前言
机器学习的本质是信息论。在信息论中,首先我们引入了信息熵的概念。认为一切信息都是一个概率分布。所谓信息熵,就是这段信息的不确定性,即是信息量。如果一段信息,我无论怎么解读都正确,就没有信息量。如果一个信息,我正确解读的概率极低,就包含了极大信息量。这个信息量即是一段信息的不确定性即是“信息熵”。
信息熵
事件的概率分布和每个事件的信息量构成了一个随机变量,这个随机变量的均值(即期望)就是这个分布产生的信息量的平均值(即熵)
举个例子:
在某音乐APP中,当用户听歌时,遇到喜欢的歌可能会点喜欢按钮。但我们并不能保证用户100%是因为喜欢这首歌才点喜欢按钮的。
那么,用户点击喜欢这件事,到底给我们带来了多少信息呢?
我们对用户的心理作如下假设:1/2是真的喜欢,1/4是随便点的,1/4不喜欢。

此时,用户点击了喜欢,如果让一个程序员来猜测,用户的真实想法。他总共需要猜多少次呢?
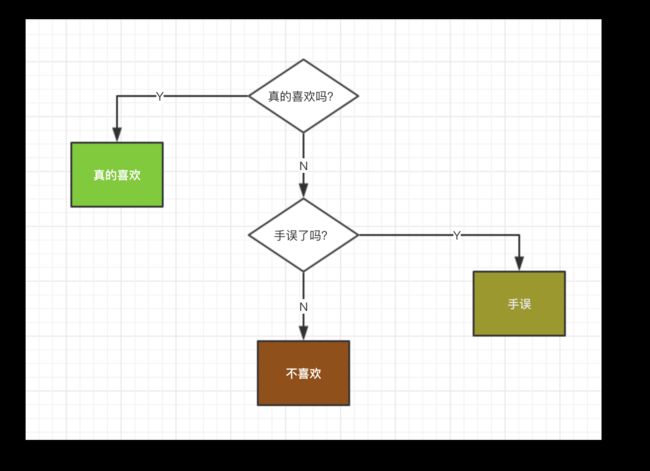
在这样的情况下,程序员会先猜,用户是不是真的喜欢?有1/2的概率直接就猜对了,一次成功。也有1/2的概率不成功,那么有1/4的概率,再猜一次,能猜中用户是随便点的,另外1/4的概率再猜一次,确认用户不喜欢。

猜完两次,这个信息就是100%确定的啦。我们对猜测次数的期望做一下计算,它就是这个概率分布的信息熵。
信息熵为:
1/2 * 1 + 1/4 * 2 + 1/4 * 2 = 1.5
先猜是不是喜欢,再猜是不是随便点的。1/2概率一次猜中真的喜欢,1/4的概率两次猜中随便点的,1/4的概率两次猜中不喜欢。
仔细想想,机器学习是不是就是在做着这个猜测的工作?
交叉熵
有了信息熵,就会有新的问题。那么,一段信息的概率分布是A。而我用概率分布B去计算信息熵时,即是交叉熵。交叉熵,一定大于信息熵,可以理解为信息熵是交叉熵的理想情况。
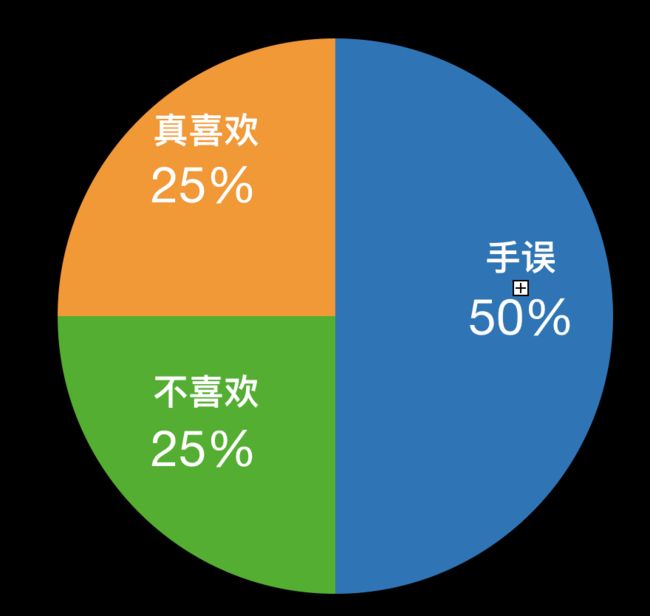
在上面的例子中,1/2是真的喜欢,1/4是随便点的,1/4不喜欢如果只是我们认为的概率分布是:
实际上用户的真实想法是:1/4是真的喜欢,1/2是随便点的,1/4不喜欢
会发生什么呢?
我们会进行错误的验证流程:
我们的猜测次数的期望会变成:
1/2 * 2 + 1/4 * 1 + 1/4 * 2 = 1.75
这个数字高于了我们前面计算的1.5。因为我们对用户的想法有了错误的判断。
高于信息熵了,说明我心中的概率分布是错误的。
交叉熵的意义在于,用这样一套模型来表示,我心中的概率分布与实际的概率分布相差有多远。用这样的一个量,来定义我预估事情的错误程度(loss)。
它的定义为:
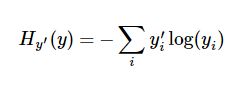
其中y'是真实概率。y是我们计算的概率。
应用
在多元分类问题中,交叉熵常被用作,损失函数。比如在mnist问题中,我们的真实概率其实只有0和1。
假设,手写的数字为1。
那么我们的真实概率分布应为[0, 1, 0, 0, 0, 0, 0, 0, 0, 0]
而我们的预测概率分布可能为[0.05, 0.55, 0.05, 0.05, 0.05, 0.05, 0.05, 0.05, 0.05, 0.05]
此时,交叉熵即为
-1 * log(0.55)
如果我们的预测概率分布与真实概率分布一致,那么交叉熵应为:
1 * log(1) = 0
符合预期。
因此,我们即可以用交叉熵的大小,来估评我们预测的不准确度。
在tensorflow中,交叉熵的计算为:
cross_entropy = -tf.reduce_sum(y_*tf.log(y))
以上就是交叉熵的基本介绍,如有问题,欢迎指正。