并发/并行编程与分布式系统(2)
一、线程同步
本节以线程模型为例,总结常见线程同步方式。对于变量而言,从范围可以简单分为两种:
- 线程局部的变量,比如__thread修饰或者线程私有的变量,只被该线程读取或者修改,不存在并发问题,因此也不存在任何一致性问题
- 非线程局部的变量,如果都是只读的,本身即使多线程,也不存在一致性问题;当同时涉及到写,才需要某种方式来对这些线程进行同步,保证不同的线程访问变量不会获取到无效的值,同时要解决读写、写读、写写冲突。
比如对于写读场景,当一个线程A修改一个变量,另外存在一个线程B需要读取该变量。如果线程A写操作多于一个存储器访问周期,线程B如果介于两个存储器写周期之间,那么就读取到不一致的值。
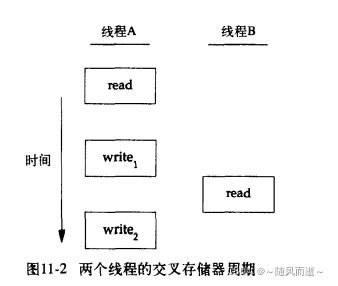
上图FROM <
>
比如对于写写场景:也需要考虑线程同步场景,以变量递增为例i++,该操作其实并不原子,需要从寄存器读取、寄存器内容+1,写回内存等操作,
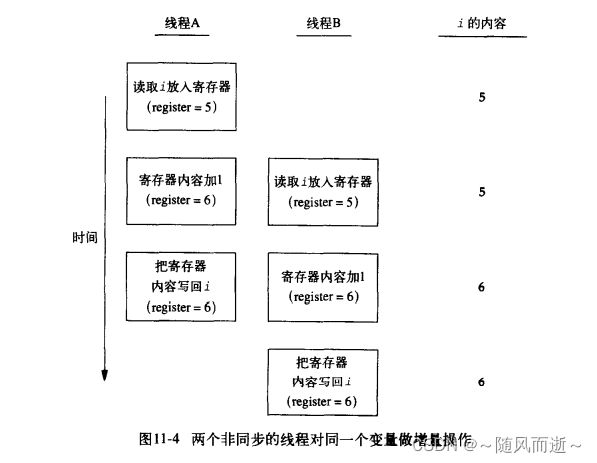
如上图,线程A和B如果没有同步手段,会导致变量最后出现很多结果。
二、同步方式
2.1 互斥量
互斥量-mutex可以保护数据,互斥顾名思义,可以保证同一个时间只有一个线程可以访问共享资源。如果通过posix实现,接口如下:
#include 几点经验总结如下:
- 工业界代码,没有直接裸用上述接口,基本利用RAII(Resource Acquisition Is Initialization)封装mutex的创建、销毁、加锁、解锁这四个操作。不要手工调用lock()和unlock()函数,一切交给栈上的Guard对象的构造和析构函数负责,类似LockGuard等,等离开函数或者临界区,析构的时候自动会调用解锁API
RAII提供以下几个优点:
(1)加锁和解锁保证在同一个线程,而不会跨越线程——栈上的对象很自然保证这一点
(2)不会遗忘加锁,以及重复解锁——构造和析构函数保证
C++11本身支持RAII封装的mutex实现 - mutex有很多类型,包括递归的mutex,实际场景中不建议使用递归的mutext,很容易出问题,出了问题基本很难查
- 当使用多个mutex保护不同的对象和资源,很容易在并发场景下出现死锁,一种避免死锁的方式是,所有的线程按照同一个顺序加锁和解锁,举例,当存在mutexA和mutexB,申请顺序都按照A和B来进行。
2.2 读写锁
读写锁核心思想是操作系统的读者和写者问题,读写锁和互斥量类似,不过区别是,多个读可以同时进行,读写和写写互斥,所以有更好的并行性,特别是读多写少的场景,可以有效提高系统的效率。
如果通过posix实现,接口如下:
#include 2.3 条件变量
条件变量是很重要的线程同步机制, 条件变量和mutex区别和关系如下:
- 语义不同:mutex是加锁原语,用来排他性地访问共享数据,但是不是等待原语。条件变量顾名思义,是等待原语,当等待某种条件满足后,有一种通知和唤醒机制, 如果需要等待某个条件成立,我们应该使用条件变量。
- 联系:条件变量需要和mutex配套一起使用,条件变量需要依赖mutex来保护。
#include 举例而言,有一个队列,有生产者push_queue和消费者pop_queue,伪代码如下:
std::queue<int> queue;
std::mutex mx_;
std::condition_variable cv_;
int pop_queue()
{
std::unique_lock<mutex> lock(mx_);
while (queue.empty()) { //使用循环判断条件
cv_.wait(lock); // 等价于pthread_cond_wait, 这里会原子的解锁mutex,并进入等待,不会和push_queue发生死锁;同时wait执行完毕后会自动重新加锁mutex
