1. 借鉴
官方 mapping-types
percolator 查询
官网 percolator 博客
IEEE 754精度
IEEE 754标准
:rank feature
elasticsearch 7.0 新特性之 search as you type
The new elasticsearch datatype, search_as_you_type
自然语言处理NLP中的N-gram模型
自然语言处理中的N-Gram模型详解
ElasticSearch一看就懂之分词器edge_ngram和ngram的区别
Elasticsearch - edgeNGram自动补全
极客时间 阮一鸣老师的Elasticsearch核心技术与实战
2. 开始
主要是按照官方文档进行的一系列操作,顺便写一些自己在测试过程中的心得,例子在官网上都有,看官移步官方文档即可
alias
别名映射为索引中的字段定义另一个名称。别名可用于替代搜索请求中的目标字段,以及选择其他api(如字段功能)。
# 创建索引
PUT /trips
{
"mappings": {
"properties": {
"distance": {
"type": "long"
},
"route_length_miles": {
"type": "alias",
"path": "distance"
},
"transit_mode": {
"type": "keyword"
}
}
}
}
# 索引文档
PUT /trips/_doc/1
{
"distance": 1,
"transit_mode": "walk"
}
PUT /trips/_doc/2
{
"distance": 40,
"transit_mode": "bike"
}
PUT /trips/_doc/3
{
"distance": 120,
"transit_mode": "train"
}
# 查询
GET /trips/_search
{
"query": {
"range": {
"route_length_miles": {
"gte": 39
}
}
}
}
# 查询结果
{
"took" : 0,
"timed_out" : false,
"_shards" : {
"total" : 1,
"successful" : 1,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : {
"value" : 2,
"relation" : "eq"
},
"max_score" : 1.0,
"hits" : [
{
"_index" : "trips",
"_type" : "_doc",
"_id" : "2",
"_score" : 1.0,
"_source" : {
"distance" : 40,
"transit_mode" : "bike"
}
},
{
"_index" : "trips",
"_type" : "_doc",
"_id" : "3",
"_score" : 1.0,
"_source" : {
"distance" : 120,
"transit_mode" : "train"
}
}
]
}
}
使用alias有以下限制
- 目标必须是一个具体的字段,而不是一个对象或另一个字段别名。
- 目标字段必须在创建别名时存在。
- 如果定义了嵌套对象,则字段别名必须具有与其目标相同的嵌套范围。
- 字段别名只能有一个目标。
- 不支持写入字段别名。
- 尝试在索引或更新请求中使用别名将导致失败。
- 别名不能用作copy_to的目标或多字段。
flattened
这种数据类型对于索引具有大量或未知数量的惟一键的对象非常有用。只为整个JSON对象创建一个字段映射,这有助于防止映射爆炸,避免有太多不同的字段映射。
PUT bug_reports
{
"mappings": {
"properties": {
"title": {
"type": "text"
},
"labels": {
"type": "flattened"
}
}
}
}
POST bug_reports/_doc/1
{
"title": "Results are not sorted correctly.",
"labels": {
"priority": "urgent",
"release": ["v1.2.5", "v1.3.0"],
"timestamp": {
"created": 1541458026,
"closed": 1541457010
}
}
}
- 对应注意点3
GET bug_reports/_search
{
"query": {
"term": {"labels": "urgent"}
}
}
- 对应注意点2
GET bug_reports/_search
{
"query": {
"term": {"labels.release": "v1.3.0"}
}
}
使用flattened有以下限制和注意点
- 在索引期间,将为JSON对象中的每个叶值创建标记。这些值被索引为字符串关键字,不会对数字或日期进行分析或特殊处理。
- 可以使用对象点语法[如:person.name]查询
- 查询顶级水平字段将搜索对象中的所有叶值
- 不支持高亮
- 可以使用以下查询term, terms, terms_set, prefix, range,match, multi_match, query_string, simple_query_string, exists
join
用于创建父子文档
[以下总结和例子参看阮一鸣老师的git]
它有以下特性和限制:
- 父文档和子文档是两个独立的文档
- 更新父文档无需更新子文档。子文档被添加,删除或者修改不影响父文档和其他子文档。
- 父子文档必须在相同的分片上
- 指定子文档时,必须指定它的父文档的ID
举个栗子
# 如果已经存在则删除
DELETE /blogs
# 创建索引
PUT /blogs
{
"settings": {
"number_of_shards": 2
},
"mappings": {
"properties": {
"blog_comments_relation": {
"type": "join",
"relations": {
"blog": "comment"
}
},
"content": {
"type": "text"
},
"title": {
"type": "keyword"
},
"creator": {
"type": "keyword"
},
"commentator": {
"type": "keyword"
}
}
}
}
- 我们一步步来分析
如果有人会问:如何区分父子文档包含的属性呢?比如说blog有creator,comment有commentator。因为我当时看的时候就有这种疑问。答案是父子文档的属性都包含在properties中,哪个文档需要,哪个文档添加这个属性即可。
先来看一下各个属性的含义
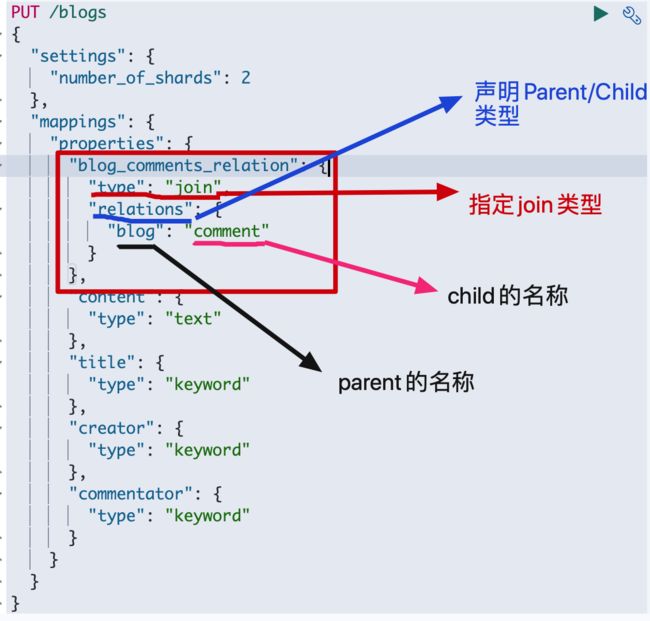
我们来看下如何索引父文档
PUT /blogs/_doc/blog1
{
"title": "测试1",
"content": "这是第一篇测试博客",
"creator": "测试1",
"blog_comments_relation": {
"name": "blog"
}
}
PUT /blogs/_doc/blog2
{
"title": "测试2",
"content": "这是第二篇测试博客",
"creator": "测试2",
"blog_comments_relation": {
"name": "blog"
}
}

那如何索引子文档呢?
PUT /blogs/_doc/comment1?routing=blog1
{
"title": "测试1的评论-1",
"content": "我是测试1的评论-1",
"commentator": "测试1的评论-1",
"blog_comments_relation": {
"name": "comment",
"parent": "blog1"
}
}
PUT /blogs/_doc/comment2?routing=blog1
{
"title": "测试1的评论-2",
"content": "我是测试1的评论-2",
"commentator": "测试1的评论-2",
"blog_comments_relation": {
"name": "comment",
"parent": "blog1"
}
}
PUT /blogs/_doc/comment3?routing=blog1
{
"title": "测试1的评论-3",
"content": "我是测试1的评论-3",
"commentator": "测试1的评论-3",
"blog_comments_relation": {
"name": "comment",
"parent": "blog1"
}
}
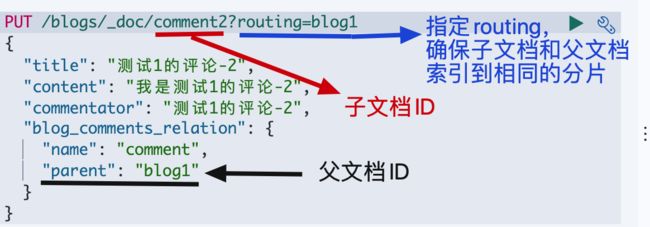
- 父子文档必须在相同的分片上,确保查询join性能
- 指定子文档时,必须指定它的父文档的ID,使用routing参数,分配到相同的分片
查询所有文档
GET /blogs/_search
根据父文档ID查询父文档
GET /blogs/_doc/blog1
根据父文档ID和子文档ID查询子文档
GET /blogs/_doc/comment1?routing=blog1
通过父文档查询其包含子文档的信息
GET /blogs/_search
{
"query": {
"parent_id": {
"type": "comment",
"id": "blog1"
}
}
}
通过子文档返回父文档
GET /blogs/_search
{
"query": {
"has_child": {
"type": "comment",
"query": {
"term": {
"title": {
"value": "测试1的评论-3"
}
}
}
}
}
}
通过父文档查询子文档
GET /blogs/_search
{
"query": {
"has_parent": {
"parent_type": "blog",
"query": {
"term": {
"title": "测试1"
}
}
}
}
}
更新子文档
PUT /blogs/_doc/comment1?routing=blog1
{
"title": "测试1的评论-1-update",
"content": "我是测试1的评论-1-update",
"commentator": "测试1的评论-1-update",
"blog_comments_relation": {
"name": "comment",
"parent": "blog1"
}
}
nested
嵌套对象
- 允许对象数组中的对象被独立索引[如果是普通的对象不需要,因为可以使用.语法来进行检索]
我们为什么要用nested类型呢?举个例子
# 创建索引
PUT /my_movie_sample
{
"mappings": {
"properties": {
"title": {
