【GAN ZOO阅读】Generative Adversarial Nets 生成对抗网络 原文翻译 by zk
摘要
作者提出了一个通过对抗过程来估计生成模型的新框架,文中同时训练两个模型:捕获数据分布的生成模型 G G G,和估计样本是否来自训练数据的概率的判别模型 D D D。 G G G的训练过程是使 D D D犯错误的概率最大化。这个框架就像是对应一个minimax two-player game。在任意函数 G G G和 D D D的空间中,存在一个唯一的解: G G G重新生成训练数据的分布, D D D在任何情况下都等于 1 2 \frac 1 2 21 。(个人理解: D = 1 2 D=\frac 1 2 D=21时无法判定样本是否来源于训练数据,这样便达到了以假乱真的效果。)在 G G G和 D D D由多层感知器定义的情况下,整个系统可以用反向传播来训练。在训练或生成样本期间,不需要任何马尔可夫链或展开的近似推理网络。实验通过定性和定量评估生成的样本来证明框架应用的潜力。
1、概述
深度学习的目标是发现丰富的层次模型[2],它们表示人工智能应用中遇到的各种数据的概率分布,如自然图像,语音音频波形和自然语言语料库中的符号。到目前为止,深度学习中最引人注目的成功是判别式模型,它们通常是那些将高维度、丰富的感知输入映射到类标签的模型[14,22]。这些惊人的成功主要基于反向传播和dropout算法、使用分段线性单元[19,9,10](它们具有特别良好的梯度)。在此之前,基于深度学习的生成模型的影响较小,原因在于很难逼近极大似然估计和相关策略中出现的许多棘手的概率计算,以及难以在生成模型中利用分段线性单元。作者提出了一个新的生成模型的估计程序来回避这些困难。
在作者提出的对抗网络框架中,生成模型与它的“对手”进行对抗,并且有一个判别模型,用于判断样本是来自模型分布还是来自数据分布。生成模型可以被认为是一个“造假者”团队,这个团队试图生成能够以假乱真的假货币,而判别模型可以被认为是“警察”,试图检测假货币。这种竞争促使两个“团队”改进他们的方法,直到“造假者”的产品可以以假乱真。
该框架可以为多种模型和优化算法产生特定训练方法。作者探讨了一种特殊情况:生成模型通过把随机噪声通过多层感知器产生样本,并且判别模型也是多层感知器。作者把这个特殊情况称为对抗网络。在这种情况下,可以使用反向传播和dropout算法来训练这两个模型,并用正向传播从生成模型中产生样本。该模型不需要使用近似推理或马尔可夫链。
2、相关工作
带有潜在变量的有向图模型的替代方法是具有潜在变量的无向图模型,如受限玻尔兹曼机(RBMs)[27,16],深度玻尔兹曼机(DBMs)[26]及其众多变体。这些模型中的相互作用被表示为未归一化的潜在函数的乘积,通过对随机变量的所有状态进行全局总和/积分来归一化。这个数量(分配函数)及其梯度对于大部分情况(除了最平凡的实例外)都是难以处理的,虽然它们可以用马尔可夫链蒙特卡洛(MCMC)方法来估计。Mixing是基于MCMC的学习算法的一个重要问题[3,5]。
深度信赖网络(DBN)[16]是包含单个无向层和多个有向层的混合模型。虽然存在快速近似分层训练标准,但DBN会产生与无向和有向模型相关的计算困难。
不近似或限制对数似然的替代标准也被提出,如分数匹配[18]和噪声对比估计(NCE)[13]。这两个要求学习的概率密度指定达到某个归一化常数。要注意的是,在许多具有多层潜在变量(如DBN和DBM)的有趣的生成模型中,甚至不可能推导出易处理的非标准化概率密度。一些模型,例如去噪自动编码器[30]和收缩自动编码器,其学习规则与应用于RBM的分数匹配非常相似。在NCE中采用判别性训练标准来拟合生成模型。然而,生成模型本身不是用一个单独的判别模型来拟合的,生成模型是用来区分生成的数据与噪声分布的。由于NCE使用固定的噪声分布,所以在模型已经学习了一小部分观测变量的近似正确的分布之后,学习速度就会急剧下降。
最后,一些技术不涉及明确定义的概率分布,而是训练一个生成器从所需的分布中抽取样本。这种方法的优点是可以通过反向传播来训练。在这方面最近的工作突出包括生成乱序网络(GSN)框架[5],它扩展了广义降噪自动编码器[4]:两者都可以被看作是定义一个参数化马尔可夫链,即一个学习机器的参数执行生成马尔可夫链的一个步骤。与GSN相比,对抗网络框架不需要马尔可夫链进行抽样。因为对抗网络在生成过程中不需要反馈循环,所以它们能够更好地利用分段线性单元[19,9,10](这可以提高反向传播的性能),但是当在反馈环路中使用时会遇到无限激活的问题。最近一些通过向后传播来构造生成器的例子包括自动编码变分贝叶斯[20]和随机反向传播[24]方面的工作。