}
return queue.top();
}
2.4 信号量-Semaphore
实际生产代码基本没使用信号量(Semaphore), 信号量的意义个人觉得教学或者学习的意义更大,历史遗留的功能。基本使用的同步的场景,都可以通过2.1~2.3解决,且不容易出错。
2.5 自旋锁-Spinlock
自旋锁与互斥量类似。主要区别是阻塞方式不同:
- 互斥量当加不上锁,调用者会休眠阻塞
- 自旋锁不通过休眠进程阻塞,而是在获得锁之前一直处于忙等状态,不会有重新调度的成本。线程在使用自旋锁,等待锁重新可用时因为持续检查是否可用,会非常耗费CPU。所以自旋锁不应该被长时间持有。
Spinlock换个角度理解,其实更是一种拿到锁的方式,而并不是独特的锁形式,本身Mutex/Semaphore的底层实现中,有些地方就用这种方式,这里代码不再展出,有兴趣可以看下内核的相关实现。最简单的实现就是使用一个整型数,0表示未上锁,1表示已上锁。当lock/trylock尝试去原子设置这个整型数。
Spinlock底层可以用访存指令、原子运算指令来实现,而这些指令其实并不是特权指令,完全可以在用户态来实现和运行,从而避免系统调用而导致可能存在的性能问题。因此glic库提供了pthread_spin_***系列的定义和函数来实现用户态的Spinlock
// pshared参数表示进程共享属性:
// PTHREAD_PROCESS_SHARED:自旋锁可以在不同进程的线程间共享。自旋锁被可以访问锁底层内存的线程所获取,即使这些线程属于不同的进程
// PTHREAD_PROCESS_PRIVATE:自旋锁只能被进程内部线程访问
int pthread_spin_init (pthread_spinlock_t *lock, int pshared);
int pthread_spin_destroy (pthread_spinlock_t *lock);
// pthread_spin_lock在获取锁之前一直自旋
int pthread_spin_lock (pthread_spinlock_t *lock);
// pthread_spin_trylock不会导致自旋,而是直接返回。如果不能获得锁即可返回EBUSY
int pthread_spin_trylock (pthread_spinlock_t *lock);
int pthread_spin_unlock (pthread_spinlock_t *lock)
基于以上描述,自旋锁适用于以下情况:
- 锁被持有的时间短,而且线程不希望在重新调度上花费太多成本。
- 如果分析场景,加锁后临界区可能花费很长时间,这时候用自旋锁会占用过多CPU,所以具体场景具体分析
2.6 Futex-(Fast User Mode Mutex)
Futex(快速用户态互斥量)在linux 2.6内核就开始支持,由Hubertus Franke, Matthew Kirkwood, Ingo Molnar and Rusty Russell共同设计完成。
为什么会有Futex? linux下的同步机制可以归为两类:
-
用户态的同步机制
用户态的同步机制本质上是利用原子指令实现的Spinlock。如2.5节所述,Spinlock的lock操作是一个死循环,不断尝试加锁,直到成功。
对于很小的临界区,使用Spinlock是很高效的。因为trylock失败时,可以预期持有锁的线程(进程)会很快退出临界区(释放锁)。所以死循环的忙等待很可能要比进程挂起等待更高效。从而提升了效率。
但是对于大的临界区,忙等待则会浪费过多CPU,特别是当同步机制运用于等待某一事件时。所以这种情况下进程挂起等待是很有必要的。 -
内核同步机制
内核提供了Mutex、semaphore等,内核实现利用了原子指令的Spinlock,同时在此基础上实现了进程的睡眠与唤醒。
