vscode可以配置开发环境c或java。
本篇文章虽然是VsCode挂名,但其实介绍了两款神器: Vscode和Vim, 这两个结合起来,开发效率蹭蹭蹭!!!
之前接触过VsCode但很少用。总感觉写Python不如pycharm香,还得安装各种插件。但最近实习中,发现在项目上有一些较为庞大的推荐架构项目,全是c++代码,后期还要基于项目代码做架构开发,这就涉及到了写C++项目,而且好几个项目一块看,还要满足互相跳转,因为有些变量的定义可能在继承的父类项目里面。
于是就又接触回VSCode, 发现还挺好用,并且插件强大,只用VSCode这一款编译器,安装不同的插件就可以开发不同的项目,比如C++, Java(Scala)和Python项目, 并且还免费。这篇文章来整理下如何用VsCode来写这三种项目,关键是如何进行配置。因为VsCode本质上是一个类似于记事本的编辑器,需要各种插件和环境辅助运行。
大纲如下:
-
VsCode基础小常识(快捷键,连接服务器,配置vim与Git)
-
VsCode写C++、Python与Java项目的相关配置
-
Vim的使用

▲这就满足!大家有想看的内容都可以留言
Ok, let's go!
01 VsCode必备的基础知识
1.1 两个必备快捷键
关于VsCode是啥,安装就是常规的安装软件操作。下载下来之后,打开,是英文版,可以打开扩展, 搜Chinese安装中文包, 界面如下图:
先记住两个快捷键:
-
command+shift+p: 这个是打开命令交互面板, 在命令面板中可以输入命令进行搜索(中英文都可以),然后执行。命名面板中可以执行各种命令,包括编辑器自带的功能和插件提供的功能。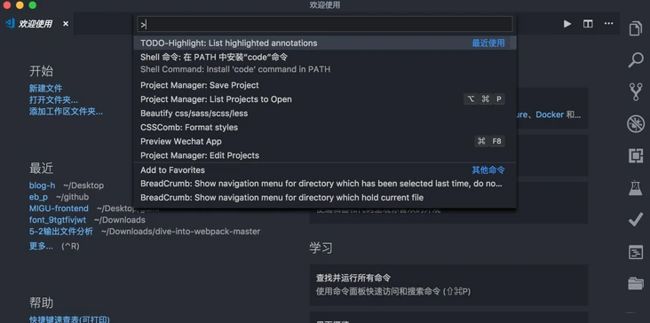
-
comand+,: 进入设置,这里可以进行用户和工作区的设置,像什么代码风格,字体风格各种设置都在这里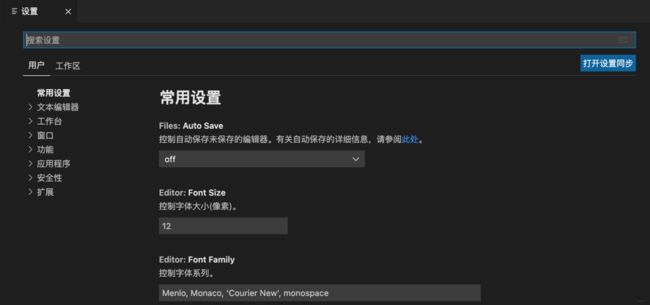
这两个快捷键建议记好。
另外, 这几个常用的快捷键最好也知道:
1.2 安装code
安装后打开命名面板Command+Shift+P,搜索shell命令,点击在PAth中安装code命令,然后在上面菜单栏里面点击终端,开启一个新终端。在这里面使用code命令打开文件或文件夹
code 项目地址或者文件名 # vscode 就会在新窗口中打开该项目或者文件
如果你希望在已经打开的窗口打开文件,可以使用-r参数, 当然也可以菜单栏文件然后open项目,但感觉还是有些麻烦。
1.3 连接远程服务器开发
这个也是需要掌握的必备技能了, 毕竟我们本地的机器啥配置自己清楚, 项目往往都放到服务器上, 而这个就保证了在自己电脑上远程打开服务器的项目并开发。
这个需要安装插件Remote-SSH, command+shift+x打开安装。安装完了之后,左下角绿色的地方点击,然后选择connect to host,输入IP和用户名添加即可, 这样就链接到了远程服务器。
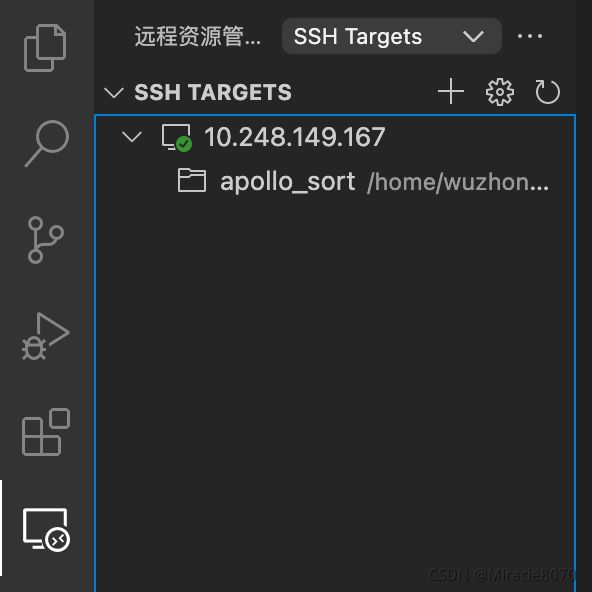
1.4 安装Vim,使得开发更高效
如果vs code上安装vim插件,那么写代码就可以采用vim的方式了, 各种便捷式命令使得开发更加高效。插件搜vim安装,然后点击vim插件,就会看到vim插件的安装说明, 在安装说明里面把第一行在命令行执行:
defaults write com.microsoft.VSCode ApplePressAndHoldEnabled -bool false
然后需要在setting.json中把vim的配置复制进去即可, 这样就变成了vim编辑器, 然后就能进行vim的各种骚操作了。setting.json文件在哪里? command+,进入设置, 然后上面搜索框输入: Run Code Configuration, 在查找的结果中,如果发现setting.json编辑即可。
下面那段拷贝到setting.json中, 这样就会发现进入了vim编辑模式。常用的vim命令还是要会的, 开发更加高效。这个统一整理到最后面, 借着这次,顺便也复习下Vim的使用, Linux下简直神器。
