概率机器人:测距传感器的波束模型
机器人感知
测量模型
测量模型:用于描述客观世界中生成传感器测量数据的过程。
模型的特性取决于传感器:
- 成像传感器 :通过投影几何学建立
- 声纳传感器 :通过描述声波和声波在环境表面上的反射建立
测量模型定义为一个条件概率密度 p ( z t ∣ x t , m ) p(z_t|x_t,m) p(zt∣xt,m),表示在环境地图 m m m和机器人位姿为 x t x_t xt的条件下,传感器测量得到 z t z_t zt的概率密度。
传感器在进行测量时,将会产生一系列的测量值。如相机传感器返回一组完整的数据(亮度、饱和度、色彩);同样,测距传感器将产生一些列测距值,其中每个 z t k z_t^k ztk表示一个独立的测距值:
z t = { z t 1 , z t 2 , ⋯ , z t K } z_t=\{z_t^1,z_t^2,\cdots,z_t^K\} zt={zt1,zt2,⋯,ztK}
对每个独立的测量相乘可以得到测量模型:
p ( z t ∣ x t , m ) = ∏ K = 1 K p ( z t K ∣ x t , m ) p(z_t|x_t,m)=\prod_{K=1}^Kp(z_t^K|x_t,m) p(zt∣xt,m)=K=1∏Kp(ztK∣xt,m)
理想条件下,每个独立测量束噪声之间相互独立,符合马尔可夫假设。
地图
环境的地图(map)给出了环境中物体的列表及其属性,包含特征地图和位置地图两大类。
基于特征的地图
在基于特征的地图(Feature-based Maps)中,用下标 n n n表示特征索引,N表示环境中物体的总数:
m = { m 1 , m 2 , ⋯ , m N } m=\{m_1,m_2,\cdots,m_N\} m={m1,m2,⋯,mN}
每个 m n ( 1 ≤ n ≤ N ) m_n(1\le n\le N) mn(1≤n≤N)指定一个属性,包含了特征的属性及特征的笛卡尔位置。
基于特征的地图仅指明在指定位置(即地图中包含的对象的位置)的环境的形状,特征描述法使得调节对象的位置更为简单。
基于位置的地图
在基于位置的地图(Location-based Maps)中,用下标 x , y x,y x,y表示平面地图中,该物体的坐标:
m = { m 0 , 0 , m 0 , 1 , ⋯ , m x , y } m=\{m_{0,0},m_{0,1},\cdots,m_{x,y}\} m={m0,0,m0,1,⋯,mx,y}
每个 m x , y m_{x,y} mx,y指定为平面坐标为 ( x , y ) (x,y) (x,y)的属性。
基于位置的地图具有体积(volumetric),体积地图不仅包含环境物体的信息,也包含了对象没有物体的信息(即闲置区域)
占用栅格地图
占用栅格地图(Occupancy Grid Map)是一种经典的地图表示法,它是基于位置的地图。
占用栅格地图为每一个坐标 ( x , y ) (x,y) (x,y)分配了一个二值占用值,用于指明该位置是否被某个对象占用。被占用的区域称为占用区域,未被占用的区域称为闲置区域。
占用栅格地图使得搜寻机器人通过闲置区域抵达目标点的路径更为便捷。
测距仪的波束模型
测距仪测量到附近物体的距离,可沿着一个波束测量(激光测距仪优选模型)或在一个测量锥内测量(超声波传感器优选模型)。
模型建立
测距仪的波束模型(Beam Model) p ( z t ∣ x t , m ) p(z_t|x_t,m) p(zt∣xt,m)可以看作是四种在机器人移动过程中存在的噪声的混合,每类噪声代表一种在实际运行中测距仪误差的产生。
噪声一:测量噪声模型
理想情况下,测距仪总是测量位于其测量范围内最近物体的实际距离 z t k ∗ z_t^{k*} ztk∗。但由于测距传感器受到环境噪声影响,所得返回值一般为测量值 z t k z_t^k ztk。在不同的地图中,可采用不同方式得到实际距离:
- 基于位置的地图:射线投影法
- 基于特征的地图:在测量锥内寻找最近特征以获取
通常采用均值为 z t k ∗ z_t^{k*} ztk∗,标准差为 σ h i t \sigma_{hit} σhit的高斯分布来建模该噪声,如图所示采用 p h i t p_{hit} phit表示此概率密度:

由于测距传感器存在测量最大值 z m a x z_{max} zmax,同时测量值必定大于等于零,则给定测量噪声表达式:
p h i t ( z t ∣ x t , m ) = { η N ( z t k ; z t k ∗ , σ h i t 2 ) 0 ≤ z t k ≤ z m a x 0 其 他 p_{hit}(z_t|x_t,m)=\begin{cases}\eta \mathcal{N}(z_t^k;z_t^{k*},\sigma_{hit}^2)\quad&0\le z_t^k\le z_{max}\\ 0&其他\end{cases} phit(zt∣xt,m)={ηN(ztk;ztk∗,σhit2)00≤ztk≤zmax其他
式中,实际距离 z t k ∗ z_t^{k*} ztk∗由射线投影计算得到; N ( z t k ; z t k ∗ , σ h i t 2 ) \mathcal{N}(z_t^k;z_t^{k*},\sigma_{hit}^2) N(ztk;ztk∗,σhit2)表示均值为 z t k ∗ z_t^{k*} ztk∗,方差为 σ h i t 2 \sigma_{hit}^2 σhit2的关于变量 z t k z_t^k ztk的正态分布:
N ( z t k ; z t k ∗ , σ h i t 2 ) = 1 2 π σ h i t 2 e x p ( − 1 2 ( z t k − z t k ∗ ) 2 σ h i t 2 ) \mathcal{N}(z_t^k;z_t^{k*},\sigma_{hit}^2)=\frac{1}{\sqrt{2\pi\sigma_{hit}^2}}exp(-\frac{1}{2}\frac{(z_t^k-z_t^{k*})^2}{\sigma_{hit}^2}) N(ztk;ztk∗,σhit2)=2πσhit21exp(−21σhit2(ztk−ztk∗)2)
η \eta η为归一化因子:
η = ( ∫ 0 z m a x N ( z t k ; z t k ∗ , σ h i t 2 ) d z t k ) − 1 \eta=(\int_0^{z_{max}} \mathcal{N}(z_t^k;z_t^{k*},\sigma_{hit}^2) \quad dz_t^k \quad)^{-1} η=(∫0zmaxN(ztk;ztk∗,σhit2)dztk)−1
噪声的标准差 σ h i t \sigma_{hit} σhit为测量模型的固有参数。
