数据驱动分析实践七 - 市场响应模型
数据驱动分析实践七
市场响应模型
通过使用前面文章所建立的模型,我们可以进行客户分段、预测LTV等。我们也知道了我们的销量的大体情况。但是我们该如何使我们的销量增长呢?如果我们今天打折,我们期望的交易增长会有多少?
客户分段和A/B测试可以使我们尝试多个不同策略来产生销售增长。这是Growth Hacking的必要组件之一。你需要有想法并进行多次实验来挖掘增长机会。
把客户分位控制组(control group)和测试组(test group)可帮助我们计算增长的增益。请看下例:
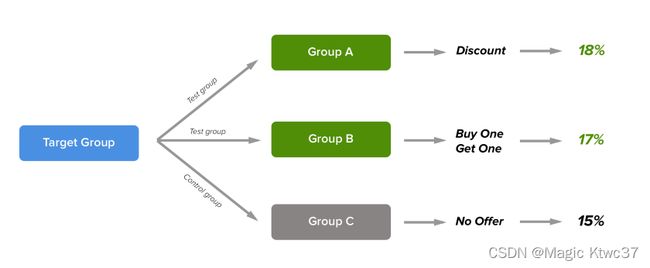
上图中,目标组被分成3个组以回答下面的问题:
- 给一点赠与会增加转化吗
- 如果是的化,那种方式更好?打折或者买一送一。
假如结果是具备统计显著性的。打折看上去最好,因为它比不打折增加了3%的转化率,且比买一送一增加了1%的转化率。
当然这是世界的情况比这个要复杂很多。很可能一些优惠策略只对特定的群体有效。所以你可能需要对多种客户群体建立组合优惠策略。进一步说,转化率并不是你唯一需要考虑的因素,通常你也需要考虑成本并做出权衡选择。一般来说,这两者是负相关的。
现在,通过这个实验我们知道了哪一种优惠方法会获得更大的转化率。但是如何预测这一点呢?如果我们可以预测优惠政策的效果,我们就可以最大化收益且预知成本。
市场响应模型帮助我们对此类问题建立框架,通常有多种方法来建立此模型。我们可以将其分成两组:
- 如果你没有控制组,那么你就不能计算增长。在这种情况下,一般采用回归模型。
- 如果你有控制组,你可以建立一个针对群体和个体级别的响应模型。
from datetime import datetime, timedelta,date
import pandas as pd
%matplotlib inline
from sklearn.metrics import classification_report,confusion_matrix
import matplotlib.pyplot as plt
import numpy as np
import seaborn as sns
from sklearn.cluster import KMeans
import chart_studio.plotly as py
import plotly.offline as pyoff
import plotly.graph_objs as go
import sklearn
import xgboost as xgb
from sklearn.model_selection import KFold, cross_val_score, train_test_split
#initate plotly
pyoff.init_notebook_mode()
#function for ordering cluster numbers for given criteria
def order_cluster(cluster_field_name, target_field_name,df,ascending):
new_cluster_field_name = 'new_' + cluster_field_name
df_new = df.groupby(cluster_field_name)[target_field_name].mean().reset_index()
df_new = df_new.sort_values(by=target_field_name,ascending=ascending).reset_index(drop=True)
df_new['index'] = df_new.index
df_final = pd.merge(df,df_new[[cluster_field_name,'index']], on=cluster_field_name)
df_final = df_final.drop([cluster_field_name],axis=1)
df_final = df_final.rename(columns={"index":cluster_field_name})
return df_final
#import the data
