新版javase必备核心知识篇
写在前面
本文章共1万字,涉及知识包括,基础的运算符,数据类型,集合源码等知识,可用于八股文复习,也可用于加深知识。
后续还将继续更新
1.并发编程核心知识点
2.中间件之消息队列
3.Mysql核心知识点
4.http协议核心知识点
5.Spring-Mybatis核心知识点
6.分布式缓存核心知识点
如果想了解以上知识,关注我,不迷路!
新版javase必备核心知识篇
知识1. 你知道 运算符 &和&&、|和||的区别吗?
& 和 && 都可以实现 和 这个功能
区别:& 两边都运算,⽽ && 先算 && 左侧,若左侧为false 那么右侧就不运算,判断语句中推荐使⽤ &&,效率更⾼
| 和 || 和上面类似
区别:||只要满⾜第⼀个条件,后⾯的条件就不再判断,⽽|要对所有的条件进⾏判断
把&&和||称之为短路运算符
知识2. 写个方法法,传递两个非0的int数值进去,实现变量交换的方式,有几种方式?
第一种
最简单的,直接定义一个中间变量嘛,这个不多说。
第二种如下:
public static void swap(int a, int b){
System.out.printf("a=%d, b=%d",a,b);
a = a + b;
b = a - b ;
a = a - b;
System.out.printf("\na=%d, b=%d",a,b);
}
其实上面这种方法大家可以理解为数学上的配凑法,我们想要交换a,b的值,又不用到中间变量,除了第三种方法,我们只有去利用a,b本身的值。
第三种如下
public static void swap2(int a, int b){
System.out.printf("a=%d, b=%d",a,b);
a = a^b;
b = b^a; //改成b=a^b也可以
a = a^b;
System.out.printf("\na=%d, b=%d",a,b);
}
这种方法就是利用异或运算相同为0,不同为1的特点,因此我们可以知道, ⼀个数和自身异或结果是0 ,进而⼀个数与另⼀个数异或两次是其本身,接下来就是继续利用配凑法实现交换的目的。
知识点3. java数据类型分类
分为基础数据类型与引用数据类型
基础数据类型:byte、short、int、long、float、double、char、boolean
引用数据类型:其他都是引用类型
也就是说String和Enum也是引用类型
基本数据类型和引用数据类型区别
1.基本数据类型不用new, 包装类型需要使用new关键字来在堆中分配存储空间
2.存储方式及位置不同,基本类型是直接将变量值存储在栈中,包装类型是将对象放在堆中,然后通过引用来使用
3.初始值不同,基本类型的初始值如int为0,boolean为false,包装类型的初始值为null
知识点4. == 和equals的区别
基本数据类型⽐较 要⽤==判断是否相等
而对于引⽤数据类型: ==⽐较的是内存地址是否⼀样,不同对象的内存地址不⼀样,equals⽐较的是具体的内容, 也可以让开发者去定义什么条件去判断两个对象是否⼀样
知识点5.下⾯代码 的try-catch-finally语句,try⾥⾯有个return, finally⾥⾯也有return,结果会返回什么?为什么
public static int test1() {
int a = 1;
try {
System.out.println(a / 0);
a = 2;
} catch (ArithmeticException e) {
a = 3;
return a;
} finally {
a = 4;
}
return a;
}
public static int test2() {
int a = 1;
try {
System.out.println(a / 0);
a = 2;
} catch (ArithmeticException e) {
a = 3;
return a;
} finally {
a = 4;
return a;
}
}
答案:
在执⾏try、catch中的return之前⼀定会执⾏finally中的代码(如果finally存在),如果finally中有return语句,就会直接执⾏finally中的return⽅法,所以finally中的return语句⼀定会被执⾏的
执⾏流程:finally执⾏前的代码⾥⾯有包含return,则会先确定return返回值,然后再执⾏finally的代码,最后再执⾏return。
所以答案分别是3,4.