1.5 配置Git
这个功能我目前没用到, 因为我一般喜欢命令行直接Git相关操作,等具体用到了再补充。可以先参考https://blog.csdn.net/weixin_42280089/article/details/88937175
ok, 几个必备知识搞定之后, 就可以开发项目了, 其它功能等用到了可以现查。
02 VsCode写三大编程项目的相关配置
2.1 VsCode写C++项目的配置
这里记录C++项目开发的相关配置,先安装3个插件:
-
C/C++
-
C/C++ Extension Pack
-
CodeLLDB
然后检查下是否按照了clang/clang++ 编译器
clang++ -v
如果未安装,请前往 app store 下载 xcode安装。
准备工作完成,然后打开终端输入下面命令:
mkdir projects
cd projects
mkdir hello
cd hello
code .
# 上述步骤也可以在vscode中创建一个新的hello文件夹代替。
接下来,设置编译器路径, 交互面板下, 输入c/c++选下面这个UI的:
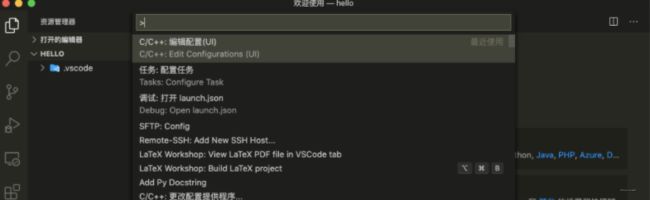
采用默认即可,这里编译器我选了个clang++, 也可以默认。这样完事之后, .vscode目录下,自动多一个c_cpp_properties.json文件, 用于使用vscode自带的代码提示工具,支持代码跳转等, 在这里面进行配置如下:
{
"configurations": [
{
"name": "Mac",
"includePath": [
"${workspaceFolder}/**"
],
"defines": [],
"macFrameworkPath": [],
"compilerPath": "/usr/bin/clang++",
"cStandard": "gnu17",
"intelliSenseMode": "macos-gcc-x64",
"cppStandard": "c++11"
}
],
"version": 4
}
这个完事。
接下来, 需要配置一个tasks.json文件, 用于编译c++文件。
-
交互面板,输入task
-
选择tasks: Configure Default Build Task
-
选择Create tasks.json file from template
-
选择Others, 会在.vscode下面自动创建tasks.json,在编辑器中打开
-
进行如下配置
{
"version": "2.0.0",
"tasks": [
{
"label": "Build with Clang", //这个任务的名字在launch.json最后一项配置
"type": "shell",
"command": "clang++",
"args": [
"-std=c++17",
"-stdlib=libc++",
"-g",
// 生成调试信息,GUN可使用该参数
"${file}",
// file指正在打开的文件
"-o",
// 生成可执行文件
"${fileDirname}/${fileBasenameNoExtension}"
// fileDirname指正在打开的文件所在的文件夹
// fileBasenammeNoExtension指没有扩展名的文件,unix中可执行文件属于此类
],
"options": {
"cwd": "${workspaceFolder}"
},
"problemMatcher": ["$gcc"],
"group": {
"kind": "build",
"isDefault": true
}
}
]
}
这里面需要注意的是第一个label,后面的名字,要和下面这个配置文件名字最后一项保持一致。可行性文件这个保存的是路径位置。
接下来, 配置launch.json, 这个是用于使用vscode自带的debug工具(左侧的小虫图标)
-
交互面板下输入launch,选择Debug:Open launch.json
-
选择LLDB
-
在.vscode下自动生成launch.json文件, 写入配置
{
