by hzwusibo 20190301
一、sdk简介:
二、epub科普
三、解析器sdk设计
四、epub解析的原理:
五、sdk如何接入与基本使用
一、sdk简介:
a、目前支持的格式: 标准epub, 云阅读定制epub, html, doc, txt, umd等格式。
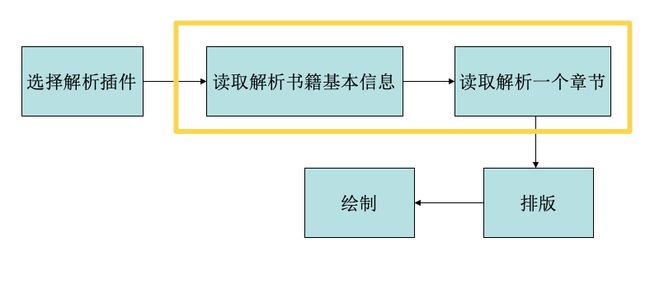
b、作用: 解析主要作用在于获取书籍基本信息、解析章节内容。
书籍打开流程(解析、绘制等)如下图所示:
c、解析器sdk用例图:

二、epub科普(此处很有必要,插播一段epub的科普,已经熟悉的可以跳过此段)
a、 epub全称为Electronic Publication的缩写,意为:电子出版, epub于2007年9月成为国际数位出版论坛(IDPF)的正式标准,以取代旧的开放Open eBook电子书标准。 一个 EPUB 就是一个简单 ZIP 格式文件(使用 .epub 扩展名),其中包括按照预先定义的方式排列的文件。(EPUB 非常简单。只需将后缀改为.zip或.rar,解压即可看到里面的文件内容)。
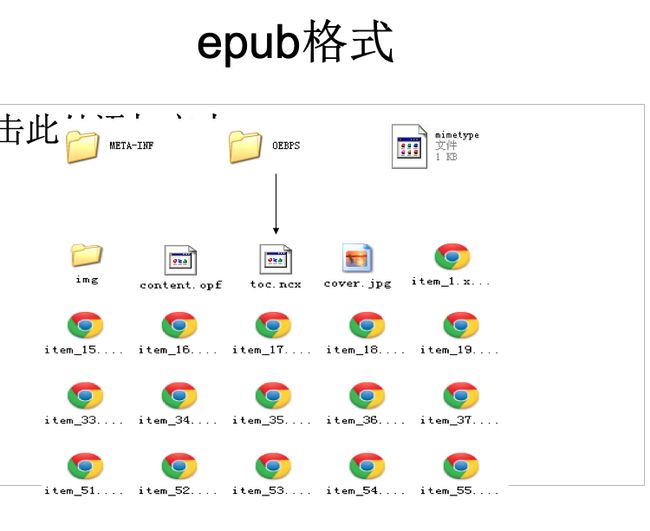
一个epub电子书的zip大致包含以下东西:
1、每一本epub电子书均包含一个名为mimetype的文件,且内容不变,用以说明epub的文件格式。
2、META-INF用于存放容器信息,该目录包含一个文件,即container.xml。(container.xml的主要功能用于告诉阅读器,电子书的根文件(rootfile)的路径和打开放式,一般来讲,该container.xml文件也不需要作任何修改,除非你改变了根文件的路径和文件名称)。

3、 OEBPS目录用于存放OPS文档、OPF文档、NCX文档、CSS文档等( OEBPS这个名字是可变的,可以根据containter.xml进行配置)。
OEBPS目录包含了:
image子目录(不一定总有)存放了所有的图片文件
content.opf , OPF文档是epub电子书的核心文件,且是一个标准的XML文件,依据OPF规范
toc.ncx 目录文件,ncx文件是epub电子书的又一个核心文件,用于制作电子书的目录,其文件的命名通常为toc.ncx。
一些xhtml或html文件。就是书的内容。
b、 content.opf:

包括四个元素:metadata, manifest, spine, guide
(1)metadata: epub的元数据,如title、language、identifier、cover等。其中title 和 identifier这两个数据是必须的。
(2)manifest:列出了目录中所包含的所有文件(xhtml、css、png、ncx等)。
(3)spine:所有xhtml文档的线性阅读顺序。其中,spine标签的toc属性必须包含在manifest列出来的.ncx的id。可以将 OPF spine 理解为是书中 “页面” 的顺序,解析的时候按照文档顺序从上到下依次读取 spine。
c、toc.ncx

ncx 定义了数字图书的目录表。复杂的图书中,目录表通常采用层次结构,包括嵌套的内容、章和节。
d、spine和ncx文件有什么不同?(后面经常用到)
Spine标签描述文档顺序,ncx文件描述目录。
两者很容易混淆,因为两个文件都描述了文档的顺序和内容。要说明两者的区别,最简单的办法就是拿印刷书来打比方:.opf文件的spine标签描述了书中的各个章节是如何实际连接起来的,比方说翻过第一章的最后一页就看到第二章的第一页。.ncx在图书的一开始描述了目录,目录肯定会包含书中主要的章节,但是还可能包含没有单独分页的小节。(一条法则是ncx包含的 navPoint 元素通常比 opf spine中的itemref 元素多。实际上,spine 中的所有项都会出现在 .ncx 中,但.ncx可能更详细。)
参考文献:https://www.cnblogs.com/diligenceday/p/4999315.html
三、解析器sdk设计
a、类图:

IParser 为解析器接口 (解析器对外提供的方法都在此), BookParser帮助接入端获取书籍解析器对象,包含很多get方法(如 getPrisOfOnlineEpubParser()获取云阅读定制epub解析器,getTxtParser()获取txt解析器,getEpubParser()标准epub书籍解析器等)获取解析器后能够使用IParser中提供的方法,进行解析与获取章节的内容。 所有的解析器都继承了抽象父类ParserBase(解析器公共的方法在父类中实现,子类继承父类只需要实现各自不同的部分,如iniBook(), getChapter()方法等)。
ps. 接入端可以传入IMyNCXReader接口的实现类给PrisOfOnlineEpubParser进行外部解析目录、书籍信息等任务。
b、工程结构:
对外部分:
IParser解析器接口
BookParser获取书籍解析器对象
ICacheHelp设置解析存储(缓存)地址(书籍文件所在地址、 接入时候需要设置解析后文件存储地址等)
ILogHelp设置Log日志(打印log日志)
云阅读epub解析器除了支持解析epub中目录,也可以由接入端进行解析, 必须实现ISrNCXReader接口,例如蜗牛自己实现(接入端),云阅读解析epub中目录l实现)。

对内部分:
book包主要是解析的具体实现
cache包为缓存
log包为日志
parser包里是各种解析器类(当前支持的解析器类型)
util包为工具类。
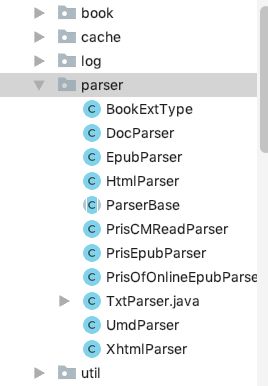
c、解析器中二个重要的model类(Book和 Navpoint)
其中Book为书籍基本信息model类, Navpoint目录orSpine基本信息model类。

(1) Book 书的信息包括书名, 作者, 封面,目录结构等。

解析器解析书籍信息赋值给Book类的对象,如epub的基本信息、封面信息、目录等。

关健代码:
其中 epub是通过解析epub自身content.opt文件得到Book类对象的信息。
云阅读epub解析器支持接入端解析(需要实现IMyNCXReader接口)。
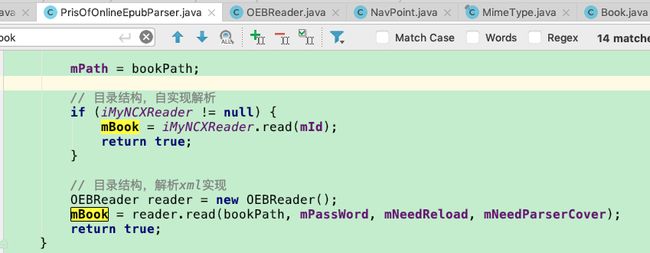
(2) Navpoint 为目录toc或者章节spine的model类,包括章节id,url等信息

d、IParser解析器对外接口 (调用函数列表)