知识点5. 常用字符串String
问题1: String str = new String(“swust”); 创建了几个对象?
答案:一个或两个
**创建⼀个对象:**常量池存在,则直接new⼀个对象;
**创建两个对象:**常量池不存在,则在常量池创建⼀个对象,也在堆里面创建⼀个对象
问题2: 下⾯是⽐较什么?输出结果是什么?为什么是这样的结果 String
str1= new String("swust");
String str2= "swust";
String str3= "swust";
System.out.println(str1 == str2)
System.out.println(str2 == str3)
答案:
前面说过,比较较引用的内存地址是否⼀样
因此第⼀个输出false: new 创建新的对象会开辟新的空间,所以地址不⼀样
第⼆个是true:都是从常量池里面获取,“swust” 存在于常量池中
问题3: 写出下⾯代码的各个结果?如果需要两个都为true,应该怎么修改
String s1 = "swust";
String s2 = s1 + ".cn";
String s3 = "swust" + ".cn"; //常量 + 常量 = 来⾃常亮池
System.out.println(s2 == "swust.cn");
System.out.println(s3 == "swust.cn");
答案
我们首先需要知道,对String类型来说,将变量 + 常量 赋值给另一个对象,这这个对象将来自堆,而常量+常量将来自常量池
因此
第⼀条语句打印的结果为false, s2 = s1 + “.cn”, //变量+常量=堆
构建了⼀个新的string对象,并将对象引⽤赋予s2变量,常量池中的地址不⼀样,但是值⼀样。
第⼆条语句打印的结果为true,因为javac编译可以对【字符串常量】直接相加的表达式进行优化,不⽤等到运⾏期再去进⾏加法运算处理,⽽是直接将其编译成⼀个这些常量相连的结果.
如果需要第⼀个输出为true,只需要把变量改为常量即可 fianl String s1 = “swust”;
对于这三个问题做个小结
不管是new String(“XXX”)和直接常量赋值, 都会在字符串常量池创建.只是new String(“XXX”)方式会在堆中创建⼀个对象去指向常量池的对象, 普通的常量赋值是直接赋值给变量
问题4. String、StringBuffer与StringBuilder的相同与区别?分别在哪些场景下使用
相同
三者都是final, 不允许被继承,在本质都是char[]字符数组实现
区别
1.String、StringBuffer与StringBuilder中,String是不可变对象,另外两个是可变的
可变是指对其追加等操作后仍是它自己本身,不可变就是将会在常量池新增一个对象。
2.StringBuilder 效率更快,因为它不需要加锁,不具备多线程安全StringBuffer里面操作⽅法⽤synchronized ,效率相对更低,是线程安全的;
使用场景:
操作少量的数据⽤String,但是常改变内容且操作数据多情况下最好不要⽤ String ,因为每次⽣成中间对象性能会降低
单线程下操作⼤量的字符串⽤StringBuilder,虽然线程不安全但是不影响多线程下操作⼤量的字符串,且需要保证线程安全 则⽤StringBuffer
知识点6. ⾯向对象的四大特性
1.抽象
关键词abstract声明的类叫作抽象类,abstract声明的方法叫抽象方法。⼀个类里包含了⼀个或多个抽象方法,类就必须指定成抽象类。抽象方法属于⼀种特殊方法,只含有⼀个声明,没有方法体
例如,实现支付时,默认实现本地支付,然后通过抽象实现微信⽀付,⽀付宝⽀付,银⾏卡⽀付等。
2.封装
封装是把过程和数据包围起来,对数据的访问只能通过已定义的接口即方法。
在java中通过关键字private,protected和public实现封装。
封装把对象的所有组成部分组合在⼀起,封装定义程序如何引用对象的数据, 封装实际上使用⽅法将类的数据隐藏起来,控制⽤户对类的修改和访问数据的程度。 适当的 封装可以让代码更容易理解和维护(减少了外部对变量的不正常访问,修改等),也加强了代码的安全性。
3.继承
子类继承⽗类的特征和行为,使得子类对象具有父类的⽅法和属性,父类也叫基类,具有公共的方法和属性
例如之前上面讲到过的例子
abstract class AbsPay{
}
WeixinPay extends AbsPay{
}
AliPay extends AbsPay{
}
4.多态
同⼀个⾏为具有多个不同表现形式的能⼒
优点:减少耦合、灵活可拓展,⼀般是继承类或者重写方法实现
知识点7. 接口相关
问题1.Overload和Override的区别?