// 使用 IntelliSense 了解相关属性。
// 悬停以查看现有属性的描述。
// 欲了解更多信息,请访问: https://go.microsoft.com/fwlink/?linkid=830387
"version": "0.2.0",
"configurations": [
{
"name": "Debug",
"type": "lldb",
"request": "launch",
"program": "${workspaceFolder}/${fileBasenameNoExtension}",
"args": [],
"cwd": "${workspaceFolder}",
"preLaunchTask": "Build with Clang"
}
]
}
这样,配置工作完成, 就可以写程序代码了。在该项目下面建立一个helloworld.cpp文件,写入如下代码:
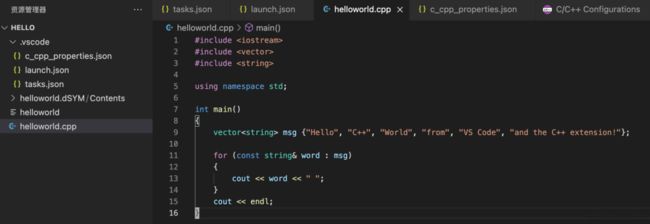
然后command+shift+b就可以进行编译,然后点击右上角的执行按钮即可运行程序了。注意,如果改变helloworld.cpp的位置,比如新建个src目录, 把这个cpp放入src目录,此时上面的task.json和launch.json相应位置需要做出改变。
# task.json
// 生成可执行文件
"${fileDirname}/src/${fileBasenameNoExtension}"
# launch.json
"program": "${workspaceFolder}/src/${fileBasenameNoExtension}",
如果想debug, 就点击左边的小虫子图标, 然后打断点, 在左上角再点击绿色箭头,就进入debug模式了。
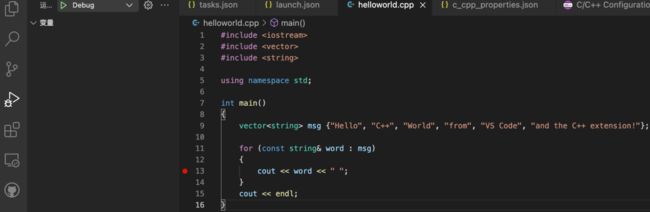
到这里为止, C++环境配置完成。
在运行过程中,我其实遇到了一个c++11的bug:
[Running] cd "/Users/bytedance/projects/hello/" && g++ main.cpp -o main && "/Users/bytedance/projects/hello/"main
main.cpp:9:21: error: expected ';' at end of declaration
vector msg {"Hello", "C++", "World", "from", "VS Code", "and the C++ extension!"};
^
;
main.cpp:11:27: warning: range-based for loop is a C++11 extension [-Wc++11-extensions]
for (const string& word : msg)
^
1 warning and 1 error generated.
这个卡了我好久其实, 上面文章中是没有写的, 这个原因解决方法可能有两个:
-
看看插件里面是否安装了C/C++ Clang Command Adapter, 有的话卸载掉, 这个对我这个没有用
-
进设置,搜Run Code Configuration, 打开setting.json文件, 那里面会有各类语言的执行map, 在里面找到cpp, 把后面的value改成:
"cpp": cd $dir && g++ -std=c++11 $fileName -o $fileNameWithoutExt && $dir$fileNameWithoutExt, 我用了这个方法解决的
至此, c++部分结束。
2.2 VsCode写Python的配置
写大项目还是建议pycharm, yyds, 而如果写一些小demon啥的, 可以使用vscode了,这个配置起来,写代码项目也非常方便, 配置Python环境, 相对简单。
首先,按照Python插件, command+shift+x, 然后搜Python即可安装插件。然后命令行输入命令:
mkdir projects
cd projects
mkdir hello
cd hello
code .