噪声二:环境噪声模型
由于地图信息 m m m为静态信息而机器人移动环境为动态环境,当实际环境内存在地图信息中不包含的对象时(如建图时,环境内不包含操控机器人的人物所处信息),测距仪将受到意外环境噪声影响。从而将导致实际距离 z t k ∗ z_t^{k*} ztk∗更短。
此类意外对象造成测距仪噪声的可能性随着其距离而概率降低。如图所示,由于测距仪返回距离其最近的物体的距离,此时意外对象A和B出现在地图环境内,且A位于B前侧,则唯有A不出现时,测距仪能够感测到意外对象B的存在,否则仅传回意外对象A存在。
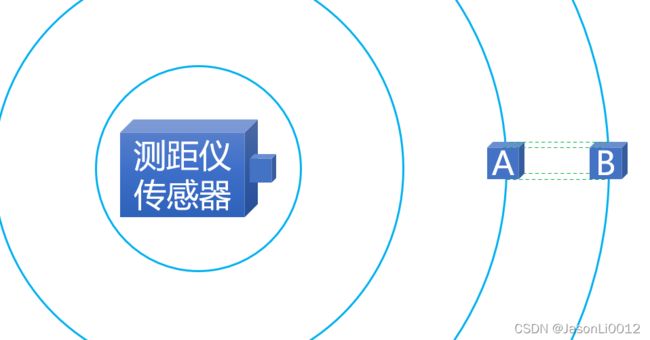
由此,采用指数分布来建模此类噪声现象,如图所示,采用 p s h o r t p_{short} pshort表示指数分布噪声:
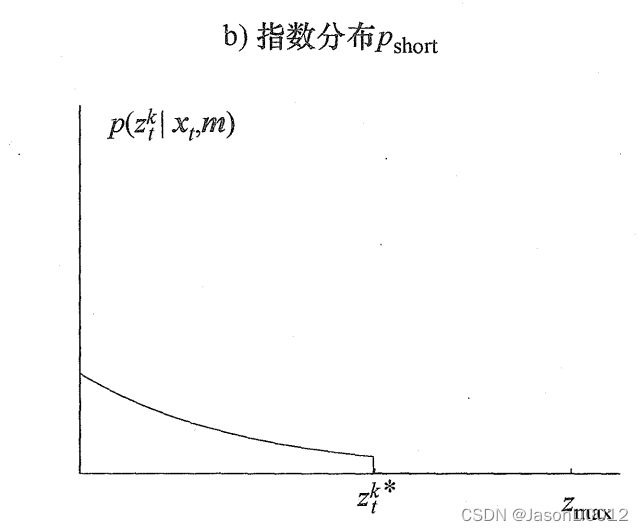
在定义域范围内,模型如下所示:
p s h o r t ( z t ∣ x t , m ) = { η λ s h o r t e x p ( − λ s h o r t ⋅ z t k ) 0 ≤ z t k ≤ z t k , ∗ 0 其 他 p_{short}(z_t|x_t,m)=\begin{cases}\eta\lambda_{short}exp(-\lambda_{short}\cdot z_t^k)\quad&0\le z_t^k\le z_t^{k,*}\\ 0\quad&其他\end{cases} pshort(zt∣xt,m)={ηλshortexp(−λshort⋅ztk)00≤ztk≤ztk,∗其他
式中,参量 λ s h o r t \lambda_{short} λshort为模型的固有参量; η \eta η为归一化因子:
η = ( ∫ 0 z t k ∗ λ s h o r t e x p ( − λ s h o r t ⋅ z t k ) d z t k ) − 1 = ( − e x p ( − λ s h o r t z t k ∗ ) + e x p ( − λ s h o r t 0 ) ) − 1 = 1 1 − e x p ( − λ s h o r t z t k ∗ ) \begin{aligned} \eta&=(\int_0^{z_t^{k*}}\lambda_{short}exp(-\lambda_{short}\cdot z_t^k)\quad dz_t^k)^{-1}\\ &=(-exp(-\lambda_{short}z_t^{k*})+exp(-\lambda_{short}0))^{-1}\\ &=\frac{1}{1-exp(-\lambda_{short}z_t^{k*})} \end{aligned} η=(∫0ztk∗λshortexp(−λshort⋅ztk)dztk)−1=(−exp(−λshortztk∗)+exp(−λshort0))−1=1−exp(−λshortztk∗)1
噪声三:失败噪声模型
当所处环境存在镜面类容易反射激光束、声纳等信号的环境,或激光测距仪检测到黑色吸光现象、高光照下激光测量失败等情况时,环境存在测量失败噪声。
此时,测距仪将返回传感器的最大允许范围值 z m a x z_{max} zmax。采用以 z m a x z_{max} zmax为中心的点群分布建模,以 p m a x p_{max} pmax表示该模型:

实际上, p m a x p_{max} pmax为一个离散分布,上图将其用一个很窄的以 z m a x z_{max} zmax为中心的均匀分布给出,则模型的数学表达式如下所示:
p m a x ( z t k ∣ x t , m ) = I ( z = z m a x ) = { 1 z = z m a x 0 其 他 p_{max}(z_t^k|x_t,m)=I(z=z_{max})=\begin{cases}1\quad&z=z_{max}\\0\quad&其他\end{cases} pmax(ztk∣xt,m)=I(z=zmax)={10z=zmax其他
式中,函数 I ( z = z m a x ) I(z=z_{max}) I(z=zmax)为指示函数,当括号内条件成立时返回1,其余返回0。
噪声四:随机噪声模型
此外,测距仪传感器可能偶尔存在无法解释的测量,将其简化为在测量区间 [ 0 , z m a x ) [0,z_{max}) [0,zmax)中存在一个均匀分布,如图所示,定义为 p r a n d p_{rand} prand:

p r a n d ( z t k ∣ x t , m ) = { 1 z m a x 0 ≤ z t k < z m a x 0 其 他 p_{rand}(z_t^k|x_t,m)=\begin{cases}\frac{1}{z_{max}}\quad&0\le z_t^k
波束模型
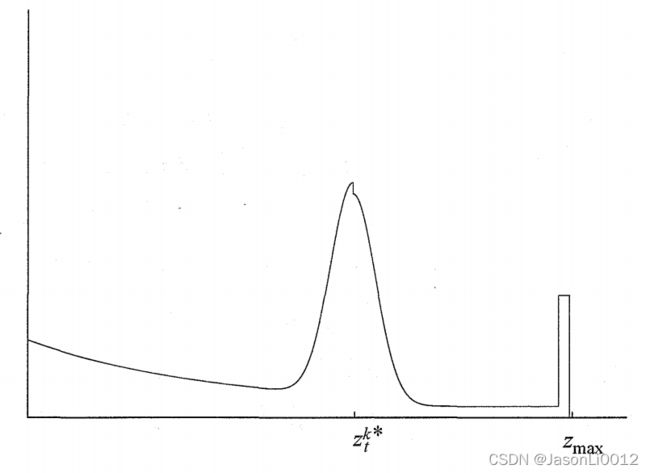
将上述四类噪声模型通过参数 z h i t 、 z s h o r t 、 z m a x 、 z r a n d z_{hit}、z_{short}、z_{max}、z_{rand} zhit、zshort、zmax、zrand进行加权平均混合,得到波束模型 p ( z t k ∣ x t , m ) p(z_t^k|x_t,m) p(ztk∣xt,m)
p ( z t k ∣ x t , m ) = [ z h i t z s h o r t z m a x z r a n d ] T ⋅ [ p h i t ( z t k ∣ x t , m ) p s h o r t ( z t k ∣ x t , m ) p m a x ( z t k ∣ x t , m ) p r a n d ( z t k ∣ x t , m ) ] p(z_t^k|x_t,m)=\begin{bmatrix}z_{hit}\\z_{short}\\z_{max}\\z_{rand}\end{bmatrix}^T\cdot\begin{bmatrix}p_{hit}(z_t^k|x_t,m)\\p_{short}(z_t^k|x_t,m)\\p_{max}(z_t^k|x_t,m)\\p_{rand}(z_t^k|x_t,m)\\\end{bmatrix} p(ztk∣xt,m)=⎣⎢⎢⎡zhitzshortzmaxzrand⎦⎥⎥⎤T⋅⎣⎢⎢⎡phit(ztk∣xt,m)pshort(ztk∣xt,m)pmax(ztk∣xt,m)prand(ztk∣xt,m)⎦⎥⎥⎤
参数间满足和为1的条件:
z h i t + z s h o r t + z m a x + z r a n d = 1 z_{hit}+z_{short}+z_{max}+z_{rand}=1 zhit+zshort+zmax+zrand=1