df_data = pd.read_csv('response_data.csv')
#print first 10 rows
df_data.head(10)
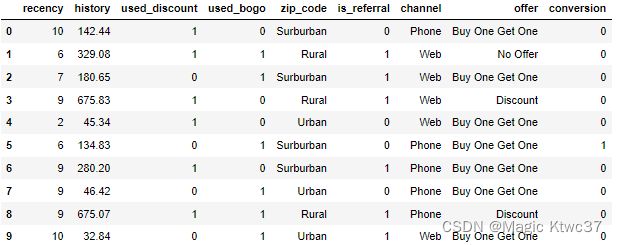
数据定义如下:
- recency: 上次购买到现在的月数
- history: 历史购买价值
- used_discount/used_bogo:客户是否使用过折扣或者买一送一
- zip_code:区域编码,可以是Surburban/Rural/Urban
- s_referal:客户是否是从其他渠道推荐而来
- channel:用户所使用的渠道
- offer:给予用户的优惠
我们要建立一个二分类模型来为所有用户计算转化概率,步骤如下:
建立提升公式
- 探索式数据分析和特征工程
- 为转化概率评分
- 在测试集上观察结果
Uplift 公式
首先,我们需要构造一个函数来计算我们的提升。为了简化问题,我们假设每一个转化会带来一个订单,且订单价值为25$。
我们将计算三种提升:
- 转化提升 :测试组的转化率 - 控制组的转化率
- 订单提升 :转化提升 * 测试组的转化客户的个数
- 收入提升 :订单提升 * 平均每单价值
def calc_uplift(df):
#assigning 25$ to the average order value
avg_order_value = 25
#calculate conversions for each offer type
base_conv = df[df.offer == 'No Offer']['conversion'].mean()
disc_conv = df[df.offer == 'Discount']['conversion'].mean()
bogo_conv = df[df.offer == 'Buy One Get One']['conversion'].mean()
#calculate conversion uplift for discount and bogo
disc_conv_uplift = disc_conv - base_conv
bogo_conv_uplift = bogo_conv - base_conv
#calculate order uplift
disc_order_uplift = disc_conv_uplift * len(df[df.offer == 'Discount']['conversion'])
bogo_order_uplift = bogo_conv_uplift * len(df[df.offer == 'Buy One Get One']['conversion'])
#calculate revenue uplift
disc_rev_uplift = disc_order_uplift * avg_order_value
bogo_rev_uplift = bogo_order_uplift * avg_order_value
print('Discount Conversion Uplift: {0}%'.format(np.round(disc_conv_uplift*100,2)))
print('Discount Order Uplift: {0}'.format(np.round(disc_order_uplift,2)))
print('Discount Revenue Uplift: ${0}\n'.format(np.round(disc_rev_uplift,2)))
print('-------------- \n')
print('BOGO Conversion Uplift: {0}%'.format(np.round(bogo_conv_uplift*100,2)))
print('BOGO Order Uplift: {0}'.format(np.round(bogo_order_uplift,2)))
print('BOGO Revenue Uplift: ${0}'.format(np.round(bogo_rev_uplift,2)))
calc_uplift(df_data)
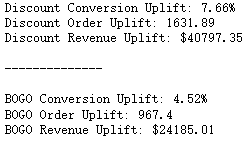
从结果上看,如果我们想要更多的转化率,那么折扣是一个不错的选择。