"type": "text",
"fields": {
"keyword": {
"type": "keyword",
"ignore_above": 256
}
}
},
"actors": {
"properties": {
"first_name": {
"type": "keyword"
},
"last_name": {
"type": "keyword"
}
}
}
}
}
}
# 索引文档
PUT /my_movie_sample/_doc/1
{
"title": "测试电影1",
"actors": [
{
"first_name": "caiser",
"last_name": "hot"
},
{
"first_name": "ga",
"last_name": "el"
}
]
}
- 搜索一下
GET /my_movie_sample/_search
{
"query": {
"bool": {
"must": [
{
"match": {
"actors.first_name": "caiser"
}
},
{
"match": {
"actors.last_name": "el"
}
}
]
}
}
}
- 搜索结果
{
"took" : 0,
"timed_out" : false,
"_shards" : {
"total" : 1,
"successful" : 1,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : {
"value" : 1,
"relation" : "eq"
},
"max_score" : 0.723315,
"hits" : [
{
"_index" : "my_movie_sample",
"_type" : "_doc",
"_id" : "1",
"_score" : 0.723315,
"_source" : {
"title" : "测试电影1",
"actors" : [
{
"first_name" : "caiser",
"last_name" : "hot"
},
{
"first_name" : "ga",
"last_name" : "el"
}
]
}
}
]
}
}
其实这就很奇怪了,我们的文档中只有两个演员[hot caiser]和[el ga],只有这两个人,但是我搜索[el caiser]竟然出来了,是不是很不合理。
如何使用nested类型呢?举个栗子
# 创建索引
PUT /my_movie
{
"mappings": {
"properties": {
"title": {
"type": "text",
"fields": {
"keyword": {
"type": "keyword",
"ignore_above": 256
}
}
},
"actors": {
"type": "nested",
"properties": {
"first_name": {
"type": "keyword"
},
"last_name": {
"type": "keyword"
}
}
}
}
}
}
# 索引文档
PUT /my_movie/_doc/1
{
"title": "测试电影1",
"actors": [
{
"first_name": "caiser",
"last_name": "hot"
},
{
"first_name": "ga",
"last_name": "el"
}
]
}
先来测试一下普通的.语法搜索
GET /my_movie/_search
{
"query": {
"bool": {
"must": [
{
"match": {
"actors.first_name": "caiser"
}
},
{
"match": {
"actors.last_name": "hot"
}
}
]
}
}
}
- 嗯,啥也没有,这是对的,nested类型,使用.语法是无法搜索出来的
nested类型,对应的搜索是nested搜索,例子如下:
GET /my_movie/_search
{
"query": {
"bool": {
"must": [
{
"nested": {
"path": "actors",
"query": {
"bool": {
"must": [
{
"match": {
"actors.first_name": "caiser"
}
},
{
"match": {
"actors.last_name": "hot"
}
}
]
}
}
}
}
]
}
}
}
- 搜索结果
{
"took" : 0,
"timed_out" : false,
"_shards" : {
"total" : 1,
"successful" : 1,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : {
"value" : 1,
"relation" : "eq"
},
"max_score" : 1.3862944,
"hits" : [
{
"_index" : "my_movie",
"_type" : "_doc",
"_id" : "1",
"_score" : 1.3862944,
"_source" : {
"title" : "测试电影1",
"actors" : [
{
"first_name" : "caiser",
"last_name" : "hot"
},
{
"first_name" : "ga",
"last_name" : "el"
}
]
}
}
]
}
}
如果我使用[el caiser]这个来搜索呢?