因此,当使用Mutex未加锁成功,进程挂起等待。但是最大的问题是每次lock与unlock都是一次系统调用,即使没有锁冲突,也必须要通过系统调用进入内核之后才能识别。因此会有比较大的开销
综上,我们可以看到一种更完美的同步机制应该是:
- 在没有锁冲突的情况下,在用户态利用原子指令就解决问题
- 在有锁冲突的情况下,需要挂起等待时再使用内核提供的系统调用进行睡眠与唤醒
因此有了Futex, 它其实是一种用户态和内核态混合机制。
提供如下两种语义:
// 在uaddr指向的这个锁变量上挂起等待(当*uaddr==val时)
int futex_wait(int *uaddr, int val);
// 唤醒n个在uaddr指向的锁变量上挂起等待的进程/线程
int futex_wake(int *uaddr, int n);
// 原型和系统调用为:
#include - 当调用futex_wait, 内核会动态维护一个跟uaddr指向的锁变量相关的等待队列,同时并不需要为每一个uaddr单独维护一个队列,Futex只维护一个总的队列就行了,所有挂起的进程都放在里面,每个节点能够标识出addr即可。具体优化,等待队列由若干个带spinlock的链表构成,调用futex_wait挂起的进程,通过其uaddr hash到某一个具体的链表上去。每个链表各自持有一把spinlock,将"*uaddr和val的比较操作"与"把进程加入队列的操作"保护在一个临界区中
- Futex支持多个进程之间的互斥锁,内部通过mmap方式来让多个进程之间共享同一块物理内存,然后将锁变量放在这个内存区域中
一些总结:
- Futex是一种用户态和内核态混合机制,Futex从用户态开始,由用户态和核心态协调完成的
- 在锁争用不太激烈情况下,会比传统的同步机制有更出色的性能
- Futex同步机制可以用于进程间同步,也可以用于线程间同步
2.7 barrier-屏障
barrier在CPU、体系结构、同步甚至大规模分布式系统中都有类似的定义,本质上barrier定义了一个边界点,当所有状态到达这个边界点可以做后续的一些事情。这个状态,可以是不同线程的,或者不同进程的,甚至自定义的一些行为。
在线程同步中,barrier是用户协调多个线程并行工作的同步机制。屏障允许多个线程等待,直到所有的合作线程都到达某一点,然后从该点继续执行
// pthread_barrier_t表示一个屏障对象,需要进行初始化和销毁
// attr指定屏障对象属性,NULL表示默认属性
// pthread_barrier_t表示一个屏障对象,需要进行初始化和销毁
int pthread_barrier_init (pthread_barrier_t barrier,const pthread_barrierattr_t *attr, unsigned int count);
int pthread_barrier_destroy (pthread_barrier_t *barrier);
// pthread_barrier_wait函数表明,线程已完成工作,准备等所有其他线程到达
// 调用pthread_barrier_wait的线程在屏障计数未满足条件时,会进入休眠状态。如果该线程是最后一个调用pthread_barrier_wait的线程,就满足了屏障计数,所有线程被唤醒继续执行
// pthread_barrier_wait会在一个线程中返回PTHREAD_BARRIER_SERIAL,其他线程返回0。这使得可以把一个线程当做主线程,它工作在其他所有线程已完成的工作结果上
int pthread_barrier_wait (pthread_barrier_t *barrier);
参考API手册链接:
- pthread_mutex_lock
- pthread_rwlock_init
- pthread_cond_init
- UNIX环境高级编程(第3版) by W.Richard Stevens / Stephen A.Rago