这时候会建立一个hello目录,如果提示code没有定义, 先安装code, 具体方法是command+shift+p, 然后在里面搜shell,就会显示这条命令,点击安装即可。
在hello里面,建立hello.py文件,这时候基于扩展左下角就会显示所用的Python版本, 这时候,其实就能简单运行.py文件了。比如打印个hello world。
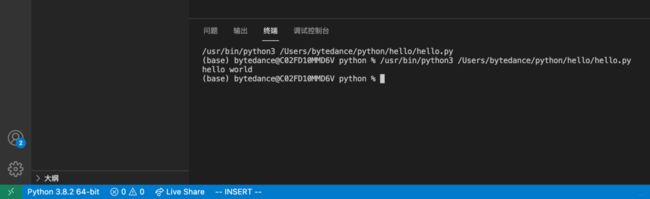
但是如何建立大项目,写更加复杂的代码呢?这里可以安装anaconda, 然后在里面建立虚拟环境,然后在vscode中指定,就可以写了。 点击左下角的Python3.8.2这里。
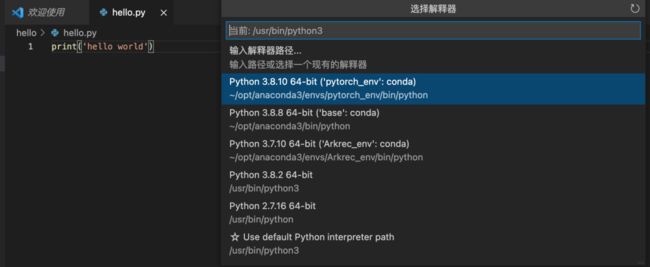
我这里有3个anaconda3的环境,我选Arkrec_env的这个, 这里面专门写tf相关代码的,也安装好了大部分常用的包,点击选择即可。如果想写pytorch代码,我这里可以选择第一个。
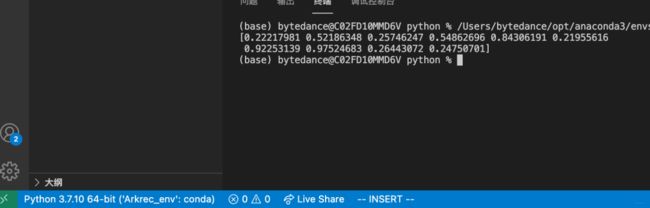
左下角就变了环境。
2.3 VsCode写Java项目的配置
想运行Java项目, 也非常简单,主要包括三步:
-
下载并运行「Extension Pack for Java」;
-
下载并运行「JDK」;
-
配置「Environment Variable」
第一步,安装Extension Pack for Java插件, command+shift+x然后输入这个插件名字, 点击安装。
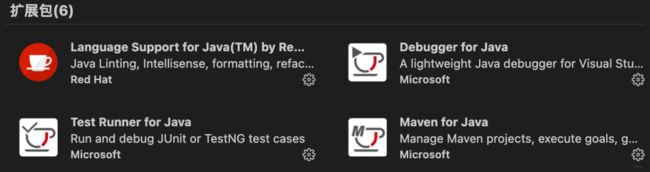
这哥们其实在为我们安装了6个Java必备插件:
-
Language Support for Java(TM) by Red Hat: 运行Java代码
-
Debugger for Java: 调试
-
Java Test Runner: 单元测试
-
Maven for Java: 在Java环境下构建应用程序的软件
安装完毕之后.