# 搜索语句
GET /my_movie/_search
{
"query": {
"bool": {
"must": [
{
"match": {
"actors.first_name": "caiser"
}
},
{
"match": {
"actors.last_name": "el"
}
}
]
}
}
}
- 结果
{
"took" : 0,
"timed_out" : false,
"_shards" : {
"total" : 1,
"successful" : 1,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : {
"value" : 0,
"relation" : "eq"
},
"max_score" : null,
"hits" : [ ]
}
}
- 这个就没有被搜索出来,因为没有叫[el caiser]的演员
如果聚合呢?写法相似
# 我们按照first_name聚合
GET /my_movie/_search
{
"size": 0,
"aggs": {
"actors": {
"nested": {
"path": "actors"
},
"aggs": {
"first_name_term": {
"terms": {
"field": "actors.first_name",
"size": 10
}
}
}
}
}
}
- 结果如下:
GET /my_movie/_search
{
"size": 0,
"aggs": {
"actors": {
"nested": {
"path": "actors"
},
"aggs": {
"first_name_term": {
"terms": {
"field": "actors.first_name",
"size": 10
}
}
}
}
}
}
比较一下:nested和join
| nested | join | |
|---|---|---|
| 优点 | 文档存储在一起,读取性能高 | 父子文档可以独立更新 |
| 缺点 | 更新嵌套文档时,需要更新整个文档 | 需要额外的内存维护关系,读取性能相对较差 |
| 适用场景 | 子文档偶尔更新,以查询为主 | 子文档更新频繁 |
percolator
这个一开始我也没搞清楚,看了几篇博客,有一些帮助理解的粘在最上边了,最后合理的中文解释如下:
percolator允许您根据索引注册查询,然后发送包含文档的percolate请求,并从已注册的查询集中获取与该文档匹配的查询。
将它看作是elasticsearch本质上所做的反向操作:不是发送文档、索引它们,然后运行查询,而是发送查询、注册它们,然后发送文档并找出哪些查询与该文档匹配。
用我的话来说就是:
一般的查询都是通过条件筛选匹配的文档,而percolator查询是根据文档筛选匹配的查询,就是输入和输出不同(普通查询:输入(查询条件),输出(匹配的文档);percolator查询:输入(文档),输出(匹配的查询))
接下来,我们以用户订阅了特定主题,当新文章出现时,找出感兴趣的用户为例
# 1. 创建主题订阅索引
PUT topic_subscription
{
"mappings": {
"properties": {
"query": {
"type": "percolator"
},
"topic": { // 主题
"type": "text"
},
"userId": { // 用户ID
"type": "keyword"
}
}
}
}
# 2. 添加用户订阅
#(id为1,2,3的用户订阅了“新闻”主题)
PUT /topic_subscription/_doc/1
{
"userId": [1, 2, 3],
"query": {
"match": {
"topic": "新闻"
}
}
}
#(id为1,2的用户订阅了“军事”主题)
PUT /topic_subscription/_doc/2
{
"userId": [1, 2],
"query": {
"match": {
"topic": "军事"
}
}
}
#(id为2的用户订阅了“计算机”主题)
PUT /topic_subscription/_doc/3
{
"userId": [2],
"query": {
"match": {
"topic": "计算机"
}
}
}
# 3.当来了几篇新文章,查看有哪些用户分别订阅了哪些主题
GET /topic_subscription/_search
{
"query": {
"percolate": {
"field": "query",
"documents": [
{
"topicId": 10001,
"topic": "这是一篇有关军事的文章"
},
{
"topicId": 10002,
"topic": "这是一篇有关新闻的文章"
},
{
"topicId": 10003,
"topic": "计算机是一个好东西-_-"
}]
}
}
}
- 查询结果
- 其中"_percolator_document_slot” 指代的是:输入文档的position,从0开始计数。
{
"took" : 4,
"timed_out" : false,
"_shards" : {
"total" : 1,
"successful" : 1,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : {
"value" : 3,
"relation" : "eq"
},
"max_score" : 1.4120297,
"hits" : [
{
"_index" : "topic_subscription",
"_type" : "_doc",
"_id" : "3",
"_score" : 1.4120297,
"_source" : {
"userId" : [
2
],
"query" : {
"match" : {
"topic" : "计算机"
}
}
},
"fields" : {
"_percolator_document_slot" : [
2
]
}
},
{
"_index" : "topic_subscription",
"_type" : "_doc",
"_id" : "1",
"_score" : 0.8687345,
"_source" : {
"query" : {
"match" : {
"topic" : "新闻"
}
},
"userId" : [
1,
2,
3,
4,
5
]
},
"fields" : {
"_percolator_document_slot" : [
1
]
}
},
{