1、String createId(String path, String id); 生成id
2、int getVersion(); 解析器版本
3、boolean canAcceptType(MimeType mime, MimeType subMime, String extType); 解析器是否支持传入的mime类型和扩展类型
4、boolean openBook(String path, String passWord, String id, boolean needReload, boolean needParserCover, boolean isPerfect); 打开书籍,解析书籍信息、spine以及toc等
5、 void closeBook(); 关闭书籍,释放资源
6、String getId(); 获取唯一ID
7、int getChapterType(); 每个章是否需要独立排版, txt等类型, 没有明确的章概念, UI可能需要连续排版
8、PrisTextChapter getChapter(NavPoint point, String password, String targetCssName); 获取一章内容
9、Bitmap getImage(String imgRef, float width, float height, BitmapFactory.Options opts); 根据图片索引获取图片(不同parser对图片的解码可能存在差异)
10、Bitmap getOriginalImage(String imageRef); 获取原始图片
11、Book getBookInfo(); 获取书的信息(书名, 作者, 封面...)
12、List
13、List
14、void beginSearch(String key); 搜索相关
15、TextSearchInfo SearchUp(); 搜索相关
16、TextSearchInfo SearchDown(); 搜索相关
17、void endSearch();
18、NavPoint getSpineNavPoint(int index); 通过章节索引获取spine的NavPoint节点
19、NavPoint getSpineNavPoint(String id); 通过Spine的ID获取spine的NavPoint节点(兼容老版本,数据库没有索引字段)
20、NavPoint getPreSpineNavPoint(int index); 通过Spine索引获取spine的前一个NavPoint节点
21、NavPoint getNextSpineNavPoint(int index); 通过Spine索引获取spine的下一个NavPoint节点
22、NavPoint getTocNavPoint(int index); 通过toc索引获取toc的NavPoint节点
23、NavPoint getTocNavPoint(String id); 通过toc的ID获取toc的NavPoint节点
24、int getChapterSize(); 获取章节数量(表示书籍阅读顺序的spine节点数)
25、NavPoint getTocNavPointBySpine(NavPoint point, Object... obj); 通过spine的NavPoint节点获取对应的toc的NavPoint节点
26、NavPoint getSpineNavPointByToc(NavPoint point); 通过toc的NavPoint节点获取对应的spine的节点
27、String getUnfoldBookPath();
四、epub解析的原理:
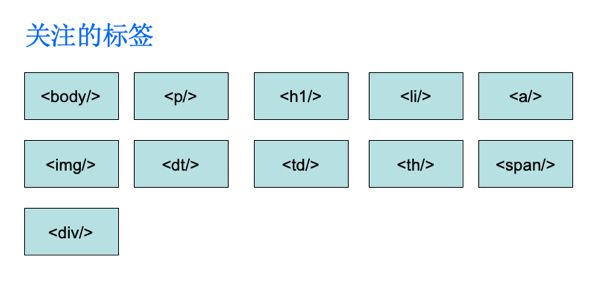
解析章节内容有点类似于解析h5。一个章节内容的文件如下图所示。

主要是关注里面的标签,类似于h5 文件。
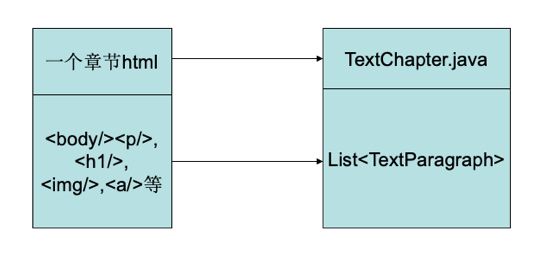
通过标签对文件进行解析,解析成段落的集合。得到一个TextParagraph的list。
EpubParser解析器关健代码:
ParserBase 是txt, umd, doc, epub解析器的基类(抽象类),继承自IParser接口,实现了其中一些公共的方法。
其中比较重要的是openBook方法,具体的实现在各种子类的iniBook方法中。
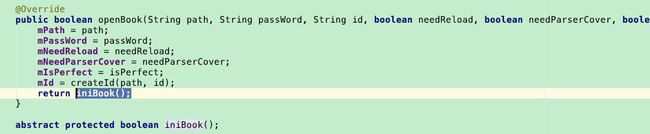
EpubParser中通过OEBReader类读取opf文件,获取书籍信息和目录等信息(类似xml解析)。

canAcceptType()方法能够通过传入参数判断解析器是否支持当前类型。

getChapter()方法是根据目录Navpoint获取对应章节的对象,通过NEFile类读取文件(类似xml解析)

