列)来模拟一个栈:
from collections import deque
class MyQueue:
def __init__(self):
"""
Initialize your data structure here.
"""
self.item = deque()
def push(self, x: int) -> None:
"""
将一个元素放入队列的尾部
"""
self.item.append(x)
def pop(self) -> int:
"""
从队列首部移除元素
"""
return self.item.popleft()
def peek(self) -> int:
"""
返回队列首部的元素
"""
return self.item[0]
def empty(self) -> bool:
"""
返回队列是否为空
"""
return len(self.item) == 0
obj = MyQueue()
obj.push(1)
obj.push(2)
obj.push(3)
print(obj.peek()) # 1
print(obj.pop()) # 1
print(obj.empty()) # False
如何获取最小值的栈 MinStack?
7.4 字典与几何
底层是哈希表
- 哈希表实现原理,底层是一个数组
- 根据哈希函数快速定位一个元素,平均查找 O(1),速度非常快
- 不断加入元素会引起哈希表重新开辟空间,拷贝之前元素到新数组
可能会引发的问题:哈希冲突和哈希扩容
哈希冲突
解决办法:链接法和开放寻址法
- 元素key 冲突之后使用一个链表填充相同key 的元素
- 开放寻址法是冲突之后根据一种方法(二次探查)寻址下一个可用的槽
- cpython 使用的二次探查
7.5 数据结构之二叉树
深度遍历分为:先序、中序、后序遍历
[图片上传失败...(image-1e968d-1593096006911)]
7.6 数据结构之堆
堆其实是完全二叉树,有最大和最小堆
最大堆:对于每个非叶子节点 v,v 的值都比它的两个孩子大
基本围绕在合并多个有序(数组、链表) Topk 问题
理解堆的概念:完全二叉树,有最大和最小堆
会使用 Python 内置 heapq 模块实现堆的操作
最大堆支持每次 pop 操作获取最大的元素,最小堆获取最小元素
常见问题:用堆来完成 topk 问题,从海量数字中寻找最大的 k 个
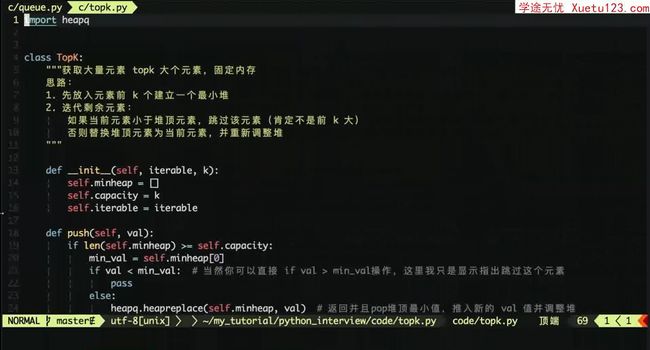
[图片上传失败...(image-4d8e83-1593096006911)]
7.6.1 合并 k 个有序链表 (LeetCode: merge-k-sorted-list )
[图片上传失败...(image-31e1a5-1593096006911)]
# 输入
1-4-5
1-3-4
2-6
# 输出
1-1-2-3-4-4-5-6
解题思路:
- 读取所有链表值
- 构造一个最小堆(heapq 实现)
- 根据最小堆构造一个链表
使用 heapq 模块构建一个最小堆
使得每次都返回堆中最小元素:
>>> import heapq
>>> h = []
>>> h.append(1)
>>> h.append(2)
>>> h.append(5)
>>> h.append(3)
>>> h
[1, 2, 5, 3]
>>> heapq.heapify(h)
>>> heapq.heappop(h)
1
>>> heapq.heappop(h)
2
from heapq import heapify, heappop
class ListNode:
def __init__(self, x):
self.val = x
self.next = None
class Solution:
def mergeKLists(self, lists):
# 读取所有节点值
if not lists:
return None
h = []
for node in lists:
while node:
h.append(node.val)
node = node.next
# 构建一个最小堆
if not h:
return None
heapify(h)
# 构造链表
root = ListNode(heappop(h))
curnode = root
while h:
nextnode = ListNode(heappop(h))
curnode.next = nextnode
curnode = nextnode
return root
7.7 写代码(白板编程)
即手写代码
- 刷题。LeetCode、剑指 offer,看 github 题解
- 大型互联网公司多年经验跳槽处理因为算法挂掉
如何准备:
- 多刷题
- 看剑指 offer
- 整理之前做过的题目,不要靠记忆,考理解
- 大号基础是重要
面试前练习
- 刷题(看面经)
- 剑指 offer 常见题目使用 Python 实现一遍
- 排序算法和数据结构能手写
7.8 二叉树
设计到递归和指针操作,经常结合递归考察
- 二叉树的操作可以有很多可以用递归的方式解决,不了解递归会比较吃力
- 常考题:二叉树的镜像(反转)
- 如何层序遍历二叉树(广度优先)
7.8.1 二叉树的镜像(反转)
[图片上传失败...(image-50fd74-1593096006911)]
class TreeNode:
def __init__(self, x):
self.val = x
self.left = None
self.right = None
class Solution:
def invertTree(self, root):
if root:
root.left, root.right = root.right, root.left
self.invertTree(root.left)
self.invertTree(root.right)
return root
7.8.2 层序遍历二叉树
[图片上传失败...(image-1e7470-1593096006911)]
class TreeNode:
def __init__(self, x):
self.val = x
self.left = None
self.right = None
class Solution:
def leverOrder(self, root):
res = []
cur_nodes = [root]
next_nodes = []
res.append = ([i.val for i in cur_nodes])