重载Overload:表示同⼀个类中可以有多个名称相同的方法,但这些方法的参数列表各不相同,参数个数或类型不同
重写Override:表示⼦类中的方法可以与父类中的某个方法的名称和参数完全相同
问题2. 接口是否可以继承接口?接口是否支持多继承?类是否支持多继承?接口里面是否可以有方法实现
接口⽀持多继承, 类不⽀持多个类继承,⼀个类只能继承⼀个类,但是能实现多个接⼝,接⼝能继承另⼀个接⼝,接口的继承使用extends关键字,和类继承⼀样
jdk8之后,加了default关键字的方法可以有方法实现
补充:
解JDK8里面接口新特性
interface中可以有static方法,但必须有方法实现体,该方法只属于该接口,可以通过接口名直接调用该方法
接⼝中新增default关键字修饰的⽅法,default方法只能定义在接⼝中,可以在子类或子接⼝中被重写,default定义的方法必须有方法体
父接口的default方法如果在子接口或子类被重写,那么子接口实现对象、⼦类对象,调用该方法,以重写为准
本类、接⼝如果没有重写父类(即接口)的default⽅法,则在调用default方法时,使用父类(接口) 定义的default方法逻辑
知识点8. 集合框架里面List基础
问题1.Vector和ArrayList、LinkedList联系和区别?分别的使⽤场景
ArrayList:底层是数组实现,线程不安全,查询和修改⾮常快,但是增加和删除慢
LinkedList: 底层是双向链表,线程不安全,查询和修改速度慢,但是增加和删除速度快
Vector: 底层是数组实现,线程安全的,操作的时候使⽤synchronized进⾏加锁
使用场景
Vector已经很少用了
增加和删除场景多则用LinkedList
查询和修改多则用ArrayList
问题2. 如果需要保证线程安全,ArrayList应该怎么做,有几种方式
方式⼀:自己写个包装类,根据业务⼀般是add/update/remove加锁
方式⼆:Collections.synchronizedList(new ArrayList<>()); 使用synchronized加锁
方式三:jdk8,CopyOnWriteArrayList<>() 使用ReentrantLock加锁,jdk11用了synchronized,因为在jdk6之前,synchronized是重量级锁,但是在jdk6之后,synchronized一直在优化,加入了自旋,锁销除,轻量级锁等
问题3. CopyOnWriteArrayList和Collections.synchronizedList实现线程安全有什么区别, 使用场景是怎样的?