第二步,下载并运行「JDK」。「JDK」的全称是「Java Development Kit」,也就是中文所说的「Java开发套件」, 这个套件就是我们开发基于Java语言的软件所需要的一个工具包。 话不多说,直接操作。
command+shift+p进入命令窗口,搜索Java Overview, 在右侧Configure那里,点击Configure Java Runtime,通过VSCode默认的「AdoptOpenJDK」下载入口,选择我们需要下载的「JDK」和「JVM」的版本
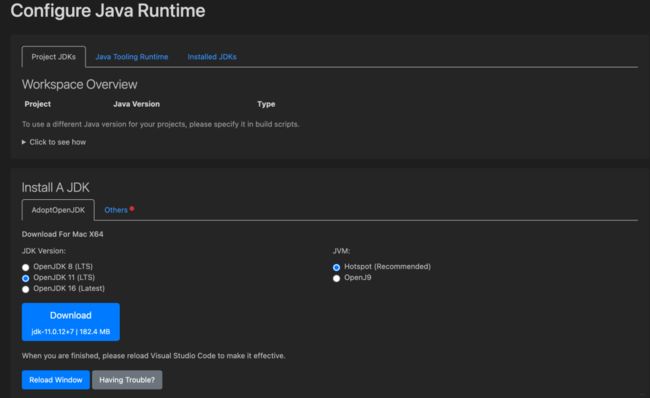
点击Download进入下载页面。下载下这个pkg包之后,点击安装即可。这时候,Reload Window,然后点击上面的Installed JDKs, 就会发现安装的JDK路径以及版本。

第三步,配置「Environment Variable」,也就是中文所说的「环境变量」。command+,进入设置页面, 搜索中输入javahome, 然后点击
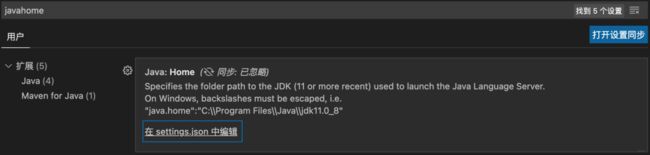
在这里, 把上面的那个JDK的路径复制过来即可。
这样就可以愉快的写Java代码了, 测试下, command+shift+p, 在里面输入Java: create Project,输入项目名,在src文件夹中,选择Run运行Java代码,控制台数据Hello World则为成功。
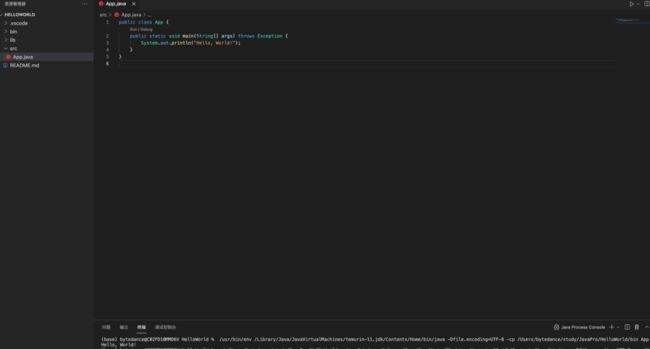
OK, Java配置完成。
这样下来, 就把Vscode打造成了能同时开发Python, C++以及Java项目的神器了, 当然, Vscode还能做更多语言的项目开发, 等后面具体用到了再整理吧, 这玩意辅助上Vim, 项目学习起来也是非常香的哈哈。
03 Vim使用小记
由于目前我对Vim也是只了解到了些皮毛, 所以只整理些关于vim常用的操作。
3.1 三种模式切换
首先,三种模式切换必备:
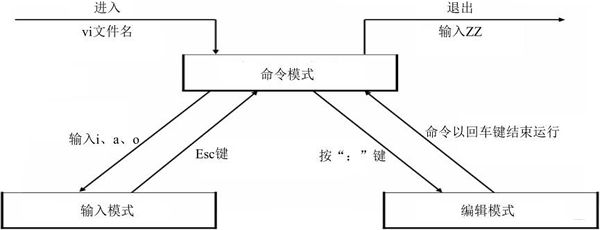
-
从Normal模式到Insert模式(写代码模式)
-
i/a键:当前位置插入 -
A键: 行尾插入 -
I键: 行前插入 -
O键: 上行插入 -
o键: 下行插入
反之jj键或者esc键
-
-
从Normal模式到命令行模式,
":", 反之esc, 命令行里面输入:行号,直接跳到相应行 -
从Normal模式到visual模式,
v键, 反之esc, 这个模式类似于我们用鼠标选中文本的操作。-
v: 字符可视化模式,此模式下目标文本的选择是以字符为单位的,也就是说,该模式下要一个字符一个字符的选中要操作的文本。 -
V: 行可视化模式,此模式化目标文本的选择是以行为单位的,也就是说,该模式化可以一行一行的选中要操作的文本 -
Ctrl+v: 块可视化模式,该模式下可以选中文本中的一个矩形区域作为目标文本,以按下 Ctrl+v 位置作为矩形的一角,光标移动的终点位置作为它的对角
-
visual模式下面复制粘贴操作等都能使用。
3.2 必备命令
刚开始进入vim的时候是Normal模式, 这个模式下是不能写代码的, 在这个模式下需要记住的操作:
-
光标移动
-
字符跳:控制光标移动:
H, J, K, l四个键分别是左, 下,上, 右, 这个是一个字符一个字符的跳 -
单词跳:
w: 一个单词一个单词的跳 ,b: 一个单词一个单词的往回跳, 在前面加n可以跳n个单词。 -
行尾行首:
$跳动当前行尾,^跳到当前行首 -
文件首尾:
G跳到文件末尾,gg跳到文件开头,nG跳到第n行 -
括号匹配:
%跳到与之匹配的括号位置
-
-
删除文本:
x删除当前字符,dd删除当前行,cc键删除当前行并自动进入Insert模式,ndd删除当前及后面的n行,D删除光标到末尾的元素,:a,bd删除a-b行文本内容 -
查找和替换:
/查找内容进行查找,:g/a1/a2/g将文本中所有的a1用a2替换。 -
复制和粘贴:
y复制当前字符,yy复制当前行,nyy复制n行,p粘贴 -
撤销与反撤销:
u撤销一次,U撤销对该行文本做的所有操作,ctrl+r反撤销一次 -
保存退出:
q直接退出,wq保存退出,w保存但不退出, 后面加!强制的意思。"w!"和"wq!"等类似的指令,通常用于对文件没有写权限的时候(显示 readonly),但如果你是文件的所有者或者 root 用户,就可以强制执行。
3.3 Vim多窗口编辑
编辑文件的时候,可能参考另一个文件,如果两个文件切换比较繁琐,可以Vim同时打开两个文件。
