本文主要是B站阿雷边教边学的R语言学习笔记
https://www.bilibili.com/video/av6325276
其他参考资料:
- 小白学R—数据结构入门
https://www.jianshu.com/p/1111fa387993
- R语言入门2:数据结构-1
https://www.jianshu.com/p/cc79523afb1f
- R语言入门2:数据结构-2
https://www.jianshu.com/p/f9def072136f
- R语言入门2:数据结构-3
https://www.jianshu.com/p/9c51ad246059
- R语言入门3:数据类型
https://www.jianshu.com/p/27fe266a88a6
- R语言入门4:数据框元素的提取和作图 https://www.jianshu.com/p/365bf1bd4481
- R语言入门5:数据变形-Tidyr
https://www.jianshu.com/p/f58ccc1ea30b
- R语言入门6:数据处理之单表操作-Dplyr
https://www.jianshu.com/p/531b98d4eb93
- R语言入门7:数据处理之双表操作-Dplyr https://www.jianshu.com/p/a7af4f6e50c3
- ggplot绘图的艺术-1:数据准备
https://www.jianshu.com/p/81354e18f637
- ggplot绘图的艺术-2:ggplot2的绘图思想https://www.jianshu.com/p/a598b8034dc6
- ggplot绘图的艺术-3:映射:将数据变量对应到图形属性 https://www.jianshu.com/p/36a706e124db
- R语言-数据结构
https://www.jianshu.com/p/85f3f55bddb8
R语言第1期 数据类型

image.png

image.png

image.png
matrix(1:20, 2,10) #2行,10列数据
[,1] [,2] [,3] [,4] [,5] [,6] [,7] [,8] [,9] [,10]
[1,] 1 2 3 4 5 6 7 8 9 10
[2,] 11 12 13 14 15 16 17 18 19 20
matrix(1:20,4,5)
n1<-c("a", "b", "c", "d")
n2<-c("A", "B","C", "D", "E")
m1<-matrix(1:20,nrow=4,ncol=5,byrow=TRUE, dimnames=list(n1, n2))
m1
A B C D E
a 1 2 3 4 5
b 6 7 8 9 10
c 11 12 13 14 15
d 16 17 18 19 20
m1[2,4]
[1] 9

image.png
n1<-c("a", "b", "c", "d")
n2<-c("A", "B","C", "D", "E")
n3<-c("z1", "z2","z3")
N<-array(1:60, c(4,5,3),dimnames=list(n1, n2, n3))
N
, , z1
A B C D E
a 1 5 9 13 17
b 2 6 10 14 18
c 3 7 11 15 19
d 4 8 12 16 20
, , z2
A B C D E
a 21 25 29 33 37
b 22 26 30 34 38
c 23 27 31 35 39
d 24 28 32 36 40
, , z3
A B C D E
a 41 45 49 53 57
b 42 46 50 54 58
c 43 47 51 55 59
d 44 48 52 56 60
R语言第2期 数据框和第4期数据框的操作

image.png
age<-c(22,24,26,27,30)
gender<-c("male", "female"," male", "female","female")
score <-c(80,85,86,90,95)
CLA <-data.frame(age, gender, score)
CLA
age gender score
1 22 male 80
2 24 female 85
3 26 male 86
4 27 female 90
5 30 female 95
CLA$score
[1] 80 85 86 90 95
CLA["score"]
score
1 80
2 85
3 86
4 90
5 95

image.png
mtcars
mpg cyl disp hp drat wt qsec vs am gear carb
Mazda RX4 21.0 6 160.0 110 3.90 2.620 16.46 0 1 4 4
Mazda RX4 Wag 21.0 6 160.0 110 3.90 2.875 17.02 0 1 4 4
Datsun 710 22.8 4 108.0 93 3.85 2.320 18.61 1 1 4 1
Hornet 4 Drive 21.4 6 258.0 110 3.08 3.215 19.44 1 0 3 1