3、对抗网络
当模型都是多层感知器时,对抗建模框架可以被直接使用。为了学习在数据 x x x上的分布 p g p_g pg,在输入噪声变量 p z ( z ) p_z(z) pz(z)上定义一个先验值,然后将对数据空间的映射表示为 G ( z ; θ g ) G(z;θ_g) G(z;θg),其中 G G G是由多层感知器表示的可微分函数。作者还定义了另一个多层感知器 D ( x ; θ d ) D(x;θ_d) D(x;θd),输出一个标量, D ( x ) D(x) D(x)表示 x x x来自数据而不是 p g p_g pg的概率。然后训练 D D D以最大化将正确标签分配给训练样本和来自 G G G的样本的概率,同时训练 G G G以最小化 l o g ( 1 − D ( G ( z ) ) ) log(1-D(G(z))) log(1−D(G(z)))。
换言之, D D D和 G G G用以下的估值函数来玩这个这个two-player minimax game:
(1) min G max D V ( D , G ) = E x ∼ p d a t a ( x ) [ log D ( x ) ] + E z ∼ p z ( z ) [ log ( 1 − D ( G ( z ) ) ) ] . \min_G \max_D V(D, G)=\mathbb E_{x\sim p_{data}\ \ (x)}[\log {D(x)}]+\mathbb E_{z\sim p_z (z)}[\log(1-D(G(z)))].\tag{1} GminDmaxV(D,G)=Ex∼pdata (x)[logD(x)]+Ez∼pz(z)[log(1−D(G(z)))].(1)
在下一节中,作者将对抗网络进行理论分析,表明训练准则能够重新生成数据的分布,因为 G G G和 D D D被给予了足够的能力,也可以说是非参数的极限。图1对此方法进行了一个不是很正式的解释。在实践中,必须使用迭代的数值方法来实现训练的过程。 在训练的内部循环中,完全的优化 D D D在计算上是不可行的,并在有限的数据集上会导致过拟合。相反,作者在优化 D D D的 k k k步和优化 G G G的一步之间交替。只要 G G G足够慢地变化, D D D就能维持在最佳解决方案附近。 这个策略类似于SML/PCD[31,29]训练的方式,从一个学习步骤到下一个学习步骤保持马尔可夫链的样本,为了防止作为学习内循环的一部分在马尔可夫链中burning。算法步骤见算法1。
算法1 GAN的minibatch随机梯度下降训练,判别器训练步数 k k k是一个超参。在作者的实验中 k = 1 k=1 k=1,是最容易的超参。
for number of training iterations do
for k steps do
从先验噪声 p g ( z ) p_g(z) pg(z)中采样出 m m m个样本 { z ( 1 ) , . . . , z ( m ) } \{z^{(1)},...,z^{(m)}\} {z(1),...,z(m)}, m m m是minibatch的大小
从生成的分布 p d a t a ( x ) p_{data}(x) pdata(x)中采样出 m m m个样本 { x ( 1 ) , . . . , x ( m ) } \{x^{(1)},...,x^{(m)}\} {x(1),...,x(m)}
从生成的分布 p d a t a ( x ) p_{data}(x) pdata(x)中采样出 m m m个样本 { x ( 1 ) , . . . , x ( m ) } \{x^{(1)},...,x^{(m)}\} {x(1),...,x(m)}
使用随机梯度下降方法更新判别器: ∇ θ d 1 m ∑ i = 1 m [ log D ( x ( i ) ) + log ( 1 − D ( G ( z ( i ) ) ) ) ] \nabla_{\theta_d}\frac 1 m \sum_{i=1}^{m}[\log D(x^{(i)})+\log(1-D(G(z^{(i)})))] ∇θdm1∑i=1m[logD(x(i))+log(1−D(G(z(i))))]
end for
从先验噪声 p g ( z ) p_g(z) pg(z)中采样出 m m m个样本 { z ( 1 ) , . . . , z ( m ) } \{z^{(1)},...,z^{(m)}\} {z(1),...,z(m)}