命令行输入:vs第二个文件目录, 回车, 此时垂直切分成两个窗口。Ctrl+ww进行两个窗口的切换。
3.4 Vim批量注释
这个也是非常常用的,不操作鼠标,直接通过命令来
-
连续行注释:
:1,10s/^/#/g1-10行行首加"#"注释,^表示行首,g表示执行替换时不询问确认。如果是取消,1,10s/^#//g -
c++和Java的注释用到//, 此时需要转义。
1,10s/^/\/\//g注释1-10行
是否显示行号: set nu 与set nonu
目前我用到的Vim常用操作就是这些了, 如果再遇到新的,会继续补充。
有了它们之后,你就可以和很多重复劳动说再见了。
1. MapStruct

MapStruct是干什么的?
MapStruct是个代码产生器,它能直接根据注解生成 Java 对象对应的转换器。
比如,直接把一个 A 类型的 Java 对象,给转成 B 类型的 Java 对象,只需要在他们之间配置上字段之间的映射关系即可。
为什么在项目里用它?
现在随便一个项目都是多层的,尤其是 Web 项目,经常需要在多层之间做对象模型转换,比如 DTO 转换成 BO。
DTO(Data Transfer Object):数据传输对象,Service 向外传输的对象。
BO(Business Object):业务对象,由 Service 层输出的封装业务逻辑的对象。
但是这种转换工作就像是小时候老师罚我们抄写名人名言 100 遍一样,十分枯燥,还容易出错。
像这样:
public class CarMapper {
CarDto carDoToCarDto(Car car) {
CarDto carDto = new CarDto();
carDto.setCarId(car.getCarId());
carDto.setWheel(car.getWheel());
carDto.setCarType(car.getCarType());
carDto.setCarColor(car.getCarColor());
......
}
}
要是 Car 有几十个字段,像 Car 一样的又有几十个类,你可以想一下,这种繁琐程度。
在 MapStruct 之前,我们都是通过 Apache 或者 Spring 的 BeanUtils 工具,去自动做这种事情。
但是这类工具有两个问题:
(1)性能比较差。
性能差主要是 Apache 的 BeanUtils 这套东西,它每次都要针对字段做是否可读写的检查,还要根据字段生成对应的 PropertyDescriptor。
这些严重影响了它的性能,所以,在阿里 Java 手册里,也不推荐用它。
Spring 的 BeanUtils,虽然精简了很多 Apache 的 BeanUtils 的读写检查以及对应的属性信息记录,但是它依然是通过反射调用,而且是大量反射调用。这种性能也不能令人满意。
(2)运行期做转换,出错就代表损失。
BeanUtils 这类工具,有个统一的名称,叫做 Java 对象映射框架。
它们大部分的实现都是在运行期去执行代码,然后在 Java 对象之间去拷贝对应的值。
运行期间做这种事儿,有个最大的问题——整个项目启动运行后,才能发现错误。比如,转换的时候,类型不一致导致报错。
对于此种情况,咱们大家都知道,这事儿就像开业酬宾没搞好,变成了开业仇宾……
如果能写完代码,编译的时候就发现问题,这种损失就可以避免了。
MapStruct 的引入就是为了解决以上这两个问题。
MapStruct 首先是个代码产生器,它是根据注解去产生一个专门用来转换的工具类,这个工具类,就像我们自己写的 Java 类一样,可以直接被使用,这样就避免了反射。
同时,它产生的转换类也特别简单,就是默认会在两个类型的 Java 对象之间,拷贝同名属性的值。
如果有了配置,属性不同名也可以拷贝。所以它的性能很好。
示例代码如下:
@Mapper
public interface CarMapper {
CarMapper INSTANCE = Mappers.getMapper( CarMapper.class );
@Mapping(target = "seatCount", source = "numberOfSeats")
CarDto carBoToCarDto(Car car);
}
MapStruct由于是个代码产生器,就带来了个巨大的好处,就是这家伙是在编译阶段就会生成对应的类,所以,如果有了类似类型转换不过去的问题,直接就编译报错了,根本不用等到运行才发现。这样的话,就不会造成什么损失,这真是件十分 Nice 的事情。
代码库地址
https://github.com/mapstruct/mapstruct
2. Retrofit

Retrofit 是干什么的?