Hornet Sportabout 18.7 8 360.0 175 3.15 3.440 17.02 0 0 3 2
Valiant 18.1 6 225.0 105 2.76 3.460 20.22 1 0 3 1
Duster 360 14.3 8 360.0 245 3.21 3.570 15.84 0 0 3 4
Merc 240D 24.4 4 146.7 62 3.69 3.190 20.00 1 0 4 2
Merc 230 22.8 4 140.8 95 3.92 3.150 22.90 1 0 4 2
Merc 280 19.2 6 167.6 123 3.92 3.440 18.30 1 0 4 4
Merc 280C 17.8 6 167.6 123 3.92 3.440 18.90 1 0 4 4
Merc 450SE 16.4 8 275.8 180 3.07 4.070 17.40 0 0 3 3
Merc 450SL 17.3 8 275.8 180 3.07 3.730 17.60 0 0 3 3
Merc 450SLC 15.2 8 275.8 180 3.07 3.780 18.00 0 0 3 3
Cadillac Fleetwood 10.4 8 472.0 205 2.93 5.250 17.98 0 0 3 4
Lincoln Continental 10.4 8 460.0 215 3.00 5.424 17.82 0 0 3 4
Chrysler Imperial 14.7 8 440.0 230 3.23 5.345 17.42 0 0 3 4
Fiat 128 32.4 4 78.7 66 4.08 2.200 19.47 1 1 4 1
Honda Civic 30.4 4 75.7 52 4.93 1.615 18.52 1 1 4 2
Toyota Corolla 33.9 4 71.1 65 4.22 1.835 19.90 1 1 4 1
Toyota Corona 21.5 4 120.1 97 3.70 2.465 20.01 1 0 3 1
Dodge Challenger 15.5 8 318.0 150 2.76 3.520 16.87 0 0 3 2
AMC Javelin 15.2 8 304.0 150 3.15 3.435 17.30 0 0 3 2
Camaro Z28 13.3 8 350.0 245 3.73 3.840 15.41 0 0 3 4
Pontiac Firebird 19.2 8 400.0 175 3.08 3.845 17.05 0 0 3 2
Fiat X1-9 27.3 4 79.0 66 4.08 1.935 18.90 1 1 4 1
Porsche 914-2 26.0 4 120.3 91 4.43 2.140 16.70 0 1 5 2
Lotus Europa 30.4 4 95.1 113 3.77 1.513 16.90 1 1 5 2
Ford Pantera L 15.8 8 351.0 264 4.22 3.170 14.50 0 1 5 4
Ferrari Dino 19.7 6 145.0 175 3.62 2.770 15.50 0 1 5 6
Maserati Bora 15.0 8 301.0 335 3.54 3.570 14.60 0 1 5 8
Volvo 142E 21.4 4 121.0 109 4.11 2.780 18.60 1 1 4 2
df<-head(mtcars)
df1<-df[1:3]
df1
mpg cyl disp
Mazda RX4 21.0 6 160
Mazda RX4 Wag 21.0 6 160
Datsun 710 22.8 4 108
Hornet 4 Drive 21.4 6 258
Hornet Sportabout 18.7 8 360
Valiant 18.1 6 225
df1$mpg
[1] 21.0 21.0 22.8 21.4 18.7 18.1
df1$disp
[1] 160 160 108 258 360 225
attach(df1)
mpg
[1] 21.0 21.0 22.8 21.4 18.7 18.1
cyl
[1] 6 6 4 6 8 6
detach(df1)
with(df1, {
mpg+cyl+disp
})
[1] 187.0 187.0 134.8 285.4 386.7 249.1
df2<-within(df1,{
sum=mpg+cyl+disp
mean=(mpg+cyl+disp)/3
})
df2
mpg cyl disp mean sum
Mazda RX4 21.0 6 160 62.33333 187.0
Mazda RX4 Wag 21.0 6 160 62.33333 187.0
Datsun 710 22.8 4 108 44.93333 134.8
Hornet 4 Drive 21.4 6 258 95.13333 285.4
Hornet Sportabout 18.7 8 360 128.90000 386.7
Valiant 18.1 6 225 83.03333 249.1
df3<-transform (df1,sum=mpg+cyl+disp, mean=(mpg+cyl+disp)/3)