EDA & 特征工程
1 - Recency
理想情况下,当recency上升的时候转化率应该下降,因为不活跃的客户再一次购买的可能性会下降。
df_plot = df_data.groupby('recency').conversion.mean().reset_index()
plot_data = [
go.Bar(
x=df_plot['recency'],
y=df_plot['conversion'],
)
]
plot_layout = go.Layout(
xaxis={"type": "category"},
title='Recency vs Conversion',
plot_bgcolor = 'rgb(243,243,243)',
paper_bgcolor = 'rgb(243,243,243)',
)
fig = go.Figure(data=plot_data, layout=plot_layout)
pyoff.iplot(fig)
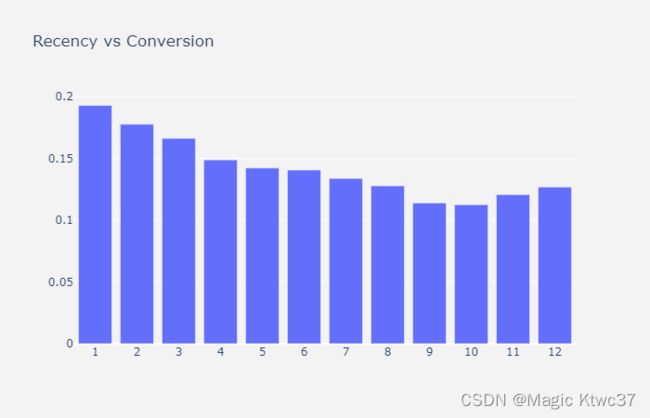
整体看来是符合预期的。但是从11个月开始的recency,对应的转化率又增长了。这个现象的原因有很多,可能是客户总量变少了,也可能是折扣起的作用。
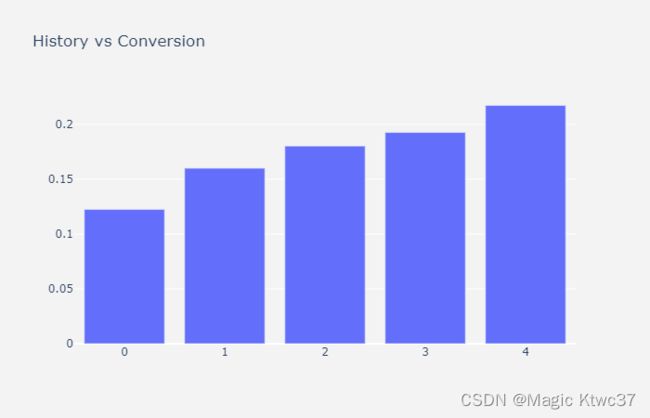
2 - History
我们创建历史的聚类并观察其影响。
kmeans = KMeans(n_clusters=5)
kmeans.fit(df_data[['history']])
df_data['history_cluster'] = kmeans.predict(df_data[['history']])#order the cluster numbers
df_data = order_cluster('history_cluster', 'history',df_data,True)#print how the clusters look like
df_data.groupby('history_cluster').agg({'history':['mean','min','max'], 'conversion':['count', 'mean']})#plot the conversion by each cluster
df_plot = df_data.groupby('history_cluster').conversion.mean().reset_index()
plot_data = [
go.Bar(
x=df_plot['history_cluster'],
y=df_plot['conversion'],
)
]
plot_layout = go.Layout(
xaxis={"type": "category"},
title='History vs Conversion',
plot_bgcolor = 'rgb(243,243,243)',
paper_bgcolor = 'rgb(243,243,243)',
)
fig = go.Figure(data=plot_data, layout=plot_layout)
pyoff.iplot(fig)
df_data.groupby('history_cluster').agg({'history':['mean','min','max'],'conversion':['count','mean']})
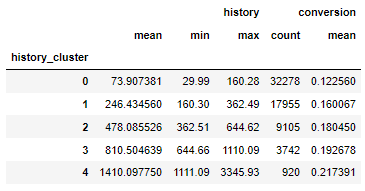
具有较高的历史价值的客户更有可能转化。
3. 已使用折扣或买一送一
df_data.groupby(['used_discount','used_bogo','offer']).agg({'conversion':'mean'})
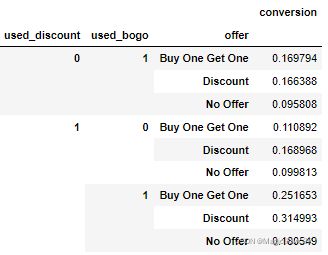
之前有使用折扣和优惠策略的客户有更高的转化率。
4. zip code
df_plot = df_data.groupby('zip_code').conversion.mean().reset_index()
plot_data = [
go.Bar(
x=df_plot['zip_code'],
y=df_plot['conversion'],