Retrofit 就是一套 Http 客户端,可以用来访问第三方的 Http 服务。
比如,咱们代码里想调用一个 Http 协议的 URL,就可以用它来访问这个 URL,获取响应结果。
为什么在项目里用它?
在公司里,我们有些项目有如下的特点:
-
不是基于 Spring 的项目;
-
需要经常访问大量的第三方 Http 服务;
-
访问 Http 服务的模型通常是异步回调。
以前的时候,我们访问 Http 服务,都是直接用的 HttpClient。
可是吧,HttpClient 用起来实在够麻烦的。主要也存在两个问题:
(1)请求参数和 URL 拼接实在繁琐。
请求参数和 URL 拼接实在是太烦人了。你想想,每调用一个接口,就需要自己去拼接参数,有的 URL,甚至十几二十个参数需要拼接。
拼接这事儿简单、枯燥、重复,还没有技术含量,但是工作量却不小,时间真的算浪费了。
URIBuilder uriBuilder = new URIBuilder(uriBase);
uriBuilder.setParameter("a", "valuea");
uriBuilder.setParameter("b", "valueb");
uriBuilder.setParameter("c", "valuec");
uriBuilder.setParameter("d", "valued");
uriBuilder.setParameter("e", "valuee");
uriBuilder.setParameter("f", "valuef");
uriBuilder.setParameter("g", "valueg");
uriBuilder.setParameter("h", "valueh");
uriBuilder.setParameter("i", "valuei");
...
(2)异步回调需要自己搞。
异步回调这种模型不好处理,主要就是需要自己去搞线程池,还要对线程池管理,还要考虑出错的重试之类的容错问题,实在麻烦。
所以,我们就需要一套用法简单,不用我们一直搞拼接参数,自己搞线程管理就能完成对第三方 Http 服务访问的库。
其实我们也想过用 Feign 这套框架的。但是,这套东西和 Spring 绑定得太紧了。如果离开 Spring,它的一些功能就没法简单地通过注解直接使用,必须自己写代码调用。
而且,Feign 要实现异步回调方式使用,尤其在协程方面,还是需要自己开发。
这时候,Retrofit 就跳进了我们的选型里。
Retrofit 的模型里,异步回调模型它支持得很好,我们只需要实现一个 Callable 就够了。
并且最清爽的是,它和 Spring 没什么关系。
Retrofit retrofit = new Retrofit.Builder()
.baseUrl("http://xxx.example.com/")
.build();
public interface BlogService {
@GET("blog/{id}")
Call getBlog(@Path("id") int id);
}
BlogService service = retrofit.create(BlogService.class);
Call call = service.getBlog(2);
// 用法和OkHttp的call如出一辙,
// 回调
call.enqueue(new Callback() {
@Override
public void onResponse(Call call, Response response) {
try {
System.out.println(response.body().string());
} catch (IOException e) {
e.printStackTrace();
}
}
@Override
public void onFailure(Call call, Throwable t) {
t.printStackTrace();
}
});
你看,只需要写上这些代码,我们就不需要操心恼人的 Url 拼接和异步回调的管理问题了。全交给了 Retrofit,着实推荐。
代码库地址
https://github.com/square/retrofit
3. Faker

Faker 是干什么的?