通过随机梯度下降法更新生成器 ∇ θ g 1 m ∑ i = 1 m log ( 1 − D ( G ( z ( i ) ) ) ) \nabla_{\theta_g}\frac 1 m \sum_{i=1}^{m}\log(1-D(G(z^{(i)}))) ∇θgm1∑i=1mlog(1−D(G(z(i))))
end for
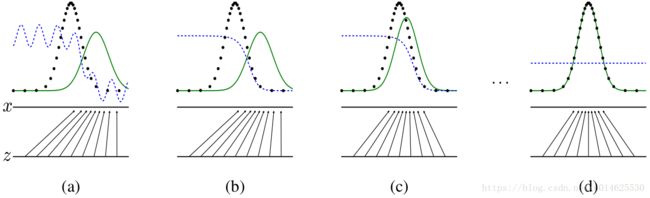
图1:通过实时更新判别分布( D D D,蓝色,虚线)来训练生成对抗网络,用以区分 p g ( G ) p_g(G) pg(G)生成的数据(黑色,虚线)与 p x p_x px中的样本(绿色,实线)。下面的水平线是 z z z的定义域,在这个例子下是均匀分布。上面的水平线是x的定义域的一部分。向上的箭头是映射 x = G ( z ) x = G(z) x=G(z),在变换的样本上施加非均匀分布 p g p_g pg。 G在高密度区域收缩并在低密度区域扩大。
(a)考虑近似收敛的对抗: p g p_g pg与 p d a t a p_{data} pdata相似, D D D是部分准确的分类器。
(b)在算法的内循环中,训练 D D D来区分样本与数据,收敛于 D ∗ ( x ) = p d a t a ( x ) p d a t a ( x ) + p g ( x ) D^∗(x)=\frac {p_{data}(x)}{p_{data}\ (x)+p_{g}(x)} D∗(x)=pdata (x)+pg(x)pdata(x)。
(c)在更新 G G G后, D D D的梯度指导 G ( z ) G(z) G(z)向更可能分类为样本的形状变化。
(d)经过几个步骤的训练,如果G和D有足够的能力,他们将达到两个都不能提高的点,因为 p g = p d a t a p_g = p_{data} pg=pdata。 鉴别器无法区分两种分布,即 D ( x ) = 1 2 D(x)=\frac 1 2 D(x)=21。
4 理论结果
发生器 G G G隐式地将概率分布 p g p_g pg定义为当 z ∼ p z z\sim p_z z∼pz时获得的采样 G ( z ) G(z) G(z)的分布。因此,如果给定足够的样本容量和训练时间,我们希望算法1收敛到一个好的估计值。本章的结果是在非参数设置下完成的,例如,我们通过研究概率密度函数空间中的收敛来表示具有无限容量的模型。4.1节证明了这个minimax游戏对于 p g = p d a t a p_g = p_{data} pg=pdata有一个全局最优值。然后4.2节证明了算法1可以优化公式(1),从而获得期望的结果。
4.1 p g = p d a t a p_g=p_{data} pg=pdata的全局最优性
我们首先考虑任何给定发生器 G G G的最佳判别器 D D D
命题1. 对于固定的 G G G,最优化的判别器 D D D是
(2) D G ∗ ( x ) = p d a t a ( x ) p d a t a ( x ) + p g ( x ) D^∗_G(x)=\frac {p_{\ data}\ \ (x)}{p_{\ data}\ \ (x)+p_{g}(x)}\tag{2} DG∗(x)=p data (x)+pg(x)p data (x)(2)
证明. 给定任何发生器G,鉴别器D的训练准则是最大化 V ( G , D ) V(G, D) V(G,D)
(3) V ( G , D ) = ∫ x p d a t a ( x ) log ( D ( x ) ) d x + ∫ z p z ( z ) log ( 1 − D ( g ( z ) ) ) d z = ∫ x p d a t a ( x ) log ( D ( x ) ) d x + p g ( x ) log ( 1 − D ( x ) ) d x V(G, D)=\int_x p_{data}(x)\log (D(x))dx+\int_z p_{z}(z)\log (1-D(g(z)))dz\\ =\int_x p_{data}(x)\log (D(x))dx+ p_{g}(x)\log (1-D(x))dx \tag{3} V(G,D)=∫xpdata(x)log(D(x))dx+∫zpz(z)log(1−D(g(z)))dz=∫xpdata(x)log(D(x))dx+pg(x)log(1−D(x))dx(3)