marker=dict(
color=['green', 'blue', 'orange'])
)
]
plot_layout = go.Layout(
xaxis={"type": "category"},
title='Zip Code vs Conversion',
plot_bgcolor = 'rgb(243,243,243)',
paper_bgcolor = 'rgb(243,243,243)',
)
fig = go.Figure(data=plot_data, layout=plot_layout)
pyoff.iplot(fig)
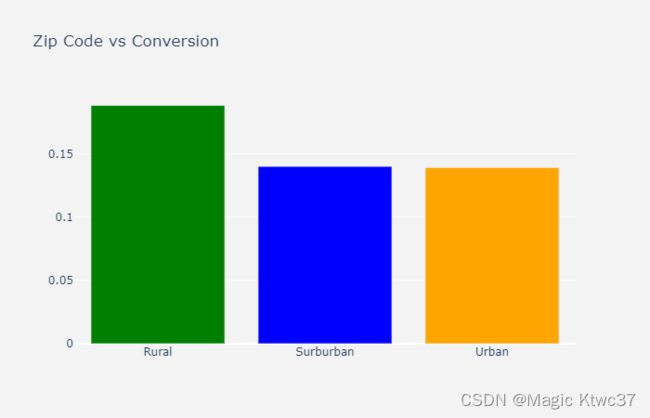
来自Rural的客户的转化率更高。
5 - Referal
df_plot = df_data.groupby('is_referral').conversion.mean().reset_index()
plot_data = [
go.Bar(
x=df_plot['is_referral'],
y=df_plot['conversion'],
marker=dict(
color=['green', 'blue', 'orange'])
)
]
plot_layout = go.Layout(
xaxis={"type": "category"},
title='Referral vs Conversion',
plot_bgcolor = 'rgb(243,243,243)',
paper_bgcolor = 'rgb(243,243,243)',
)
fig = go.Figure(data=plot_data, layout=plot_layout)
pyoff.iplot(fig)
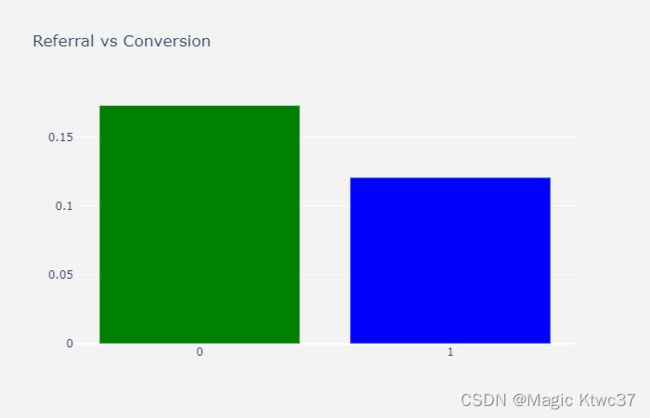
由其他渠道推荐或者引流来的客户的转化率更低。
6 - Channe
df_plot = df_data.groupby('channel').conversion.mean().reset_index()
plot_data = [
go.Bar(
x=df_plot['channel'],
y=df_plot['conversion'],
marker=dict(
color=['green', 'blue', 'orange'])
)
]
plot_layout = go.Layout(
xaxis={"type": "category"},
title='Channel vs Conversion',
plot_bgcolor = 'rgb(243,243,243)',
paper_bgcolor = 'rgb(243,243,243)',
)
fig = go.Figure(data=plot_data, layout=plot_layout)
pyoff.iplot(fig)
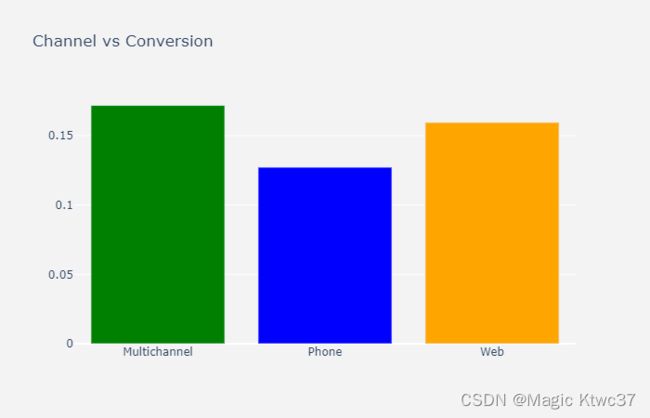
多渠道的客户的转化率更高,使用多于一个渠道的客户更加投入。
7 - 优惠策略
df_plot = df_data.groupby('offer').conversion.mean().reset_index()
plot_data = [
go.Bar(
x=df_plot['offer'],
y=df_plot['conversion'],
marker=dict(
color=['green', 'blue', 'orange'])
)
]
plot_layout = go.Layout(
xaxis={"type": "category"},
title='Offer vs Conversion',
plot_bgcolor = 'rgb(243,243,243)',
paper_bgcolor = 'rgb(243,243,243)',
)
fig = go.Figure(data=plot_data, layout=plot_layout)
pyoff.iplot(fig)
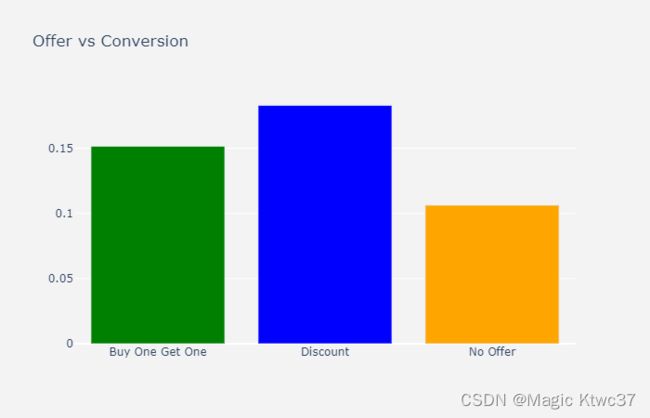
df_model = df_data.copy()
df_model = pd.get_dummies(df_model)
转化概率评分