CopyOnWriteArrayList:执行修改操作时,会拷贝⼀份新的数组进⾏操作(add、set、remove等),代价十分昂贵,在执⾏完修改后将原来集合指向新的集合来完成修改操作,(jdk8)源码里面用ReentrantLock可重入锁来保证不会有多个线程同时拷贝⼀份数组
场景:读性能高,适⽤读操作远远大于写操作的场景中使用(读的时候是不需要加锁的,直接获取,删除和增加是需要加锁的)
get操作源码如下:

add操作源码如下:
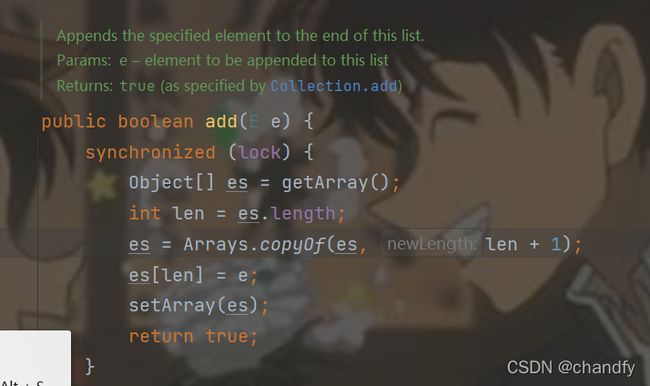
Collections.synchronizedList:线程安全的原因是因为它几乎在每个⽅法中都使⽤了synchronized同步加锁
**场景:**写操作性能比CopyOnWriteArrayList好(因为CopyOnWriteArrayList还需要多开辟空间),读操作性能并不如CopyOnWriteArrayList
其部分源码如下:
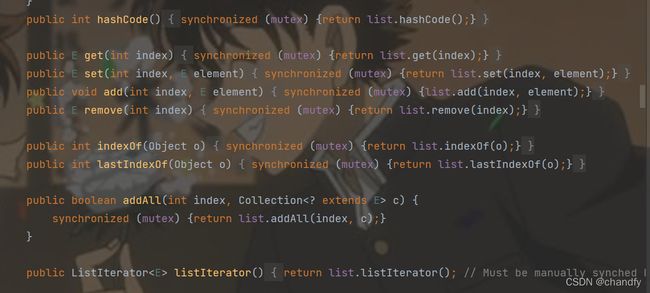
问题4. CopyOnWriteArrayList的设计思想是怎样的,有什么缺点?
设计思想:读写分离+最终⼀致(见add,与get操作源码)
缺点:内存占用问题,写时复制机制,内存⾥会同时驻扎两个对象的内存,旧的对象和新写⼊的对象,如果对象大则容易发⽣Yong GC和Full GC
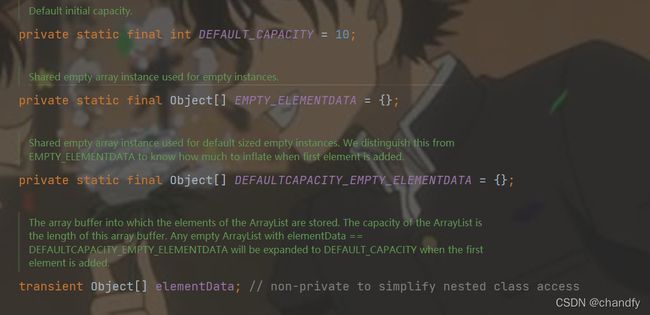
问题5. ArrayList的扩容机制
注意:JDK1.7之前ArrayList默认大小是10,JDk1.7之后是0
未指定集合容量,默认是0,若已经指定⼤⼩则集合大小为指定的(推荐如果能够确定该集合容量就指定);
当集合第⼀次添加元素的时候,集合⼤小扩容为10
ArrayList的元素个数⼤于其容量,扩容的大小= 原始大小+原始小/2
对应jdk源码如下:

知识点9. 集合框架Map基础知识
问题1. 有哪些Map常见的实现 ?