对于任意的 ( a , b ) ∈ R 2 \ 0 , 0 (a,b)\in \mathbb{R}^2 \backslash {0,0} (a,b)∈R2\0,0,函数 y → a log ( y ) + b log ( 1 − y ) y \rightarrow a\log{(y)}+b\log{(1-y)} y→alog(y)+blog(1−y)在 [ 0 , 1 ] [0,1] [0,1]区间内的最大值是 a a + b \frac a {a+b} a+ba。这个判别器不需要在 S u p p ( p d a t a ) ⋃ S u p p ( p g ) Supp(p_{data})\bigcup Supp(p_g) Supp(pdata)⋃Supp(pg),证毕。 □ \Box □
值得注意的是, D D D的训练目标可以被解释为最大化估计条件概率 P ( Y = y ∣ x ) P(Y = y|x) P(Y=y∣x)的对数似然性,其中 Y Y Y表示 x x x是来自 p d a t a p_{data} pdata(此时y=1)还是来自 p g p_g pg(此时y=0)。式子1中的minimax游戏现在可以重写为:
(4) C ( G ) = max D V ( G , D ) = E x ∼ p d a t a ( x ) [ log D G ∗ ( x ) ] + E z ∼ p z ( z ) [ log ( 1 − D G ∗ ( G ( z ) ) ) ] = E x ∼ p d a t a ( x ) [ log D G ∗ ( x ) ] + E x ∼ p g ( x ) [ log ( 1 − D G ∗ ( x ) ) ) ] = E x ∼ p d a t a ( x ) [ log p d a t a ( x ) p d a t a ( x ) + p g ( x ) ] + E x ∼ p g ( x ) [ p g ( x ) p d a t a ( x ) + p g ( x ) ] C(G) =\max_D V(G, D) = \mathbb E_{x\sim p_{data}\ \ (x)}[\log {D^∗_G(x)}]+\mathbb E_{z\sim p_z (z)}[\log(1-D^∗_G(G(z)))] \\=\mathbb E_{x\sim p_{data}\ \ (x)}[\log {D^∗_G(x)}]+\mathbb E_{x\sim p_g (x)}[\log(1-D^∗_G(x)))] \\=\mathbb E_{x\sim p_{data}\ \ (x)}[\log {\frac {p_{\ data}\ \ (x)}{p_{data}(x)+p_{g}(x)}}]+\mathbb E_{x\sim p_g (x)}[\frac {p_{g}(x)\ \ }{p_{data}(x)+p_{g}(x)}] \tag{4} C(G)=DmaxV(G,D)=Ex∼pdata (x)[logDG∗(x)]+Ez∼pz(z)[log(1−DG∗(G(z)))]=Ex∼pdata (x)[logDG∗(x)]+Ex∼pg(x)[log(1−DG∗(x)))]=Ex∼pdata (x)[logpdata(x)+pg(x)p data (x)]+Ex∼pg(x)[pdata(x)+pg(x)pg(x) ](4)
定理1. 当且仅当 p g = p d a t a p_g = p_{data} pg=pdata时,训练标准 C ( G ) C(G) C(G)达到全局最小值。 此时 C ( G ) C(G) C(G)大小为 − log 4 - \log4 −log4。
证明. 由公式2,当 p g = p d a t a p_g=p_{data} pg=pdata, D G ∗ ( x ) = 1 2 D^∗_G(x)=\frac 1 2 DG∗(x)=21。因此,当让公式 ( 4 ) (4) (4)中的 D G ∗ ( x ) = 1 2 D^∗_G(x)=\frac 1 2 DG∗(x)=21,我们会得到 C ( G ) = log 1 2 + log 1 2 = − log 4 C(G)=\log \frac 1 2 +\log \frac 1 2=-\log 4 C(G)=log21+log21=−log4。为了说明这是最佳的 C ( G ) C(G) C(G),并且只在 p g = p d a t a p_g=p_{data} pg=pdata时能够取得,观察到
E x ∼ p d a t a [ − log 2 ] + E z ∼ p g [ − log 2 ] = − log 4 \mathbb E_{x\sim p_{data}}[-\log 2]+\mathbb E_{z\sim p_g}[-\log 2]=-\log4 Ex∼pdata[−log2]+Ez∼pg[−log2]=−log4