"_index" : "topic_subscription",
"_type" : "_doc",
"_id" : "2",
"_score" : 0.8687345,
"_source" : {
"userId" : [
1,
2
],
"query" : {
"match" : {
"topic" : "军事"
}
}
},
"fields" : {
"_percolator_document_slot" : [
0
]
}
}
]
}
}
range
好吧,说实话,之前以为只有在查询里面有这个,没有想到它还是种类型
- range有以下类型(大家可以看官方文档的)
| 类型 | 描述 |
|---|---|
| integer_range | 在 - 到 之间 |
| float_range | IEEE 754 单精度 |
| long_range | 在 - 到 之间 |
| double_range | IEEE 754 双精度 |
| date_range | 无符号64位整数 |
| ip_range | 支持IPv4或IPv6(或IPv4和IPv6混合)地址的一组ip值。 |
# 创建索引,包含2个range类型
PUT range_index
{
"mappings": {
"properties": {
"expected_attendees": {
"type": "integer_range"
},
"time_frame": {
"type": "date_range",
"format": "yyyy-MM-dd HH:mm:ss||yyyy-MM-dd||epoch_millis"
}
}
}
}
# 添加一篇文档
PUT range_index/_doc/1
{
"expected_attendees" : {
"gte" : 10,
"lte" : 20
},
"time_frame" : {
"gte" : "2020-04-06 23:00:00",
"lte" : "2020-04-07"
}
}
# 整形范围查询
GET /range_index/_search
{
"query": {
"term": {
"expected_attendees": {
"value": 12
}
}
}
}
# 日期范围查询
GET /range_index/_search
{
"query": {
"range": {
"time_frame": {
"gte": "2020-04-07",
"lte": "2020-04-07 12:00:00"
}
}
}
}
- 同时在查询是可以指定relation,它有如下三种类型
| 类型 | 描述 | 是否默认 |
|---|---|---|
| WITHIN | 必须包含原文档 | 否 |
| CONTAINS | 必须包含在原文档范围内 | 否 |
| INTERSECTS | 有交集即可匹配 | 是 |
-
我们来个图
 within
within
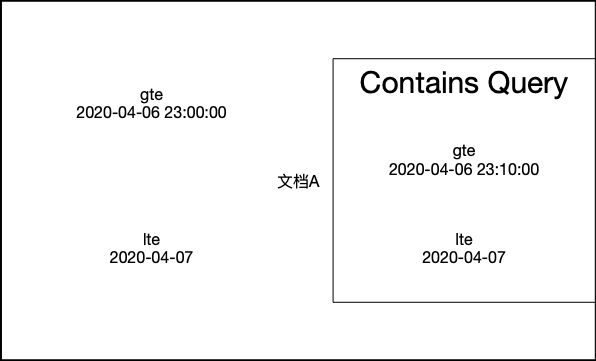

rank_feature
翻译过来是排序功能。
我们来看下它的使用场景和限制[以下均来自官网,翻译而来]
- rank_feature字段只支持单值字段和严格正的值。多值字段和负值将被拒绝。
- rank_feature字段不支持查询、排序或聚合。它们只能在rank_feature查询中使用。
- rank_feature字段仅保留9位重要的精度,转换成大约0.4%的相对误差。
直接上例子【官网自取】
# 创建一个索引,包含两个rank_feature类型
PUT my_index_rank
{
"mappings": {
"properties": {
"page_rank": {
"type": "rank_feature"
},
"url_length": {
"type": "rank_feature",
"positive_score_impact": false
},
"title": {
"type": "text"
}
}
}
}
与分数负相关的排序特性应该将positive_score_impact设置为false(默认为true)。rank_feature查询将使用它来修改评分公式,使评分随特性值的增加而减少,而不是增加。例如在网络搜索中,url长度是一个常用的与分数负相关的特征。
# 添加一篇文档
PUT my_index_rank/_doc/1
{
"page_rank": 12,
"url_length": 20,
"title": "I am proud to be a Chinese"
}
# 好的来搜索一下
GET /my_index_rank/_search
{
"query": {
"rank_feature": {
"field": "page_rank"
}
}
}
- 结果:
{
"took" : 0,
"timed_out" : false,
"_shards" : {
"total" : 1,
"successful" : 1,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : {
"value" : 0,
"relation" : "eq"
},
"max_score" : null,
"hits" : [ ]
}
}

- 额,难道是文档太少???不能够啊,再来几个文档
PUT my_index_rank/_doc/2
{
"page_rank": 12,
"url_length": 20,
"title": "News of the outbreak"
}
PUT my_index_rank/_doc/3
{
"page_rank": 10,
"url_length": 50,
"title": "The Chinese people have overcome the epidemic"
}
POST /my_index_rank/_refresh
- 再来查一遍试试
GET /my_index_rank/_search
{
"query": {
"rank_feature": {
"field": "page_rank"
}
}
}
- 结果
{
"took" : 0,
"timed_out" : false,
"_shards" : {
"total" : 1,
"successful" : 1,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : {
"value" : 0,
"relation" : "eq"
},
"max_score" : null,
"hits" : [ ]
}
}
- e,这。。。