所得模型如图所示:
模型算法
针对测量模型,可设计如下算法实现该模型:
系统输入: 完整的一组测量数据 z t z_t zt、机器人位姿 x t x_t xt、地图环境信息 m m m
系统输出: 期望概率 p ( z t k ∣ x t , m ) p(z_t^k|x_t,m) p(ztk∣xt,m)
A l g o r i t h m b e a m _ r a n g e _ f i n d e r _ m o d e l ( z t , x t , m ) : 1 : q = 1 2 : f o r k = 1 t o k d o 3 : c o m p u t e z t k ∗ f o r t h e m e a s u r e m e n t z t k u s i n g r a y c a s t i n g 4 : p = z h i t ⋅ p h i t ( z t k ∣ x t , m ) + z s h o r t ⋅ p s h o r t ( z t k ∣ x t , m ) + z m a x ⋅ p m a x ( z t k ∣ x t , m ) + z r a n d ⋅ p r a n d ( z t k ∣ x t , m ) 5 : q = q ⋅ p 6 : r e t u r n q \begin{aligned} &Algorithm\quad beam\_range\_finder\_model(z_t,x_t,m):\\ 1:&\qquad q=1\\ 2:&\qquad for\enspace k=1\enspace to\enspace k\enspace do\\ 3:&\qquad\qquad compute\enspace z_t^{k*}\enspace for\enspace the\enspace measurement\enspace z_t^k\enspace using\enspace ray\enspace casting\\ 4:&\qquad\qquad p=z_{hit}\cdot p_{hit}(z_t^k|x_t,m)+z_{short}\cdot p_{short}(z_t^k|x_t,m)+z_{max}\cdot p_{max}(z_t^k|x_t,m)+z_{rand}\cdot p_{rand}(z_t^k|x_t,m) \\ 5:&\qquad\qquad q=q\cdot p\\ 6:&\qquad return\quad q\\ \end{aligned} 1:2:3:4:5:6:Algorithmbeam_range_finder_model(zt,xt,m):q=1fork=1tokdocomputeztk∗forthemeasurementztkusingraycastingp=zhit⋅phit(ztk∣xt,m)+zshort⋅pshort(ztk∣xt,m)+zmax⋅pmax(ztk∣xt,m)+zrand⋅prand(ztk∣xt,m)q=q⋅preturnq
其中,首先定义变量 q q q用于存储概率密度(第一行)。
随后,遍历所有测量数据(第二行),对其内每个数据 z t k z_t^k ztk采用射线投影法计算其实际距离 z t k ∗ z_t^{k*} ztk∗(第三行)
再次,对每个实际距离 z t k ∗ z_t^{k*} ztk∗采用波束模型计算其期望概率(第四行),并将其累乘至 q q q中(第五行)
最终,完整遍历完所有数据后,得到测距仪得到的这一组距离值 z t z_t zt的概率并返回(第六行)。
模型内参
传感器模型参数 Θ \Theta Θ包括了混合参数 z h i t 、 z s h o r t 、 z m a x 、 z r a n d z_{hit}、z_{short}、z_{max}、z_{rand} zhit、zshort、zmax、zrand以及参数 σ h i t \sigma_{hit} σhit和参数 λ s h o r t \lambda_{short} λshort。任何传感器测量的似然就是 Θ \Theta Θ的函数。
通常,可以通过实际数据得到模型的内参。假设参考数据集为 Z = { z i } Z=\{z_i\} Z={zi}、机器人位姿 X = { x i } X=\{x_i\} X={xi}、地图信息 m m m,其中 z i z_i zi表示每个实际的测量数据; x i x_i xi表示测量被采纳时机器人的位姿,则可对数据集 Z Z Z进行极大似然估计,从而得到模型的内参:
p ( Z ∣ X , m , Θ ) p(Z|X,m,\Theta) p(Z∣X,m,Θ)
为推导极大似然估计,定义一致性变量 c i c_i ci用于表示一个测量值 z i z_i zi产生的可能途径。
波束模型具有四类噪声途径参数测量值 z i z_i zi,则 c i c_i ci的取值有四种类型: h i t hit hit、 s h o r t short short、 m a x max max、 r a n d rand rand
对于模型的极大似然估计,首先假设已知一致性变量 c i c_i ci情况下的求解,并由此推广至其未知情况下的求解。
假设已知 c i c_i ci取值
此时,可将测试集 Z Z Z划分为四类不相交的数集, Z h i t Z_{hit} Zhit、 Z s h o r t Z_{short} Zshort、 Z m a x Z_{max} Zmax、 Z r a n d Z_{rand} Zrand:
Z h i t ⋃ Z s h o r t ⋃ Z m a x ⋃ Z r a n d = Z Z h i t ⋂ Z s h o r t = Z h i t ⋂ Z m a x = Z h i t ⋂ Z r a n d = ∅ Z s h o r t ⋂ Z m a x = Z s h o r t ⋂ Z r a n d = Z m a x ⋂ Z r a n d = ∅ Z_{hit}\bigcup Z_{short}\bigcup Z_{max}\bigcup Z_{rand}=Z\\ Z_{hit}\bigcap Z_{short}=Z_{hit}\bigcap Z_{max}=Z_{hit}\bigcap Z_{rand}=\varnothing\\ Z_{short}\bigcap Z_{max}=Z_{short}\bigcap Z_{rand}=Z_{max}\bigcap Z_{rand}=\varnothing Zhit⋃Zshort⋃Zmax⋃Zrand=ZZhit⋂Zshort=Zhit⋂Zmax=Zhit⋂Zrand=∅Zshort⋂Zmax=Zshort⋂Zrand=Zmax⋂Zrand=∅