通过从 C ( G ) = V ( D G ∗ , G ) C(G)=V(D^*_G,G) C(G)=V(DG∗,G)中提取这个式子,我们可以得到:
(5) C ( G ) = − log 4 + K L ( p d a t a ∣ ∣ p d a t a + p g 2 ) + K L ( p g ∣ ∣ p d a t a + p g 2 ) C(G)=-\log 4 + KL(p_{data}||\frac{p_{\ data}\ +p_g}{2})+KL(p_{g}||\frac{p_{\ data}\ +p_g}{2})\tag{5} C(G)=−log4+KL(pdata∣∣2p data +pg)+KL(pg∣∣2p data +pg)(5)
其中 K L KL KL是 Kullback–Leibler散度,即 K L ( P ∣ ∣ Q ) = ∫ P ( x ) log P ( x ) Q ( x ) d x KL(P||Q)=\int P(x)\log \frac {P(x)} {Q(x)}dx KL(P∣∣Q)=∫P(x)logQ(x)P(x)dx。在前面的表达式里,我们已经得到了模型分布与生成分布之间的Jesen-Shannon散度:
(6) C ( G ) = − log 4 + 2 ⋅ J S D ( p d a t a ∣ ∣ p g ) C(G)=-\log4+2·JSD(p_{data}||p_g)\tag{6} C(G)=−log4+2⋅JSD(pdata∣∣pg)(6)
其中 J S D ( P [ ∣ ∣ Q ) = 1 2 K L ( P ∣ ∣ P + Q 2 ) + 1 2 K L ( Q ∣ ∣ P + Q 2 ) JSD(P[||Q)=\frac 1 2KL(P||\frac {P+Q}2)+\frac 1 2KL(Q||\frac {P+Q}2) JSD(P[∣∣Q)=21KL(P∣∣2P+Q)+21KL(Q∣∣2P+Q)。JS散度总是非负的(在 P = Q P=Q P=Q时取 0 0 0)。至此,我们已经证明了 C ( G ) C(G) C(G)的全局最小值是 − log 4 -\log4 −log4,当且仅当 p g = p d a t a p_g=p_{data} pg=pdata,即生成模型是数据的完美重现。
4.2 算法1的收敛性
命题2 如果 G G G和 D D D有足够的能力,且算法1的每一步都能达到给定 G G G的最优值,并且 p g p_g pg被更新,以改善如下判别标准
E x ∼ p d a t a [ log D G ∗ ( x ) ] + E x ∼ p g [ log ( 1 − D G ∗ ( x ) ) ) ] \mathbb E_{x\sim p_{\ data}\ \ }[\log {D^∗_G(x)}]+\mathbb E_{x\sim p_g }[\log(1-D^∗_G(x)))] Ex∼p data [logDG∗(x)]+Ex∼pg[log(1−DG∗(x)))]
则 p g p_g pg 收敛到 p d a t a p_{data} pdata。
证明. 考虑在上面的准则里,当 p g p_g pg的函数 U ( p g , D ) = V ( G , D ) U(p_g, D)=V(G, D) U(pg,D)=V(G,D)。 U ( p g , D ) U(p_g, D) U(pg,D)关于 p g p_g pg是凸的,偏导数在函数的极大值处达到上确界。换言之,若 f ( x ) = sup α ∈ A f α ( x ) f(x)=\sup_{\alpha\in\mathscr A}f_\alpha (x) f(x)=supα∈Afα(x),并且 f α ( x ) f_\alpha (x) fα(x)对每一个 α \alpha α都是凸的, β = arg sup α ∈ A f α ( x ) \beta=\arg\sup_{\alpha\in\mathscr Af_\alpha(x)} β=argsupα∈Afα(x),那么 ∂ f β ( x ) ∈ ∂ f \partial f_\beta (x)\in\partial f ∂fβ(x)∈∂f。这就等效于在 p g p_g pg的最优点,在给定了对应的 G G G时,用梯度下降法更新 p g p_g pg。定理1已经证明了 sup D U ( p g , D ) \sup_DU(p_g, D) supDU(pg,D)是关于 p g p_g pg凸的,并且有唯一的全局最优值,因此如果 p g p_g pg更新速率足够小, p g p_g pg收敛到 p x p_x px,命题得证。 □ \Box □
在实践中,对抗网络通过函数 G ( z ; θ g ) G(z;θ_g) G(z;θg)表示一个有限的 p g p_g pg分布族,优化的是 θ g θ_g θg而不是 p g p_g pg本身。使用多层感知器来定义G在参数空间中引入了多个临界点。多层感知器在实践中的优异表现表明,尽管缺乏理论保证,它们仍是一个合理的使用模型。
5 实验
作者训练了对抗网络的一系列数据集,包括MNIST[23],多伦多人脸数据库(TFD)[28]和CIFAR-10[21]。 生成器网络使用整流器线单元[19,9]和Sigmoid激活的混合,而判别器器网络使用maxout[10]激活。Dropout[17]被应用于训练判别器网络。 虽然理论框架允许在生成器中间层使用dropout和其他噪声,但是作者仅将噪声用于生成器网络最底层的输入。
作者将 G G G生成的样本用高斯Parzen窗拟合,并在这个分布下计算对数似然估计,来估计测试集在 p g p_g pg下的概率。高斯分布的参数 σ \sigma σ由交叉验证获得。这个程序来自Breuleux等人[8],并在多种难以得到确切似然的生成模型中使用[25,3,5]。最后的结果如表1所示。这种估计可能性的方法具有较高的方差,并且在高维空间中表现不佳,但是这是所知道的最好的方法。抽样但不直接估计似然的生成模型的进展,促进了如何评估这类模型的进一步研究。
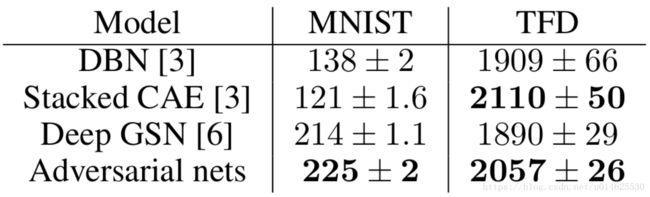
表1:基于Parzen窗的对数似然估计。在MNIST上报告的数字是样本在测试集合上的平均对数似然,及在样本均值上计算的标准差。在TFD上,作者计算了数据集不同折的标准误差,每个折的验证集合选择不同的 σ σ σ。 在TFD上,每次交叉验证 σ σ σ,并计算每折的平均对数似然。对于MNIST,作者使用真实数值(而不是二分类)版本的数据集与其他模型进行比较。
在图2和图3中,作者展示了训练后从生成网络中抽取的样本。虽然作者没有证明这些样本比现有方法产生的样本更好,但作者认为这些样本至少与其他文献中的生成模型相竞争,并突出了对抗框架的潜力。

图2: 模型生成的图像。最右边的列显示了它旁边的生成样本的最邻近训练样本,以证明模型不是在复制训练集。样本是公平的随机抽签,而不是精心挑选的。与大多数其他深度生成模型的可视化不同,这些图像显示了生成的实际样本,而不是给定隐藏单元样本的条件均值。此外,这些样本是不相关的,因为抽样过程不依赖于马尔可夫链混合。
a)MNIST
b)TFD
c)CIFAR-10(全连接模型)
d)CIFAR-10(卷积判别器和“去卷积”生成器)
![]()
6 优势和劣势
这个新的框架与先前的建模框架相比具有优点和缺点。缺点主要是没有 p g ( x ) p_g(x) pg(x)的明确表示,并且在训练期间 D D D必须与 G G G很好地同步(特别是,为了避免“Helvetica Scenario”(hhh这是个英国的梗),当 D D D不更新时, G G G不能被更新地训练太多,否则当 x x x相同时, G G G丢失太多 z z z,以至于模型 p d a t a p_{data} pdata没有足够的多样性。),就像玻尔兹曼机器的负链必须在学习步骤之间更新一样。它的优点是不需要马尔可夫链,只有反向传播被用来获得梯度,在学习过程中不需要推理,并且可以将各种各样的功能结合到模型中。表2总结了生成对抗网络与其他生成式方法的比较。
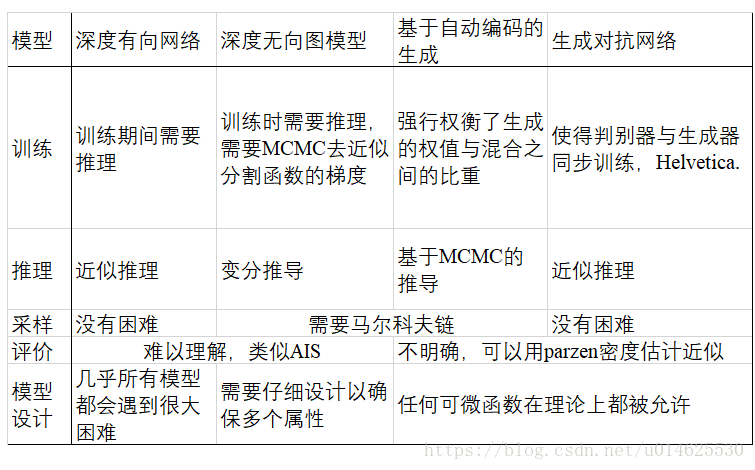
表2 生成建模方面的挑战:对不同深度生成方法的主要操作遇到的困难的总结。
上述优点主要是计算性的。对抗模型也可以从生成网络获得一些统计上的优点,而不是直接用样本数据更新,而只是通过判别器中流动的梯度。这意味着输入的组件不会直接复制到生成器的参数中。对抗网络的另一个优点是它们可以表示非常尖锐甚至退化的分布,而基于马尔可夫链的方法要求分布有些模糊,以便链能够在模式之间进行混合。
7 结论与未来的工作
这个框架可以有许多直接的扩展:
- 条件生成模型 p ( x ∣ c ) p(x|c) p(x∣c)可以通过将 c c c作为输入添加到 G G G和 D D D来获得。
- 给定 x x x,学习近似推理可以通过训练一个辅助网络来预测 z z z。 这与wake-sleep算法[15]训练的推理网络类似,但是其优点是可以在生成网络完成训练之后对固定的生成网络训练推理网络。