Faker 是专门用来产生各种假数据的辅助工具库。
比如,你想产生个和真实数据一样的有姓名、有地址的用户。
为什么在项目里用它?
我们经常需要造数据去测试,但是,如果没有工具辅助,我们自己造数据,存在一些问题。
(1)数据是需要格式的。
很多项目,都需要一些格式上尽量能模仿真实世界的数据。
比如,国内用户的姓名,大部分都是两字、三字的姓名,叫王大,就不能叫 王da 这种。
又比如,国内的地址是 xx市xx区xx街道xx号这种的,就不能胡写一个几个没意义的汉字来当地址。
用贴近真实格式的数据,一来可以测出我们对用户的数据解析是否存在问题,二来可以测出数据库内的字段长度是否有问题。
所以,格式对产生出可靠的测试结果,是很重要的。
(2)数据的量大。
有的测试数据量都是上十万、百万的,这些量级的数据并不是只会产生一次。
甚至几乎每个项目,每个项目的每次测试,可能都会需要新的数据,大量的数据需要能源源不断地产生出来。
更甚至的是,有时候还想要根据我们的要求,在恰当的时候,产生某种关系的数据,或者以某些特定频率产生。比如,产生一批姓王的数据;比如,两秒后产生一次数据。
以上这三种要求综合起来,要是我们自己造数据,那真是要了命了。
与其自己开发,不如用现成的——Faker 库被我们找到了。
Faker 库可以创造三百多种数据,而且还很容易对它进行扩展改造,去产生更多的贴合我们需求的数据。
Faker faker = new Faker();
String name = faker.name().fullName(); // Miss Samanta Schmidt
String firstName = faker.name().firstName(); // Emory
String lastName = faker.name().lastName(); // Barton
String streetAddress = faker.address().streetAddress(); // 60018 Sawayn Brooks Suite 449
几行代码,我们需要的一个用户就有了。
用上 Faker 后,小伙伴们纷纷表示“有更多的时间摸鱼了”。
代码库地址
https://github.com/DiUS/java-faker
4. Wiremock

Wiremock 是干什么的?
Wiremock 是一个可以模拟服务的测试框架。
比如,你想测试访问阿里的支付相关接口的代码逻辑,就可以用它来做测试。
为什么在项目里用它?
比如,我们需要调用银行接口去做资金业务,调用微信接口去做微信登录……这些调用第三方服务的测试存在一个问题:即太过依赖对方的平台。
假如对方平台限制了一些 IP,或者限制了访问频率,又或者就是服务出现了维护,都会影响我们自身的功能测试。
为了解决上述问题,在之前,我们需要自己写代码模仿第三方的接口,等我们自己全部测试没问题了,再去和第三方联调。对于这种模拟出来的接口,我们称作挡板。
可是,这种方式是个苦活,没人愿意干。因为每接入一个第三方,可能都需要做挡板。辛苦做个挡板,就是单纯为了测试。如果第三方的接口做了改造,你这边还得跟着改。
大家可以想想,换成你自己,你愿意做这么件事儿吗?
这时候,Wiremock 的价值就体现出来了。有了 Wiremock,挡板这种东西就再也不存在了,直接在单元测试里模拟测试即可,像这样:
WireMock.stubFor(get(urlPathMatching("/aliyun/.*"))
.willReturn(aResponse()
.withStatus(200)
.withHeader("Content-Type", APPLICATION_JSON)
.withBody("\"testing-library\": \"WireMock\"")));
CloseableHttpClient httpClient = HttpClients.createDefault();
HttpGet request = new HttpGet(String.format("http://localhost:%s/aliyun/wiremock", port));
HttpResponse httpResponse = httpClient.execute(request);
String stringResponse = convertHttpResponseToString(httpResponse);
verify(getRequestedFor(urlEqualTo(ALIYUN_WIREMOCK_PATH)));
assertEquals(200, httpResponse.getStatusLine().getStatusCode());
assertEquals(APPLICATION_JSON, httpResponse.getFirstHeader("Content-Type").getValue());
assertEquals("\"testing-library\": \"WireMock\"", stringResponse);
代码库地址
https://github.com/wiremock/wiremock
结语
虽然 Java 有很多遭人诟病的地方,但是 Java 最重要的优点之一,就是它的生态,有其琳琅满目的各种工具类库。
希望大家都“懒”一点,不要埋头去做无效的苦干,不要自己造轮子,你要相信:
你遇到的问题,基本已经有很多人遇到过了,而且已经被牛人给解决了,把轮子都给你造好了。