#create feature set and labels
X = df_model.drop(['conversion'],axis=1)
y = df_model.conversion
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=56)
xgb_model = xgb.XGBClassifier().fit(X_train, y_train)
X_test['proba'] = xgb_model.predict_proba(X_test)[:,1]
X_test = pd.concat([X_test,y_test],axis=1)
X_test.head(5)

可以看到,我们的模型为每一个客户分配了一个转化概率。但是我们需要理解我们的模型是否能工作。
测试集结果
假设打折、优惠和控制组的概率差近似于其转化率。我们需要观察测试集看看是否如此。
计算一下对于折扣的实际订单增量
real_disc_uptick = len(X_test)*(X_test[X_test['offer_Discount'] == 1].conversion.mean() - X_test[X_test['offer_No Offer'] == 1].conversion.mean())
pred_disc_uptick = len(X_test)*(X_test[X_test['offer_Discount'] == 1].proba.mean() - X_test[X_test['offer_No Offer'] == 1].proba.mean())
print("Real Discount Uptick - Order : {}, Revenue: {}".format(real_disc_uptick,real_disc_uptick*25))
print("Predicted Discount Uptick - Order : {}, Revenue: {}".format(pred_disc_uptick,pred_disc_uptick*25))
Real Discount Uptick - Order : 911.7049280910762, Revenue: 22792.623202276907
Predicted Discount Uptick - Order : 952.8169631958008, Revenue: 23820.42407989502
从上面的数据看来结果还是不错的。
我们对优惠做同样的检查
real_bogo_uptick = len(X_test)*(X_test[X_test['offer_Buy One Get One'] == 1].conversion.mean() - X_test[X_test['offer_No Offer'] == 1].conversion.mean())
pred_bogo_uptick = len(X_test)*(X_test[X_test['offer_Buy One Get One'] == 1].proba.mean() - X_test[X_test['offer_No Offer'] == 1].proba.mean())
print("Real bogo Uptick - Order : {}, Revenue: {}".format(real_bogo_uptick,real_bogo_uptick*25))
print("Predicted bogo Uptick - Order : {}, Revenue: {}".format(pred_bogo_uptick,pred_bogo_uptick*25))
Real bogo Uptick - Order : 497.4114165117516, Revenue: 12435.28541279379
Predicted bogo Uptick - Order : 601.2996673583984, Revenue: 15032.491683959961
这个效果一般,可能模型还需要进一步优化。
计算转换概率可以在很多不同的地方帮助到我们。我们已经预测了不同类型的优惠策略给我们带来的回报,它可以帮助我们来找出哪些客户可以使我们获得最大的提升。 下一节我们将来构建我们自己的提升模型。
未完待续,…