- 所以赶紧上搜一下rank feature到底干啥的,以下摘自借鉴中的文章,因为文章的作者在回复部分解答了疑问,所以在这里说明下,再次感谢。
可用在标签或分类加权
- 这个回答有点模糊。。。我们来个查询的例子
GET my_index_rank/_search?explain=true
{
"query": {
"bool": {
"must": [
{
"match": {
"title": "chinese"
}
}
],
"should": [
{
"rank_feature": {
"field": "page_rank",
"boost": 2
}
},
{
"rank_feature": {
"field": "url_length",
"boost": 0.1
}
}
]
}
}
}
- 再来看下结果什么的[我把explain打开了,所以有点长]
{
"took" : 0,
"timed_out" : false,
"_shards" : {
"total" : 1,
"successful" : 1,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : {
"value" : 2,
"relation" : "eq"
},
"max_score" : 1.0127629,
"hits" : [
{
"_shard" : "[my_index_rank][0]",
"_node" : "7VYDXI3wSdSZLz6AIPQXEw",
"_index" : "my_index_rank",
"_type" : "_doc",
"_id" : "1",
"_score" : 1.0127629,
"_source" : {
"page_rank" : 12,
"url_length" : 20,
"title" : "I am proud to be a Chinese"
},
"_explanation" : {
"value" : 1.0127629,
"description" : "sum of:",
"details" : [
{
"value" : 0.44000342,
"description" : "weight(title:chinese in 0) [PerFieldSimilarity], result of:",
"details" : [
{
"value" : 0.44000342,
"description" : "score(freq=1.0), product of:",
"details" : [
{
"value" : 2.2,
"description" : "boost",
"details" : [ ]
},
{
"value" : 0.47000363,
"description" : "idf, computed as log(1 + (N - n + 0.5) / (n + 0.5)) from:",
"details" : [
{
"value" : 2,
"description" : "n, number of documents containing term",
"details" : [ ]
},
{
"value" : 3,
"description" : "N, total number of documents with field",
"details" : [ ]
}
]
},
{
"value" : 0.42553192,
"description" : "tf, computed as freq / (freq + k1 * (1 - b + b * dl / avgdl)) from:",
"details" : [
{
"value" : 1.0,
"description" : "freq, occurrences of term within document",
"details" : [ ]
},
{
"value" : 1.2,
"description" : "k1, term saturation parameter",
"details" : [ ]
},
{
"value" : 0.75,
"description" : "b, length normalization parameter",
"details" : [ ]
},
{
"value" : 7.0,
"description" : "dl, length of field",
"details" : [ ]
},
{
"value" : 6.0,
"description" : "avgdl, average length of field",
"details" : [ ]
}
]
}
]
}
]
},
{
"value" : 0.5147453,
"description" : "Saturation function on the _feature field for the page_rank feature, computed as w * S / (S + k) from:",
"details" : [
{
"value" : 1.0,
"description" : "w, weight of this function",
"details" : [ ]
},
{
"value" : 11.3125,
"description" : "k, pivot feature value that would give a score contribution equal to w/2",
"details" : [ ]
},
{
"value" : 12.0,
"description" : "S, feature value",
"details" : [ ]
}
]
},
{
"value" : 0.058014184,
"description" : "Saturation function on the _feature field for the url_length feature, computed as w * S / (S + k) from:",
"details" : [
{
"value" : 0.1,
"description" : "w, weight of this function",
"details" : [ ]
},
{
"value" : 0.036132812,
"description" : "k, pivot feature value that would give a score contribution equal to w/2",
"details" : [ ]
},
{