while cur_nodes or next_nodes:
for node in cur_nodes:
if node.left:
next_nodes.append(node.left)
if node.right:
next_nodes.append(node.right)
if next_nodes:
res.append(
[i.val for i in next_nodes]
)
cur_nodes = next_nodes
next_nodes = []
return res
7.9 字符串常考算法题
- 了解常用操作、split、upper等
- 题目:反转一个字符串
- 判断一个是否回文
最常用的方法:双端遍历法,分别从前面和后面开始遍历,移动,往中间靠拢
7.9.1 反转字符串
要求:
# 输入
['h', 'e', 'l', 'l', 'o']
# 输出
['o', 'l', 'l', 'e', 'h']
class Solution:
def reverString(self, s):
"""反转字符串"""
beg = 0
end = len(s) - 1
while beg < end:
s[beg], s[end] = s[end], s[beg]
beg += 1
end -= 1
return s
s = Solution()
l = ['h', 'e', 'l', 'l', 'o']
print(l)
ret = s.reverString(l)
print(ret)
7.9.2 判断一串数字是否回文
1、方法一:
class Solution:
def isPalindrome(self, x):
s = str(x)
if len(s) <= 1:
return True
beg, end = 0, len(s) - 1
while beg < end:
if s[beg] == s[end]:
beg += 1
end += 1
return True
else:
return False
return True
s = Solution()
ret = s.isPalindrome(1221)
print(ret)
2、方法二:
使用 collections 模块的 deque:
from collections import deque
d = deque()
def check_string(sting):
"""判断字符串是否为回文"""
for i in sting:
d.append(i)
flag = True
print(d)
while len(d) > 1 and flag:
first = d.popleft()
last = d.pop()
if first != last:
flag = False
return flag
# print(check_string('roll'))
print(check_string('radar'))
首先将所有字符添加到双端队列中,再分别从队列首尾取出一个字符进行比较,若两者相同则继续比较,直至所有字符比较完毕或留出大于 1 的队列。
7.10 练习题
- 反转链表(LeetCode 高频考题 LeetCode reverse-linked-list)
- 使用循环方式?
- 递归方式实现?
8. 面试题
1、手写快排
def quick_sort(li, first, last):
"""快速排序"""
n = len(li)
mid_value = li[first]
low = first
high = last
while low < high and li[high] > mid_Value:
high -= 1
li[low] = li[high]
while low < high and li[low] >
2、手写堆排
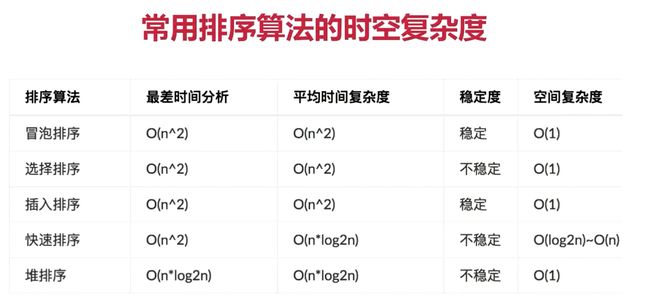
3、几种常见的排序算法复杂度是多少?
[图片上传失败...(image-dc9fa9-1593096006911)]
4、快排平均复杂度是多少?最坏情况如何优化?
- 平均、最好:O(nlogn)
- 最坏:O(n**2)
5、手写,已知一个长度为 n 的无序列表,元素都为数字,要去将所有间隔为 d 的组合找出来,你写的的解法算法复杂度是多少?
def select_d(array, d):
"""找出所有间隔为 2 的组合"""
sum = {}
for i in array:
if i + d in array:
sum[i] = i + d
return sum
array = [1, 2, 3, 4, 5, 6, 7, 8, 9, 0, 1213, 12, 31, 2, 13, 21, 21, 221, 11, 10]
print(select_d(array, 2))
运行结果:
{1: 3, 2: 4, 3: 5, 4: 6, 5: 7, 6: 8, 7: 9, 8: 10, 9: 11, 0: 2, 11: 13, 10: 12}
时间复杂度为 O(n&**2),先拿第一个元素,与后面的 n-1 个元素比较,是否相差 d,是则添加到字典中。而每个元素都要比较,因为这是无序的。
6、手写:一个列表A=[A1,A2,…,An],要求把列表中所有的组合情况打印出来
7、手写:用一行python写出1+2+3+…+10^8**
reduce(lambda x, y: x+y, range(1, 10**8))
8、单向链表长度未知,如何判断其中是否有环
首先遍历链表,寻找是否有相同地址,借此判断链表中是否有环。如果程序进入死循环,则需要一块空间来存储指针,遍历新指针时将其和储存的旧指针比对,若有相同指针,则该链表有环,否则将这个新指针存下来后继续往下读取,直到遇见NULL,这说明这个链表无环。
9、单向链表如何使用快速排序算法进行排序
如果面试官问快速排序是否适合单链表,答案当然是不适合;但是如果问单链表可不可以用快速排序,答案当然是肯定的。
10、
手写:一个长度n的无序数字元素列表,如何求中位数,如何尽快的估算中位数,你的算法复杂度是多少?
11、如何遍历一个内部未知的文件夹(两种树的优先遍历方式)
常用的有以下这几种办法:os.path.walk(),os.walk(),listdir
12、手写:判断一个字符串是否回文?递归方式
def func(s):
if len(s) < 2:
return True
if s[0] != s[-1]:
return False
else:
return func(s[1:-1])
s = 'midim'
print(func(s))
13、堆和栈的区别