df3
mpg cyl disp mean sum
Mazda RX4 21.0 6 160 62.33333 187.0
Mazda RX4 Wag 21.0 6 160 62.33333 187.0
Datsun 710 22.8 4 108 44.93333 134.8
Hornet 4 Drive 21.4 6 258 95.13333 285.4
Hornet Sportabout 18.7 8 360 128.90000 386.7
Valiant 18.1 6 225 83.03333 249.1
library(dplyr)
df4<-mutate(df1,sum=mpg+cyl+disp, mean=(mpg+cyl+disp)/3)
df4
mpg cyl disp sum mean
1 21.0 6 160 187.0 62.33333
2 21.0 6 160 187.0 62.33333
3 22.8 4 108 134.8 44.93333
4 21.4 6 258 285.4 95.13333
5 18.7 8 360 386.7 128.90000
6 18.1 6 225 249.1 83.03333

image.png
age<-c(22,24,26,27,30)
gender<-c("male", "female"," male", "female","female")
score <-c(80,85,86,90,95)
v1<-c(1,2,3,4,5)
m1<-matrix(1:20,nrow=4)
df1<-data.frame(age,gender)
list1<-list(v1, m1, df1)
list1
[[1]]
[1] 1 2 3 4 5
[[2]]
[,1] [,2] [,3] [,4] [,5]
[1,] 1 5 9 13 17
[2,] 2 6 10 14 18
[3,] 3 7 11 15 19
[4,] 4 8 12 16 20
[[3]]
age gender
1 22 male
2 24 female
3 26 male
4 27 female
5 30 female
list1[[2]][2,2]
[1] 6
list1 $v1
NULL
list1<-list(v=v1, m=m1, df=df1) #需要先定义元素
list1$v
[1] 1 2 3 4 5
list1$m
[,1] [,2] [,3] [,4] [,5]
[1,] 1 5 9 13 17
[2,] 2 6 10 14 18
[3,] 3 7 11 15 19
[4,] 4 8 12 16 20
R语言第3期 数据导入和导出

image.png
getwd() #得到当前文件存放的工作目录
setwd() #重新设置当前文件存放的工作目录
read.csv("数据文件所在工作目录") #导入数据文件
write.csv(数据集, "定义一个文件名称") #导出数据文件
R语言第5期—排序和选取子集
在R中,和排序相关的函数主要有三个:sort(),rank(),order()。
- sort(x)是对向量x进行排序,返回值排序后的数值向量。
- 而order()的返回值是对应“排名”的元素所在向量中的位置。
- rank()是求秩的函数,它的返回值是这个向量中对应元素的“排名”。
下面以一小段R代码来举例说明:
sort(x)
[1] 32 67 74 85 93 97 99 100
order(x)
[1] 5 8 4 3 2 1 7 6
rank(x)
[1] 6 5 4 3 1 8 7 2
mtcars
mpg cyl disp hp drat wt qsec vs am gear carb
Mazda RX4 21.0 6 160.0 110 3.90 2.620 16.46 0 1 4 4
Mazda RX4 Wag 21.0 6 160.0 110 3.90 2.875 17.02 0 1 4 4
Datsun 710 22.8 4 108.0 93 3.85 2.320 18.61 1 1 4 1
Hornet 4 Drive 21.4 6 258.0 110 3.08 3.215 19.44 1 0 3 1
Hornet Sportabout 18.7 8 360.0 175 3.15 3.440 17.02 0 0 3 2
Valiant 18.1 6 225.0 105 2.76 3.460 20.22 1 0 3 1
Duster 360 14.3 8 360.0 245 3.21 3.570 15.84 0 0 3 4
Merc 240D 24.4 4 146.7 62 3.69 3.190 20.00 1 0 4 2
Merc 230 22.8 4 140.8 95 3.92 3.150 22.90 1 0 4 2
Merc 280 19.2 6 167.6 123 3.92 3.440 18.30 1 0 4 4
Merc 280C 17.8 6 167.6 123 3.92 3.440 18.90 1 0 4 4
Merc 450SE 16.4 8 275.8 180 3.07 4.070 17.40 0 0 3 3