"value" : 0.049926758,
"description" : "S, feature value",
"details" : [ ]
}
]
}
]
}
},
{
"_shard" : "[my_index_rank][0]",
"_node" : "7VYDXI3wSdSZLz6AIPQXEw",
"_index" : "my_index_rank",
"_type" : "_doc",
"_id" : "3",
"_score" : 0.9447938,
"_source" : {
"page_rank" : 10,
"url_length" : 50,
"title" : "The Chinese people have overcome the epidemic"
},
"_explanation" : {
"value" : 0.9447938,
"description" : "sum of:",
"details" : [
{
"value" : 0.44000342,
"description" : "weight(title:chinese in 0) [PerFieldSimilarity], result of:",
"details" : [
{
"value" : 0.44000342,
"description" : "score(freq=1.0), product of:",
"details" : [
{
"value" : 2.2,
"description" : "boost",
"details" : [ ]
},
{
"value" : 0.47000363,
"description" : "idf, computed as log(1 + (N - n + 0.5) / (n + 0.5)) from:",
"details" : [
{
"value" : 2,
"description" : "n, number of documents containing term",
"details" : [ ]
},
{
"value" : 3,
"description" : "N, total number of documents with field",
"details" : [ ]
}
]
},
{
"value" : 0.42553192,
"description" : "tf, computed as freq / (freq + k1 * (1 - b + b * dl / avgdl)) from:",
"details" : [
{
"value" : 1.0,
"description" : "freq, occurrences of term within document",
"details" : [ ]
},
{
"value" : 1.2,
"description" : "k1, term saturation parameter",
"details" : [ ]
},
{
"value" : 0.75,
"description" : "b, length normalization parameter",
"details" : [ ]
},
{
"value" : 7.0,
"description" : "dl, length of field",
"details" : [ ]
},
{
"value" : 6.0,
"description" : "avgdl, average length of field",
"details" : [ ]
}
]
}
]
}
]
},
{
"value" : 0.46920824,
"description" : "Saturation function on the _feature field for the page_rank feature, computed as w * S / (S + k) from:",
"details" : [
{
"value" : 1.0,
"description" : "w, weight of this function",
"details" : [ ]
},
{
"value" : 11.3125,
"description" : "k, pivot feature value that would give a score contribution equal to w/2",
"details" : [ ]
},
{
"value" : 10.0,
"description" : "S, feature value",
"details" : [ ]
}
]
},
{
"value" : 0.035582155,
"description" : "Saturation function on the _feature field for the url_length feature, computed as w * S / (S + k) from:",
"details" : [
{
"value" : 0.1,
"description" : "w, weight of this function",
"details" : [ ]
},
{
"value" : 0.036132812,
"description" : "k, pivot feature value that would give a score contribution equal to w/2",
"details" : [ ]
},
{
"value" : 0.019958496,
"description" : "S, feature value",
"details" : [ ]
}
]
}
]
}
}
]
}
}
-
这太长了,没关系,我截个图,我们以其中一个为例,就更好看了。
 以查询出的第一篇文档为例
以查询出的第一篇文档为例
我们可以看到,这篇文档的分数包含三部分:。match匹配title为chinese的权重,。page_rank的权重,。url_length的权重;最后做一次加法。对于explain的详细解释,会在后面的文章中讲到。// TODO
search-as-you-type
要理解这种类型,先明白N-gram模型,这个我在借鉴中有些,大家看一下。
token_count
我们来直译一下官网的解释:类型为token_count的字段实际上是一个整数字段,它接受字符串值,分析它们,然后为字符串中的令牌数量建立索引。
- 在我看来就是统计一个句子的分词数量,这取决于用的分词器
# 创建索引
PUT /my_index_token_count_chinese_city
{