混合参数的极大似然估计
对数据集进行归一化,可得混合参数的极大似然估计:
[ z h i t z s h o r t z m a x z r a n d ] = ∣ Z ∣ − 1 [ ∣ Z h i t ∣ ∣ Z s h o r t ∣ ∣ Z m a x ∣ ∣ Z r a n d ∣ ] \begin{bmatrix}z_{hit}\\z_{short}\\z_{max}\\z_{rand}\end{bmatrix}=|Z|^{-1}\begin{bmatrix}|Z_{hit}|\\|Z_{short}|\\|Z_{max}|\\|Z_{rand}|\end{bmatrix} ⎣⎢⎢⎡zhitzshortzmaxzrand⎦⎥⎥⎤=∣Z∣−1⎣⎢⎢⎡∣Zhit∣∣Zshort∣∣Zmax∣∣Zrand∣⎦⎥⎥⎤
固有参数 σ h i t \sigma_{hit} σhit的极大似然估计
首先,求解似然函数:
p ( Z h i t ∣ X , m , Θ ) = ∏ z i ∈ Z h i t p h i t ( z i ∣ x i , m , Θ ) = ∏ z i ∈ Z h i t 1 2 π σ h i t 2 e x p ( − 1 2 ( z i − z i ∗ ) 2 σ h i t 2 ) \begin{aligned} p(Z_{hit}|X,m,\Theta)=&\prod_{z_i\in Z_{hit}}p_{hit}(z_i|x_i,m,\Theta)\\ =&\prod_{z_i\in Z_{hit}}\frac{1}{\sqrt{2\pi\sigma_{hit}^2}}exp(-\frac{1}{2}\frac{(z_i-z_i^*)^2}{\sigma_{hit}^2}) \end{aligned} p(Zhit∣X,m,Θ)==zi∈Zhit∏phit(zi∣xi,m,Θ)zi∈Zhit∏2πσhit21exp(−21σhit2(zi−zi∗)2)
式中, z i ∗ z_i^{*} zi∗表示由机器人位姿 x i x_i xi及地图信息 m m m计算得到的实际距离。
其次,求解对数似然函数表达式(两边取自然对数):
ln p ( Z h i t ∣ X , m , Θ ) = ∑ z i ∈ Z h i t [ − 1 2 ln ( 2 π σ h i t 2 ) − 1 2 ( z i − z i ∗ ) 2 σ h i t 2 ] = − 1 2 ∑ z ∈ Z h i t [ ln ( 2 π σ h i t 2 ) + ( z i − z i ∗ ) 2 σ h i t 2 ] = − 1 2 ∑ z ∈ Z h i t [ ln ( 2 π ) + 2 ln ( σ h i t ) + ( z i − z i ∗ ) 2 σ h i t 2 ] = − 1 2 [ ∣ Z h i t ∣ ⋅ ln ( 2 π ) + ∣ Z h i t ∣ ⋅ 2 ln ( σ h i t ) + ∑ z ∈ Z h i t ( z i − z i ∗ ) 2 σ h i t 2 ] = − ∣ Z h i t ∣ 2 ⋅ ln ( 2 π ) − ∣ Z h i t ∣ ⋅ ln ( σ h i t ) − 1 2 σ h i t 2 ∑ z ∈ Z h i t ( z i − z i ∗ ) 2 \begin{aligned} \ln p(Z_{hit}|X,m,\Theta)=&\sum_{z_i\in Z_{hit}}\Bigl[-\frac{1}{2}\ln(2\pi\sigma_{hit}^2)-\frac{1}{2}\frac{(z_i-z_i^*)^2}{\sigma_{hit}^2}\Bigr]\\ =&-\frac{1}{2}\sum_{z\in Z_{hit}}\Bigl[\ln(2\pi\sigma_{hit}^2)+\frac{(z_i-z_i^*)^2}{\sigma_{hit}^2}\Bigr]\\ =&-\frac{1}{2}\sum_{z\in Z_{hit}}\Bigl[\ln(2\pi)+2\ln(\sigma_{hit})+\frac{(z_i-z_i^*)^2}{\sigma_{hit}^2}\Bigr]\\ =&-\frac{1}{2}\Bigl[\vert Z_{hit}\vert\cdot\ln(2\pi)+\vert Z_{hit}\vert\cdot2\ln(\sigma_{hit})+\sum_{z\in Z_{hit}}\frac{(z_i-z_i^*)^2}{\sigma_{hit}^2}\Bigr]\\ =&-\frac{\vert Z_{hit}\vert}{2}\cdot\ln(2\pi)-\vert Z_{hit}\vert\cdot\ln(\sigma_{hit})-\frac{1}{2\sigma_{hit}^2}\sum_{z\in Z_{hit}}(z_i-z_i^*)^2 \end{aligned} lnp(Zhit∣X,m,Θ)=====zi∈Zhit∑[−21ln(2πσhit2)−21σhit2(zi−zi∗)2]−21z∈Zhit∑[ln(2πσhit2)+σhit2(zi−zi∗)2]−21z∈Zhit∑[ln(2π)+2ln(σhit)+σhit2(zi−zi∗)2]−21[∣Zhit∣⋅ln(2π)+∣Zhit∣⋅2ln(σhit)+z∈Zhit∑σhit2(zi−zi∗)2]−2∣Zhit∣⋅ln(2π)−∣Zhit∣⋅ln(σhit)−2σhit21z∈Zhit∑(zi−zi∗)2
将对数似然函数对参数 σ h i t \sigma_{hit} σhit求偏导并使其为0:
∂ ln p ( Z h i t ∣ X , m , Θ ) ∂ σ h i t = 0 − ∣ Z h i t ∣ σ h i t + 1 σ h i t 3 ∑ z i ∈ Z h i t ( z i − z i i ∗ ) 2 = 0 1 σ h i t 3 ∑ z i ∈ Z h i t ( z i − z i i ∗ ) 2 = ∣ Z h i t ∣ σ h i t ∑ z i ∈ Z h i t ( z i − z i i ∗ ) 2 = ∣ Z h i t ∣ σ h i t 2 \begin{aligned} \frac{\partial \ln p(Z_{hit}|X,m,\Theta)}{\partial \sigma_{hit}}&=0\\ -\frac{\vert Z_{hit}\vert}{\sigma_{hit}}+\frac{1}{\sigma_{hit}^3}\sum_{z_i\in Z_{hit}}(z_i-z_i^{i*})^2&=0\\ \frac{1}{\sigma_{hit}^3}\sum_{z_i\in Z_{hit}}(z_i-z_i^{i*})^2&=\frac{\vert Z_{hit}\vert}{\sigma_{hit}}\\ \sum_{z_i\in Z_{hit}}(z_i-z_i^{i*})^2&=\vert Z_{hit}\vert\sigma_{hit}^2 \end{aligned} ∂σhit∂lnp(Zhit∣X,m,Θ)−σhit∣Zhit∣+σhit31zi∈Zhit∑(zi−zii∗)2σhit31zi∈Zhit∑(zi−zii∗)2zi∈Zhit∑(zi−zii∗)2=0=0=σhit∣Zhit∣=∣Zhit∣σhit2