Merc 450SL 17.3 8 275.8 180 3.07 3.730 17.60 0 0 3 3
Merc 450SLC 15.2 8 275.8 180 3.07 3.780 18.00 0 0 3 3
Cadillac Fleetwood 10.4 8 472.0 205 2.93 5.250 17.98 0 0 3 4
Lincoln Continental 10.4 8 460.0 215 3.00 5.424 17.82 0 0 3 4
Chrysler Imperial 14.7 8 440.0 230 3.23 5.345 17.42 0 0 3 4
Fiat 128 32.4 4 78.7 66 4.08 2.200 19.47 1 1 4 1
Honda Civic 30.4 4 75.7 52 4.93 1.615 18.52 1 1 4 2
Toyota Corolla 33.9 4 71.1 65 4.22 1.835 19.90 1 1 4 1
Toyota Corona 21.5 4 120.1 97 3.70 2.465 20.01 1 0 3 1
Dodge Challenger 15.5 8 318.0 150 2.76 3.520 16.87 0 0 3 2
AMC Javelin 15.2 8 304.0 150 3.15 3.435 17.30 0 0 3 2
Camaro Z28 13.3 8 350.0 245 3.73 3.840 15.41 0 0 3 4
Pontiac Firebird 19.2 8 400.0 175 3.08 3.845 17.05 0 0 3 2
Fiat X1-9 27.3 4 79.0 66 4.08 1.935 18.90 1 1 4 1
Porsche 914-2 26.0 4 120.3 91 4.43 2.140 16.70 0 1 5 2
Lotus Europa 30.4 4 95.1 113 3.77 1.513 16.90 1 1 5 2
Ford Pantera L 15.8 8 351.0 264 4.22 3.170 14.50 0 1 5 4
Ferrari Dino 19.7 6 145.0 175 3.62 2.770 15.50 0 1 5 6
Maserati Bora 15.0 8 301.0 335 3.54 3.570 14.60 0 1 5 8
Volvo 142E 21.4 4 121.0 109 4.11 2.780 18.60 1 1 4 2
mtcars[order(mtcars$mpg, mtcars$cyl), ]
mpg cyl disp hp drat wt qsec vs am gear carb
Cadillac Fleetwood 10.4 8 472.0 205 2.93 5.250 17.98 0 0 3 4
Lincoln Continental 10.4 8 460.0 215 3.00 5.424 17.82 0 0 3 4
Camaro Z28 13.3 8 350.0 245 3.73 3.840 15.41 0 0 3 4
Duster 360 14.3 8 360.0 245 3.21 3.570 15.84 0 0 3 4
Chrysler Imperial 14.7 8 440.0 230 3.23 5.345 17.42 0 0 3 4
Maserati Bora 15.0 8 301.0 335 3.54 3.570 14.60 0 1 5 8
Merc 450SLC 15.2 8 275.8 180 3.07 3.780 18.00 0 0 3 3
AMC Javelin 15.2 8 304.0 150 3.15 3.435 17.30 0 0 3 2
Dodge Challenger 15.5 8 318.0 150 2.76 3.520 16.87 0 0 3 2
Ford Pantera L 15.8 8 351.0 264 4.22 3.170 14.50 0 1 5 4
Merc 450SE 16.4 8 275.8 180 3.07 4.070 17.40 0 0 3 3
Merc 450SL 17.3 8 275.8 180 3.07 3.730 17.60 0 0 3 3
Merc 280C 17.8 6 167.6 123 3.92 3.440 18.90 1 0 4 4
Valiant 18.1 6 225.0 105 2.76 3.460 20.22 1 0 3 1
Hornet Sportabout 18.7 8 360.0 175 3.15 3.440 17.02 0 0 3 2
Merc 280 19.2 6 167.6 123 3.92 3.440 18.30 1 0 4 4
Pontiac Firebird 19.2 8 400.0 175 3.08 3.845 17.05 0 0 3 2
Ferrari Dino 19.7 6 145.0 175 3.62 2.770 15.50 0 1 5 6
Mazda RX4 21.0 6 160.0 110 3.90 2.620 16.46 0 1 4 4
Mazda RX4 Wag 21.0 6 160.0 110 3.90 2.875 17.02 0 1 4 4