"mappings": {
"properties": {
"city": {
"type": "text",
"fields": {
"length": {
"type": "token_count",
"analyzer": "ik_smart"
}
}
}
}
}
}
# 添加文档
PUT /my_index_token_count_chinese_city/_doc/1
{
"city":"大连这座城市"
}
PUT /my_index_token_count_chinese_city/_doc/2
{
"city":"沈阳这座城市"
}
PUT /my_index_token_count_chinese_city/_doc/3
{
"city":"北京这座城市"
}
PUT /my_index_token_count_chinese_city/_doc/4
{
"city":"青岛这座城市"
}
# 以青岛为例查看一下分词情况
GET /_analyze
{
"tokenizer": "ik_smart",
"text": "青岛这座城市"
}
- 分词结果
{
"tokens" : [
{
"token" : "青岛",
"start_offset" : 0,
"end_offset" : 2,
"type" : "CN_WORD",
"position" : 0
},
{
"token" : "这座",
"start_offset" : 2,
"end_offset" : 4,
"type" : "CN_WORD",
"position" : 1
},
{
"token" : "城市",
"start_offset" : 4,
"end_offset" : 6,
"type" : "CN_WORD",
"position" : 2
}
]
}
- 执行一下查询
GET /my_index_token_count_chinese_city/_search
{
"query": {
"term": {
"city.length": {
"value": 3
}
}
}
}
- 看一下查询结果
{
"took" : 0,
"timed_out" : false,
"_shards" : {
"total" : 1,
"successful" : 1,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : {
"value" : 4,
"relation" : "eq"
},
"max_score" : 1.0,
"hits" : [
{
"_index" : "my_index_token_count_chinese_city",
"_type" : "_doc",
"_id" : "1",
"_score" : 1.0,
"_source" : {
"city" : "大连这座城市"
}
},
{
"_index" : "my_index_token_count_chinese_city",
"_type" : "_doc",
"_id" : "2",
"_score" : 1.0,
"_source" : {
"city" : "沈阳这座城市"
}
},
{
"_index" : "my_index_token_count_chinese_city",
"_type" : "_doc",
"_id" : "3",
"_score" : 1.0,
"_source" : {
"city" : "北京这座城市"
}
},
{
"_index" : "my_index_token_count_chinese_city",
"_type" : "_doc",
"_id" : "4",
"_score" : 1.0,
"_source" : {
"city" : "青岛这座城市"
}
}
]
}
}
constant_keyword
常量关键字是关键字字段的专门化,用于索引中的所有文档都具有相同的值的情况。
它有以下限制:
- 如果映射中没有提供值,则该字段将根据第一个索引文档中包含的值自动配置自身。虽然这种行为可能很方便,但是请注意,这意味着如果一个有害文档的值是错误的,那么它可能会导致所有其他文档被拒绝。
- 字段的值在设置之后不能更改
- 不允许提供与映射中配置的值不同的值
但是我尝试了es 7.2.0里,并没有这个类型。。。以下是官网的例子
PUT logs-debug
{
"mappings": {
"properties": {
"@timestamp": {
"type": "date"
},
"message": {
"type": "text"
},
"level": {
"type": "constant_keyword",
"value": "debug"
}
}
}
}
POST logs-debug/_doc
{
"date": "2019-12-12",
"message": "Starting up Elasticsearch",
"level": "debug"
}
POST logs-debug/_doc
{
"date": "2019-12-12",
"message": "Starting up Elasticsearch"
}
wildcard
直接翻译一下官网:
通配符字段存储为通配符类grep查询优化的值。通配符查询可以在其他字段类型上使用,但是会受到一些限制:
- 文本字段(text)将任何通配符表达式的匹配限制为单个标记,而不是字段中保存的原始整数值
- 关键字字段(keyword)是未标记的,但是执行通配符查询的速度很慢(特别是具有领先通配符的模式)。
通配符字段使用ngrams在内部索引整个字段值,并存储整个字符串。该索引用作一个粗略的过滤器,以减少值的数量,然后通过检索和检查完整的值进行检查。这个字段特别适合在日志行上运行类似grep的查询。存储成本通常比关键字字段的存储成本要低,但是对完全匹配项的搜索速度要慢一些。
另外,
我在es7.2.0中也创建该类型失败,以下是官网的例子
PUT my_index
{
"mappings": {
"properties": {
"my_wildcard": {
"type": "wildcard"
}
}
}
}
PUT my_index/_doc/1
{
"my_wildcard" : "This string can be quite lengthy"
}
POST my_index/_doc/_search
{
"query": {
"wildcard" : {
"value": "*quite*lengthy"
}
}
}
3. 大功告成
额,这一篇耗时比较长,对类型也有了一个比较全面的认识。
还是那句话,好记性不如烂笔头。