由此,得到似然对数的极大值,也即参数 σ h i t \sigma_{hit} σhit的极大似然估计:
σ h i t = 1 ∣ Z h i t ∣ ⋅ ∑ z i ∈ Z h i t ( z i − z i i ∗ ) 2 \sigma_{hit}=\sqrt{\frac{1}{\vert Z_{hit}\vert}\cdot\sum_{z_i\in Z_{hit}}(z_i-z_i^{i*})^2} σhit=∣Zhit∣1⋅zi∈Zhit∑(zi−zii∗)2
固有参数 λ s h o r t \lambda_{short} λshort的极大似然估计
同样,先计算固有参数 λ s h o r t \lambda_{short} λshort的似然函数:
p ( Z s h o r t ∣ X , m , Θ ) = ∏ z i ∈ Z s h o r t p s h o r t ( z i ∣ x i , m , Θ ) = ∏ z i ∈ Z s h o r t [ λ s h o r t ⋅ e x p ( − λ s h o r t z i ) ] \begin{aligned} p(Z_{short}|X,m,\Theta)=&\prod_{z_i\in Z_{short}}p_{short}(z_i|x_i,m,\Theta)\\ =&\prod_{z_i\in Z_{short}}\Bigl[\lambda_{short}\cdot exp(-\lambda_{short}z_i)\Bigr] \end{aligned} p(Zshort∣X,m,Θ)==zi∈Zshort∏pshort(zi∣xi,m,Θ)zi∈Zshort∏[λshort⋅exp(−λshortzi)]
两侧求自然对数,得到似然函数对数形式:
ln p ( Z s h o r t ∣ X , m , Θ ) = ∑ z i ∈ Z s h o r t [ ln λ s h o r t − λ s h o r t ⋅ z i ] = ∣ Z s h o r t ∣ ⋅ ln λ s h o r t − λ s h o r t ∑ z i ∈ Z s h o r t z i \begin{aligned} \ln p(Z_{short}|X,m,\Theta)=&\sum_{z_i\in Z_{short}}\Bigl[\ln\lambda_{short}-\lambda_{short}\cdot z_i\Bigr]\\ =&\vert Z_{short}\vert\cdot \ln \lambda_{short}-\lambda_{short}\sum_{z_i\in Z_{short}}z_i\\ \end{aligned} lnp(Zshort∣X,m,Θ)==zi∈Zshort∑[lnλshort−λshort⋅zi]∣Zshort∣⋅lnλshort−λshortzi∈Zshort∑zi
对其两侧求对参数 λ s h o r t \lambda_{short} λshort的偏导,并使其为零:
∂ ln p ( Z s h o r t ∣ X , m , Θ ) ∂ λ s h o r t = 0 ∣ Z s h o r t ∣ λ s h o r t − ∑ z i ∈ Z s h o r t z i = 0 ∣ Z s h o r t ∣ λ s h o r t = ∑ z i ∈ Z s h o r t z i \begin{aligned} \frac{\partial \ln p(Z_{short}|X,m,\Theta)}{\partial \lambda_{short}}&=0\\ \frac{\vert Z_{short}\vert}{\lambda_{short}}-\sum_{z_i\in Z_{short}}z_i&=0\\ \frac{\vert Z_{short}\vert}{\lambda_{short}}&=\sum_{z_i\in Z_{short}}z_i\\ \end{aligned} ∂λshort∂lnp(Zshort∣X,m,Θ)λshort∣Zshort∣−zi∈Zshort∑ziλshort∣Zshort∣=0=0=zi∈Zshort∑zi
由此,得到似然对数的极大值,也即参数 λ s h o r t \lambda_{short} λshort的极大似然估计:
λ s h o r t = ∣ Z s h o r t ∣ ∑ z i ∈ Z s h o r t z i \lambda_{short}=\frac{\vert Z_{short}\vert}{\sum_{z_i\in Z_{short}}z_i} λshort=∑zi∈Zshortzi∣Zshort∣
未知 c i c_i ci取值
上述推导假设参数 c i c_i ci已知,将其推广至参数 c i c_i ci未知情况下。设计采用期望值最大算法(Expectation Maximization,EM)实现两步迭代:
- 计算 c i c_i ci的期望值
- 在该期望下计算模型参数
期望计算
首先,定义数据集 Z Z Z的似然函数:
p ( Z ∣ X , m , Θ ) = ∏ z i ∈ Z p ( z i ∣ x i , m , Θ ) = ∏ z i ∈ Z h i t p h i t ( z i ∣ x i , m ) ⋅ ∏ z i ∈ Z s h o r t p s h o r t ( z i ∣ x i , m ) ⋅ ∏ z i ∈ Z m a x p m a x ( z i ∣ x i , m ) ⋅ ∏ z i ∈ Z r a n d p r a n d ( z i ∣ x i , m ) \begin{aligned} p(Z|X,m,\Theta)=&\prod_{z_i\in Z}p(z_i|x_i,m,\Theta)\\ =& \prod_{z_i\in Z_{hit}}p_{hit}(z_i|x_i,m)\cdot\prod_{z_i\in Z_{short}}p_{short}(z_i|x_i,m)\cdot\\ &\prod_{z_i\in Z_{max}}p_{max}(z_i|x_i,m)\cdot\prod_{z_i\in Z_{rand}}p_{rand}(z_i|x_i,m) \end{aligned} p(Z∣X,m,Θ)==zi∈Z∏p(zi∣xi,m,Θ)zi∈Zhit∏phit(zi∣xi,m)⋅zi∈Zshort∏pshort(zi∣xi,m)⋅zi∈Zmax∏pmax(zi∣xi,m)⋅zi∈Zrand∏prand(zi∣xi,m)