- 可以通过训练一系列共享参数的条件模型来近似地模拟所有条件 p ( x S ∣ x \ S ) p(x_S|x_{\backslash S} ) p(xS∣x\S),其中S是x的下标的子集。 从本质上讲,可以使用对抗网络来实现确定性MP-DBM的随机扩展[11]。
- 半监督学习:当有限的标记数据可用时,来自鉴别器或推理网络的特征可以改善分类器的性能。
- 提高效率:通过分配更好的协调 G G G和 D D D的方法,或者在训练期间确定样本 z z z的更好的分布,可以大大加速训练。
本文已经证明了对抗建模框架的可行性,表明这些研究方向可能是有用的。
致谢
感谢Patrice Marcotte,Olivier Delalleau,Kyunghyun Cho,Guillaume Alain和Jason Yosinski进行有益的讨论。 Yann Dauphin分享了他的Parzen窗口评估代码。要感谢Pylearn2 [12]和Theano [7,1]的开发人员,特别是Fredric Bastien,他特别为了这个项目而特意丰富了Theano功能。 Arnaud Bergeron为LATEX排版提供了急需的支持。还要感谢CIFAR和加拿大研究会的资助,加拿大计算机学会和Calcul Quebec提供计算资源。Ian Goodfellow受到2013年深度学习谷歌奖学金的支持。最后,要感谢Les Trois Brasseurs激发的创造力。
参考文献
[1] Bastien, F., Lamblin, P., Pascanu, R., Bergstra, J., Goodfellow, I. J., Bergeron, A., Bouchard, N., and Bengio, Y. (2012). Theano: new features and speed improvements. Deep Learning and Unsupervised Feature Learning NIPS 2012 Workshop.
[2] Bengio, Y. (2009). Learning deep architectures for AI. Now Publishers. [3] Bengio, Y., Mesnil, G., Dauphin, Y., and Rifai, S. (2013a). Better mixing via deep representations. In ICML’13.
[4] Bengio, Y., Yao, L., Alain, G., and Vincent, P. (2013b). Generalized denoising auto-encoders as generative models. In NIPS26. Nips Foundation.
[5] Bengio, Y., Thibodeau-Laufer, E., and Yosinski, J. (2014a). Deep generative stochastic networks trainable by backprop. In ICML’14.
[6] Bengio, Y., Thibodeau-Laufer, E., Alain, G., and Yosinski, J. (2014b). Deep generative stochastic networks trainable by backprop. In Proceedings of the 30th International Conference on Machine Learning (ICML’14).
[7] Bergstra, J., Breuleux, O., Bastien, F., Lamblin, P., Pascanu, R., Desjardins, G., Turian, J., Warde-Farley, D., and Bengio, Y. (2010). Theano: a CPU and GPU math expression compiler. In Proceedings of the Python for Scientific Computing Conference (SciPy). Oral Presentation.
[8] Breuleux, O., Bengio, Y., and Vincent, P. (2011). Quickly generating representative samples from an RBM-derived process. Neural Computation, 23(8), 2053–2073.