HashMap、Hashtable、LinkedHashMap、TreeMap,ConcurrentHashMap
问题2. HashMap和Hashtable 的区别
HashMap:底层是基于数组+链表,⾮线程安全的,默认容量是16、允许有空的健和值
Hashtable:基于哈希表实现,线程安全的(加了synchronized),默认容量是11,不允许有null的健和值
问题3.对象的 hashCode()和equals()方法及使用场景
hashcode
顶级类Object里面的方法,所有的类都是继承Object,返回是⼀个int类型的数根据⼀定的hash规则(存储地址,字段,⻓度等),映射成⼀个数组,即散列值
equals
顶级类Object⾥⾯的⽅法,所有的类都是继承Object,返回是⼀个boolean类型根据⾃定义的匹配规则,⽤于匹配两个对象是否⼀样,⼀般逻辑如下
1.判断地址是否⼀样
2.⾮空判断和Class类型判断
/3强转
4.对象里面的字段⼀⼀匹配
使用场景:
对象⽐较、或者集合容器⾥⾯排重、比较、排序
问题4. HashMap和TreeMap使用场景
hashMap: 散列桶(数组+链表),可以实现快速的存储和检索,但是确实包含⽆序的元素,适⽤于在map中插⼊删除和定位元素
treeMap:
使用存储结构是⼀个平衡⼆叉树->红⿊树,可以⾃定义排序规则,要实现Comparator接 口,能便捷的实现内部元素的各种排序,但是⼀般性能比HashMap差,适⽤于安装自然然排序或者自定义排序规则
问题5. Set和Map的关系
先看源码:

 可以从源码看出,set核心就是不保存重复的元素,但存储⼀组唯⼀的对象
可以从源码看出,set核心就是不保存重复的元素,但存储⼀组唯⼀的对象
set的每⼀种实现都是对应Map⾥⾯的⼀种封装,HashSet对应的就是HashMap,treeSet对应的就是treeMap
问题6. 常见Map的排序规则
按照添加顺序的LinkedHashMap,按照自然排序使用TreeMap,自定义排序TreeMap(Comparetor c)
问题7. 如果需要线程安全,且效率高的Map,应该怎么选?
多线程环境下可以⽤concurrent包下的ConcurrentHashMap, 或者使用
Collections.synchronizedMap(),ConcurrentHashMap虽然是线程安全,但是他的效率⽐Hashtable要⾼很多
问题8. 为什么Collections.synchronizedMap后是线程安全的?
使用Collections.synchronizedMap包装后返回的map是加锁的
问题9. HashMap的底层实现
HashMap底层(数组+链表+红⿊树 jdk8才有红⿊树)
数组中每⼀项是⼀个链表,即数组和链表的结合体
Node
在JDK1.8中,链表的⻓度⼤于8,链表会转换成红⿊树
问题10. 什么是Hash碰撞?常见的解决办法有哪些,hashmap采⽤哪种方法
hash碰撞的意思是不同key计算得到的Hash值相同,需要放到同个bucket中
常见的解决办法:链表法(拉链法)、开放地址法(开放寻址法)、再哈希法等
HashMap采用的是链表法
问题11. HashMap底层是 数组+链表+红黑树,为什么要用这几类结构呢?
数组 Node