对似然函数两侧进行自然对数:
ln p ( Z ∣ X , m , Θ ) = ∑ z i ∈ Z h i t ln p h i t ( z i ∣ x i , m ) + ∑ z i ∈ Z s h o r t ln p s h o r t ( z i ∣ x i , m ) + ∑ z i ∈ Z m a x ln p m a x ( z i ∣ x i , m ) + ∑ z i ∈ Z r a n d ln p r a n d ( z i ∣ x i , m ) \begin{aligned} \ln p(Z|X,m,\Theta)=& \sum_{z_i\in Z_{hit}}\ln p_{hit}(z_i|x_i,m)+\sum_{z_i\in Z_{short}}\ln p_{short}(z_i|x_i,m)+\\ &\sum_{z_i\in Z_{max}}\ln p_{max}(z_i|x_i,m)+\sum_{z_i\in Z_{rand}}\ln p_{rand}(z_i|x_i,m) \end{aligned} lnp(Z∣X,m,Θ)=zi∈Zhit∑lnphit(zi∣xi,m)+zi∈Zshort∑lnpshort(zi∣xi,m)+zi∈Zmax∑lnpmax(zi∣xi,m)+zi∈Zrand∑lnprand(zi∣xi,m)
将变量 c i c_i ci带入上式,可知数据集 Z Z Z内测量值 z i z_i zi将采用对应的噪声模型计算:
ln p ( Z ∣ X , m , Θ ) = ∑ z i ∈ Z [ I ( c i = h i t ) ⋅ ln p h i t ( z i ∣ x i , m ) + I ( c i = s h o r t ) ⋅ ln p s h o r t ( z i ∣ x i , m ) + I ( c i = m a x ) ⋅ ln p m a x ( z i ∣ x i , m ) + I ( c i = r a n d ) ⋅ ln p r a n d ( z i ∣ x i , m ) ] \begin{aligned} \ln p(Z|X,m,\Theta)=\sum_{z_i\in Z}\Bigl[&I(c_i=hit)\cdot\ln p_{hit}(z_i|x_i,m)\\ +&I(c_i=short)\cdot\ln p_{short}(z_i|x_i,m)\\ +&I(c_i=max)\cdot\ln p_{max}(z_i|x_i,m)\\ +&I(c_i=rand)\cdot\ln p_{rand}(z_i|x_i,m)\Bigl] \end{aligned} lnp(Z∣X,m,Θ)=zi∈Z∑[+++I(ci=hit)⋅lnphit(zi∣xi,m)I(ci=short)⋅lnpshort(zi∣xi,m)I(ci=max)⋅lnpmax(zi∣xi,m)I(ci=rand)⋅lnprand(zi∣xi,m)]
由于参数 c i c_i ci未知,则次啊用期望最大算法,希望对上式计算最大期望:
1 : E [ ln p ( Z ∣ X , m , Θ ) ] = ∑ i [ p ( c i = h i t ) ⋅ ln p h i t ( z i ∣ x i , m ) + p ( c i = s h o r t ) ⋅ ln p s h o r t ( z i ∣ x i , m ) + p ( c i = m a x ) ⋅ ln p m a x ( z i ∣ x i , m ) + p ( c i = r a n d ) ⋅ ln p r a n d ( z i ∣ x i , m ) ] 2 : E [ ln p ( Z ∣ X , m , Θ ) ] = : ∑ i [ e i , h i t ⋅ ln p h i t ( z i ∣ x i , m ) + e i , s h o r t ⋅ ln p s h o r t ( z i ∣ x i , m ) + e i , m a x ⋅ ln p m a x ( z i ∣ x i , m ) + e i , r a n d ⋅ ln p r a n d ( z i ∣ x i , m ) ] \begin{aligned} 1:E[\ln p(Z|X,m,\Theta)]=\sum_i\Bigl[&p(c_i=hit)\cdot\ln p_{hit}(z_i|x_i,m)+p(c_i=short)\cdot\ln p_{short}(z_i|x_i,m)+\\ &p(c_i=max)\cdot\ln p_{max}(z_i|x_i,m)+p(c_i=rand)\cdot\ln p_{rand}(z_i|x_i,m)\Bigr]\\ 2:E[\ln p(Z|X,m,\Theta)]=:\sum_i\Bigl[&e_{i,hit}\cdot\ln p_{hit}(z_i|x_i,m)+e_{i,short}\cdot\ln p_{short}(z_i|x_i,m)+\\ &e_{i,max}\cdot\ln p_{max}(z_i|x_i,m)+e_{i,rand}\cdot\ln p_{rand}(z_i|x_i,m)\Bigr]\\ \end{aligned} 1:E[lnp(Z∣X,m,Θ)]=i∑[2:E[lnp(Z∣X,m,Θ)]=:i∑[p(ci=hit)⋅lnphit(zi∣xi,m)+p(ci=short)⋅lnpshort(zi∣xi,m)+p(ci=max)⋅lnpmax(zi∣xi,m)+p(ci=rand)⋅lnprand(zi∣xi,m)]ei,hit⋅lnphit(zi∣xi,m)+ei,short⋅lnpshort(zi∣xi,m)+ei,max⋅lnpmax(zi∣xi,m)+ei,rand⋅lnprand(zi∣xi,m)]
式中,第二行符号 = : =: =:含义为记作 ,其中参数 e i , h i t 、 e i , s h o r t 、 e i , m a x 、 e i , r a n d e_{i,hit}、e_{i,short}、e_{i,max}、e_{i,rand} ei,hit、ei,short、ei,max、ei,rand表示有这四种模型引起的产生测量值 z i z_i zi的概率:
[ e i , h i t e i , s h o r t e i , m a x e i , r a n d ] : = [ p ( c i = h i t ) p ( c i = s h o r t ) p ( c i = m a x ) p ( c i = r a n d ) ] = η [ p h i t ( z i ∣ x i , m ) p s h o r t ( z i ∣ x i , m ) p m a x ( z i ∣ x i , m ) p r a n d ( z i ∣ x i , m ) ] \begin{bmatrix}e_{i,hit}\\e_{i,short}\\e_{i,max}\\e_{i,rand}\end{bmatrix} :=\begin{bmatrix}p(c_i=hit)\\p(c_i=short)\\p(c_i=max)\\p(c_i=rand)\end{bmatrix}=\eta\begin{bmatrix}p_{hit}(z_i|x_i,m)\\p_{short}(z_i|x_i,m)\\p_{max}(z_i|x_i,m)\\p_{rand}(z_i|x_i,m)\end{bmatrix} ⎣⎢⎢⎡ei,hitei,shortei,maxei,rand⎦⎥⎥⎤:=⎣⎢⎢⎡p(ci=hit)p(ci=short)p(ci=max)p(ci=rand)⎦⎥⎥⎤=η⎣⎢⎢⎡phit(zi∣xi,m)pshort(zi∣xi,m)pmax(zi∣xi,m)prand(zi∣xi,m)⎦⎥⎥⎤
式中,符号 : = := :=表示意为。 η \eta η为归一化因子:
η = [ p h i t ( z i ∣ x i , m ) + p s h o r t ( z i ∣ x i , m ) + p m a x ( z i ∣ x i , m ) + p r a n d ( z i ∣ x i , m ) ] − 1 \eta=\bigl[p_{hit}(z_i|x_i,m)+p_{short}(z_i|x_i,m)+p_{max}(z_i|x_i,m)+p_{rand}(z_i|x_i,m)\bigr]^{-1} η=[phit(zi∣xi,m)+pshort(zi∣xi,m)+pmax(zi∣xi,m)+prand(zi∣xi,m)]−1
极大似然估计
极大似然估计的混合参数为归一化的期望:
[ z h i t z s h o r t z m a x z r a n d ] = ∣ Z ∣ − 1 ∑ i [ e i , h i t e i , s h o r t e i , m a x e i , r a n d ] \begin{bmatrix}z_{hit}\\z_{short}\\z_{max}\\z_{rand}\end{bmatrix}=\vert Z \vert^{-1}\sum_i\begin{bmatrix}e_{i,hit}\\e_{i,short}\\e_{i,max}\\e_{i,rand}\end{bmatrix} ⎣⎢⎢⎡zhitzshortzmaxzrand⎦⎥⎥⎤=∣Z∣−1i∑⎣⎢⎢⎡ei,hitei,shortei,maxei,rand⎦⎥⎥⎤
极大似然估计的参数 σ h i t \sigma_{hit} σhit及 λ s h o r t \lambda_{short} λshort可将上述在已知 c i c_i ci取值情况下,计算所得的表达式中的硬分配替换为用期望加权的软分配,从而推广至未知 c i c_i ci取值下的表达式:
σ h i t = 1 ∑ z i ∈ Z e i , h i t ⋅ ∑ z i ∈ Z e i , h i t ( z i − z i i ∗ ) 2 \sigma_{hit}=\sqrt{\frac{1}{\sum_{z_i\in Z}e_{i,hit}}\cdot\sum_{z_i\in Z}e_{i,hit}(z_i-z_i^{i*})^2} σhit=∑zi∈Zei,hit1⋅zi∈Z∑ei,hit(zi−zii∗)2
λ s h o r t = ∑ z i ∈ Z e i , s h o r t ∑ z i ∈ Z e i , s h o r t z i \lambda_{short}=\frac{\sum_{z_i\in Z}e_{i,short}}{\sum_{z_i\in Z}e_{i,short}z_i} λshort=∑zi∈Zei,shortzi∑zi∈Zei,short
参数调节算法
系统输入: 测距仪测量数据集 Z Z Z、机器人位姿数据集 X X X、地图信息 m m m
系统输出: 模型内参 Θ \Theta Θ
A l g o r i t h m l e a r n _ i n t r i n s i c _ p a r a m e t e r s ( Z , X , m ) : 1 : r e p e a t u n t i l c o n v e r g e n c e c r i t e n s a t i s f i e d 2 : f o r a l l z i i n Z d o 3 : η = [ p h i t ( z i ∣ x i , m ) + p s h o r t ( z i ∣ x i , m ) + p m a x ( z i ∣ x i , m ) + p r a n d ( z i ∣ x i , m ) ] − 1 4 : c a l c u l a t e z i ∗ 5 : e i , h i t = η p h i t ( z i ∣ x i , m ) 6 : e i , s h o r t = η p s h o r t ( z i ∣ x i , m ) 7 : e i , m a x = η p m a x ( z i ∣ x i , m ) 8 : e i , r a n d = η p r a n d ( z i ∣ x i , m ) 9 : z h i t = ∣ Z ∣ − 1 ∑ i e i , h i t 10 : z s h o r t = ∣ Z ∣ − 1 ∑ i e i , s h o r t 11 : z m a x = ∣ Z ∣ − 1 ∑ i e i , m a x 12 : z r a n d = ∣ Z ∣ − 1 ∑ i e i , r a n d 13 : σ h i t = 1 ∑ i e i , h i t ⋅ ∑ i e i , h i t ( z i − z i i ∗ ) 2 14 : λ s h o r t = ∑ i e i , s h o r t ∑ i e i , s h o r t z i 15 : r e t u r n Θ = { z h i t , z s h o r t , z m a x , z r a n d , σ h i t , λ s h o r t } \begin{aligned} &Algorithm\quad learn\_intrinsic\_parameters(Z,X,m):\\ 1:&\qquad repeat\enspace until\enspace convergence\enspace criten\enspace satisfied\\ 2:&\qquad\qquad for\enspace all \enspace z_i\enspace in\enspace Z\enspace do\\ 3:&\qquad\qquad\qquad \eta=\bigl[p_{hit}(z_i|x_i,m)+p_{short}(z_i|x_i,m)+p_{max}(z_i|x_i,m)+p_{rand}(z_i|x_i,m)\bigr]^{-1}\\ 4:&\qquad\qquad\qquad calculate\enspace z_i^*\\ 5:&\qquad\qquad\qquad e_{i,hit}=\eta p_{hit}(z_i|x_i,m)\\ 6:&\qquad\qquad\qquad e_{i,short}=\eta p_{short}(z_i|x_i,m)\\ 7:&\qquad\qquad\qquad e_{i,max}=\eta p_{max}(z_i|x_i,m)\\ 8:&\qquad\qquad\qquad e_{i,rand}=\eta p_{rand}(z_i|x_i,m)\\ \\ 9:&\qquad\qquad z_{hit}=\vert Z\vert^{-1}\sum_ie_{i,hit}\\ 10:&\qquad\qquad z_{short}=\vert Z\vert^{-1}\sum_ie_{i,short}\\ 11:&\qquad\qquad z_{max}=\vert Z\vert^{-1}\sum_ie_{i,max}\\ 12:&\qquad\qquad z_{rand}=\vert Z\vert^{-1}\sum_ie_{i,rand}\\ 13:&\qquad\qquad \sigma_{hit}=\sqrt{\frac{1}{\sum_i e_{i,hit}}\cdot\sum_i e_{i,hit}(z_i-z_i^{i*})^2}\\ 14:&\qquad\qquad \lambda_{short}=\frac{\sum_i e_{i,short}}{\sum_i e_{i,short}z_i}\\ 15:&\qquad return\quad \Theta=\{z_{hit},z_{short},z_{max},z_{rand},\sigma_{hit},\lambda_{short}\} \\ \end{aligned} 1:2:3:4:5:6:7:8:9:10:11:12:13:14:15:Algorithmlearn_intrinsic_parameters(Z,X,m):repeatuntilconvergencecritensatisfiedforallziinZdoη=[phit(zi∣xi,m)+pshort(zi∣xi,m)+pmax(zi∣xi,m)+prand(zi∣xi,m)]−1calculatezi∗ei,hit=ηphit(zi∣xi,m)ei,short=ηpshort(zi∣xi,m)ei,max=ηpmax(zi∣xi,m)ei,rand=ηprand(zi∣xi,m)zhit=∣Z∣−1i∑ei,hitzshort=∣Z∣−1i∑ei,shortzmax=∣Z∣−1i∑ei,maxzrand=∣Z∣−1i∑ei,randσhit=∑iei,hit1⋅i∑ei,hit(zi−zii∗)2λshort=∑iei,shortzi∑iei,shortreturnΘ={zhit,zshort,zmax,zrand,σhit,λshort}
第三行,计算归一化因子
第四行,有机器人位姿及地图信息,计算测量值的实际值,也即在地图环境 m m m下机器人处于位姿 x i x_i xi时提取到的测距值 z i ∗ z_i^* zi∗
第五行~第八行,计算由四类噪声模型独立引起产生测量值 z i z_i zi的概率
第九行~第十四行,遍历完成后计算模型的六个内参
算法采用期望最大化算法实现极大似然估计参数,通过迭代数据实现对内参的迭代优化。
算法效果
如图为两组机器人在办公室环境下获取到的10 000个测量数据,左图为声纳传感器测量数据,右图为激光传感器测量数据。图中x轴为计数个数,y轴为传感器测量距离:

其中,测量的期望范围为3m,也即真实距离300cm,最大量程为500cm。用所设计的极大似然估计参数模型测试,得到如下效果图。
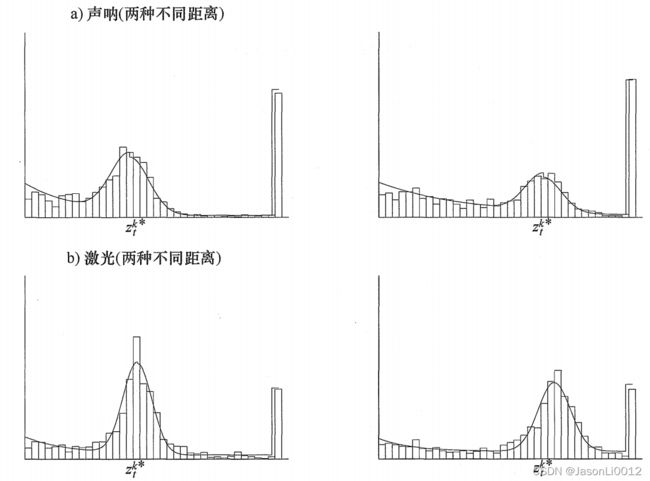
其中,左侧数据为采用上述测试集测试得到的图像( z t k ∗ = 3 z_t^{k*}=3 ztk∗=3);右侧一组则为对照数据的分布图像( z t k ∗ > 3 z_t^{k*}>3 ztk∗>3),由图可以分析得到:
- 实际距离 z t k ∗ z_t^{k*} ztk∗越小,模型测量的数据越精准
- 短距离测量的高斯分布(左侧)较长距离测量的高斯分布(右侧)更窄
- 激光传感器(b组)比超声波传感器(a组)测量更准确,(高斯分布更窄且最大值分布更少)
同时给出一组 180 ° 180\degree 180°激光传感器的扫描环境图,该机器人被已经获得地图信息 m m m的占用栅格地图中走廊位置处,扫描自身周围的环境:

则下图中,给出了地图信息与测量似然 p ( z t ∣ x t , m ) p(z_t|x_t,m) p(zt∣xt,m)映射到 x − y x-y x−y空间的平面图,其中显示颜色越深处,机器人处于该位置的可能性就越高。

上图显示,所有高似然区域处于走廊中,这和机器人的实际情况相符合。同时概率分散在整个走廊上也表明单一传感器难以确切确定机器人位姿。(走廊环境大致相同,无特殊特征,难区分)
同时,后验有规则地分布在两条水平带状区上是因为难以确定机器人的航向,由此形成两种可能的朝向对应两条区域。
局限性
波束模型需要耗费大量计算力,用于对每一个单一测量 z t k z_t^k ztk通过射线投影计算其实际测量 z t k ∗ z_t^{k*} ztk∗。如激光雷达每次扫描将得到一组 180 ° 180\degree 180°的数据,对这180个数据需要逐一进行计算,将耗费大量时间与计算量。
此外,该模型缺乏光滑性。在由许多小障碍的混乱环境中,概率分布 p ( z t k ∣ x t , m ) p(z_t^k|x_t,m) p(ztk∣xt,m)在机器人位姿 x t x_t xt处很不光滑。机器人位姿的小变化将引起测距模型大的位移变化。