ps. epub具体解析代码见下图中的类

五、sdk如何接入与基本使用
a、接入:
(1) 引入解析器aar文件

(2) 在app中进行初始化
(3) 接入端可以使用一个ManagerBookParser类进行统一管理
下图为蜗牛的ManagerBookParser类,在Manager类中设置初始化任务(init方法)与缓存地址(CacheHelp),获取解析器类型(getParser方法)。 其中getBaseRootExternalDir()为解析后文件存储地址(内部存储/data/data/packageName路径),getBookChapterPath(String s, String s1)书籍文件所在地址。
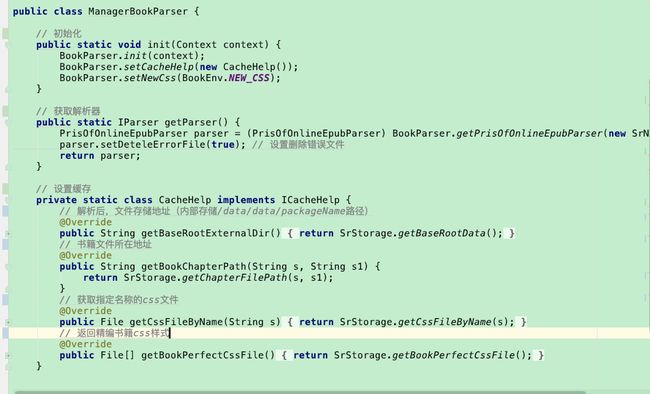
云阅读支持的类型更多(txt、epub等):

b、使用:
以蜗牛为例 , ReadbookNewActivity类中:
(1) 声明
(2) 获取解析器实例。

(3) 调用解析器的openBook方法进行书籍解析。(必须)
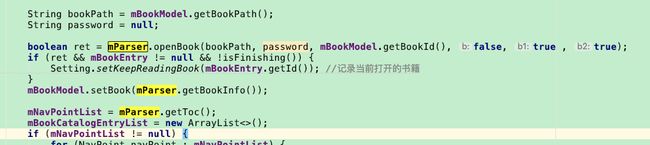
(4) openBook完成后,可以调用getBookinfo()方法获取到书籍信息(包含title、封面、作者、 目录等)。

(5) 通过getToc() 方法可以获取目录list。
(6) getToc() 方法得到Navpoint的list集合(目录)

(7) 、getchapter()方法可以通过传入想获取章节的目录和密码,得到解析后的章节实例prisTextChapter。(password只有云阅读epub需要传入,其他解析器传入null或者“”即可)。
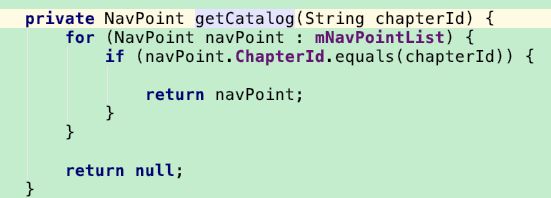
其中传入参数为navpoint(可以根据id获取对应章节navpoint)
getCatalog方法如下,通过id对比得到。
(8) 在ondestry中销毁。

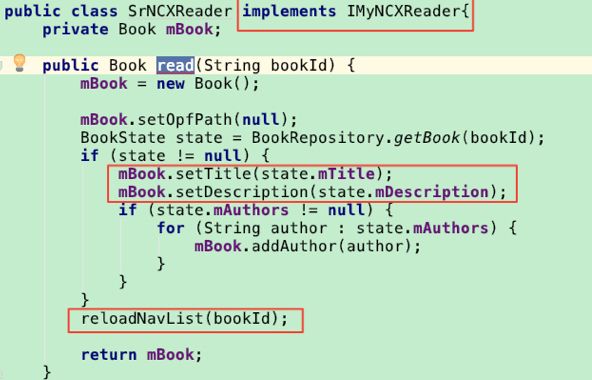
ps 前面说了,云阅读定制epub解析器除了支持解析epub中目录,也可以由接入端进行解析, 必须实现ISrNCXReader接口,其中read()方法为获取书籍的信息与目录

可以看到BookParser中PrisOfOnlineEpubParser有两个get方法,其中可以传入参数,一个无参数。 (云阅读调的第一个,蜗牛调的第二个。)

蜗牛传入了SrNCXReader类的实例。

SrNCXReader实现了IMyNCXReader接口,read方法通过解析json方式实现了获取书籍的信息与目录。