链表的作用是解决hash冲突,将hash值⼀样的对象存在⼀个链表放在hash值对应的槽位
红黑树 : JDK8使⽤红黑树来替代超过8个节点的链表,主要是查询性能的提升,从原来的O(n)到O(logn),通过hash碰撞,让HashMap不断产生碰撞,那么相同的key的位置的链表就会不断增长,当对这个Hashmap的相应位置进行查询的时候,就会循环遍历这个超级大的链表,性能就会下降,所以改用红黑树
问题12 . 为啥选择红黑树而不用其他树,比如⼆叉查找树,为啥不⼀直开始就用红黑树,而是到8的长度后才变换
⼆叉查找树在特殊情况下也会变成⼀条线性结构,和原先的链表存在⼀样的深度遍历问题,查找性能就会慢,使用红⿊树主要是提升查找数据的速度,红黑树是平衡⼆叉树的⼀种,插⼊新数据后会通过左旋,右旋、变
⾊等操作来保持平衡,解决单链表查询深度的问题
数据量少的时候操作数据,遍历线性比红黑书所消耗的资源少,且前期数据少 平衡⼆叉树保持平衡是需要消耗资源的,所以前期采用线性表,等到⼀定数之后变换到红黑树,等到8才变换也正是因为红黑树所消耗的空间比链表大的多,但是在链表长度为8时,此时概率为千分之1,并且此时由于链表长度加大,所用资源已经和红黑树相差不大,所以此时使用红黑树用少量空间换取大量时间
知识点13. hashmap的put和get的核心逻辑(JDK8以上版本)
get核心流程如下图,有注释
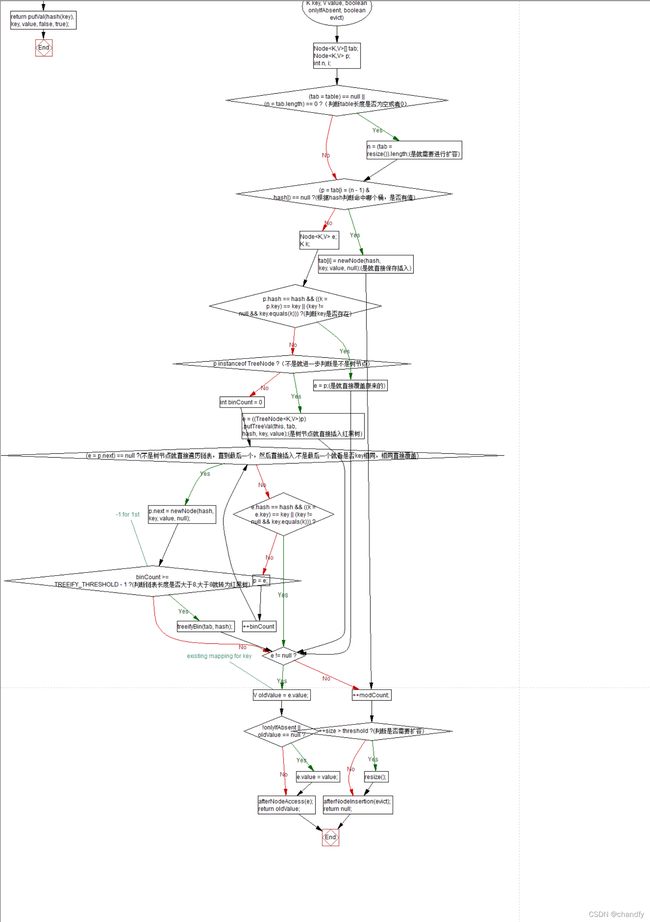
get核心流程如下图:

知识点14. ConcurrentHashMap为什么性能比hashtable高的原理
ConcurrentHashMap线程安全的Map, hashtable类基本上所有的方法都是采用synchronized进行线程安全控制高并发情况下效率就降低ConcurrentHashMap是采⽤了分段锁的思想提高性能,锁粒度更细化
知识点15. jdk1.7和jdk1.8里面ConcurrentHashMap实现的区别
JDK8之前,ConcurrentHashMap使⽤锁分段技术,将数据分成⼀段段存储,每个数据段配置⼀把锁,即segment类,这个类继承ReentrantLock来保证线程安全
技术点:Segment+HashEntry
JKD8的版本取消Segment这个分段锁数据结构,底层也是使⽤Node数组+链表+红⿊树,从而实现对每⼀段数据进行加锁,也减少了并发冲突的概率,CAS(读)+Synchronized(写)
技术点:Node+Cas+Synchronized
知识点16. 下ConcurrentHashMap的put的核心逻辑
1、key进行重哈希spread(key.hashCode())
2、对当前table进行无条件循环
3、如果没有初始化table,则⽤initTable进行初始化(懒加载模式)
4、如果没有hash冲突,则直接用cas插入新节点,成功后则直接判断是否需要扩容,然后结束
5、(fh = f.hash) == MOVED 如果是这个状态则是扩容操作,先进行扩容
6、存在hash冲突,利用synchronized (f) 加锁保证线程安全
7、如果是链表,则直接遍历插⼊,如果数量大于8,则需要转换成红黑树
8、如果是红⿊树则按照红黑树规则插⼊
9、最后是检查是否需要扩容addCount()