[9] Glorot, X., Bordes, A., and Bengio, Y. (2011). Deep sparse rectifier neural networks. In AISTATS’2011.
[10] Goodfellow, I. J., Warde-Farley, D., Mirza, M., Courville, A., and Bengio, Y. (2013a). Maxout networks. In ICML’2013.
[11] Goodfellow, I. J., Mirza, M., Courville, A., and Bengio, Y. (2013b). Multi-prediction deep Boltzmann machines. In NIPS’2013.
[12] Goodfellow, I. J., Warde-Farley, D., Lamblin, P., Dumoulin, V., Mirza, M., Pascanu, R., Bergstra, J., Bastien, F., and Bengio, Y. (2013c). Pylearn2: a machine learning research library. arXiv preprint arXiv:1308.4214.
[13] Gutmann, M. and Hyvarinen, A. (2010). Noise-contrastive estimation: A new estimation principle for unnormalized statistical models. In AISTATS’2010.
[14] Hinton, G., Deng, L., Dahl, G. E., Mohamed, A., Jaitly, N., Senior, A., Vanhoucke, V., Nguyen, P., Sainath, T., and Kingsbury, B. (2012a). Deep neural networks for acoustic modeling in speech recognition. IEEE Signal Processing Magazine, 29(6), 82–97.
[15] Hinton, G. E., Dayan, P., Frey, B. J., and Neal, R. M. (1995). The wake-sleep algorithm for unsupervised neural networks. Science, 268, 1558–1161.
[16] Hinton, G. E., Osindero, S., and Teh, Y. (2006). A fast learning algorithm for deep belief nets. Neural Computation, 18, 1527–1554.
[17] Hinton, G. E., Srivastava, N., Krizhevsky, A., Sutskever, I., and Salakhutdinov, R. (2012b). Improving neural networks by preventing co-adaptation of feature detectors. Technical report, arXiv:1207.0580.
[18] Hyvärinen, A. (2005). Estimation of non-normalized statistical models using score matching. J. Machine Learning Res., 6.
[19] Jarrett, K., Kavukcuoglu, K., Ranzato, M., and LeCun, Y. (2009). What is the best multi-stage architecture for object recognition? InProc.International Conference on Computer Vision (ICCV’09), pages 2146–2153…
[20] Kingma, D. P. and Welling, M. (2014). Auto-encoding variational bayes. In Proceedings of the International Conference on Learning Representations (ICLR).
[21] Krizhevsky, A. and Hinton, G. (2009). Learning multiple layers of features from tiny images. Technical report, University of Toronto.
[22] Krizhevsky, A., Sutskever, I., and Hinton, G. (2012). ImageNet classification with deep convolutional neural networks. In NIPS’2012.
[23] LeCun, Y., Bottou, L., Bengio, Y., and Haffner, P. (1998). Gradient-based learning applied to document recognition. Proceedings of the IEEE, 86(11), 2278–2324.
[24] Rezende, D. J., Mohamed, S., and Wierstra, D. (2014). Stochastic backpropagation and approximate inference in deep generative models. Technical report, arXiv:1401.4082.
[25] Rifai, S., Bengio, Y., Dauphin, Y., and Vincent, P. (2012). A generative process for sampling contractive auto-encoders. In ICML’12.
[26] Salakhutdinov, R. and Hinton, G. E. (2009). Deep Boltzmann machines. In AISTATS’2009, pages 448–455.
[27] Smolensky, P. (1986). Information processing in dynamical systems: Foundations of harmony theory. In D. E. Rumelhart and J. L. McClelland, editors, Parallel Distributed Processing, volume 1, chapter 6, pages 194–281. MIT Press, Cambridge.
[28] Susskind, J., Anderson, A., and Hinton, G. E. (2010). The Toronto face dataset. Technical Report UTML TR 2010-001, U. Toronto.
[29] Tieleman, T. (2008). Training restricted Boltzmann machines using approximations to the likelihood gradient. In W. W. Cohen, A. McCallum, and S. T. Roweis, editors, ICML 2008, pages 1064–1071. ACM.
[30] Vincent, P., Larochelle, H., Bengio, Y., and Manzagol, P.-A. (2008). Extracting and composing robust features with denoising autoencoders. In ICML 2008.
[31] Younes, L. (1999). On the convergence of Markovian stochastic algorithms with rapidly decreasing ergodicity rates. Stochastics and Stochastic Reports, 65(3), 177–228.