Volvo 142E 21.4 4 121.0 109 4.11 2.780 18.60 1 1 4 2
Hornet 4 Drive 21.4 6 258.0 110 3.08 3.215 19.44 1 0 3 1
Toyota Corona 21.5 4 120.1 97 3.70 2.465 20.01 1 0 3 1
Datsun 710 22.8 4 108.0 93 3.85 2.320 18.61 1 1 4 1
Merc 230 22.8 4 140.8 95 3.92 3.150 22.90 1 0 4 2
Merc 240D 24.4 4 146.7 62 3.69 3.190 20.00 1 0 4 2
Porsche 914-2 26.0 4 120.3 91 4.43 2.140 16.70 0 1 5 2
Fiat X1-9 27.3 4 79.0 66 4.08 1.935 18.90 1 1 4 1
Honda Civic 30.4 4 75.7 52 4.93 1.615 18.52 1 1 4 2
Lotus Europa 30.4 4 95.1 113 3.77 1.513 16.90 1 1 5 2
Fiat 128 32.4 4 78.7 66 4.08 2.200 19.47 1 1 4 1
Toyota Corolla 33.9 4 71.1 65 4.22 1.835 19.90 1 1 4 1
library(dplyr)
arrange(mtcars, mpg, cyl)
mpg cyl disp hp drat wt qsec vs am gear carb
1 10.4 8 472.0 205 2.93 5.250 17.98 0 0 3 4
2 10.4 8 460.0 215 3.00 5.424 17.82 0 0 3 4
3 13.3 8 350.0 245 3.73 3.840 15.41 0 0 3 4
4 14.3 8 360.0 245 3.21 3.570 15.84 0 0 3 4
5 14.7 8 440.0 230 3.23 5.345 17.42 0 0 3 4
6 15.0 8 301.0 335 3.54 3.570 14.60 0 1 5 8
7 15.2 8 275.8 180 3.07 3.780 18.00 0 0 3 3
8 15.2 8 304.0 150 3.15 3.435 17.30 0 0 3 2
9 15.5 8 318.0 150 2.76 3.520 16.87 0 0 3 2
10 15.8 8 351.0 264 4.22 3.170 14.50 0 1 5 4
11 16.4 8 275.8 180 3.07 4.070 17.40 0 0 3 3
12 17.3 8 275.8 180 3.07 3.730 17.60 0 0 3 3
13 17.8 6 167.6 123 3.92 3.440 18.90 1 0 4 4
14 18.1 6 225.0 105 2.76 3.460 20.22 1 0 3 1
15 18.7 8 360.0 175 3.15 3.440 17.02 0 0 3 2
16 19.2 6 167.6 123 3.92 3.440 18.30 1 0 4 4
17 19.2 8 400.0 175 3.08 3.845 17.05 0 0 3 2
18 19.7 6 145.0 175 3.62 2.770 15.50 0 1 5 6
19 21.0 6 160.0 110 3.90 2.620 16.46 0 1 4 4
20 21.0 6 160.0 110 3.90 2.875 17.02 0 1 4 4
21 21.4 4 121.0 109 4.11 2.780 18.60 1 1 4 2
22 21.4 6 258.0 110 3.08 3.215 19.44 1 0 3 1
23 21.5 4 120.1 97 3.70 2.465 20.01 1 0 3 1
24 22.8 4 108.0 93 3.85 2.320 18.61 1 1 4 1
25 22.8 4 140.8 95 3.92 3.150 22.90 1 0 4 2
26 24.4 4 146.7 62 3.69 3.190 20.00 1 0 4 2
27 26.0 4 120.3 91 4.43 2.140 16.70 0 1 5 2
28 27.3 4 79.0 66 4.08 1.935 18.90 1 1 4 1
29 30.4 4 75.7 52 4.93 1.615 18.52 1 1 4 2
30 30.4 4 95.1 113 3.77 1.513 16.90 1 1 5 2
31 32.4 4 78.7 66 4.08 2.200 19.47 1 1 4 1
32 33.9 4 71.1 65 4.22 1.835 19.90 1 1 4 1
#筛选出mpg>=20, 并且vs等于0的数据
subset(mtcars, mpg>=20 & vs==0, 1:3) #前三列
# ==表示判断,严格等于
# =表示赋值
# "|" 表示或, 满足一个条件就可以
mpg cyl disp
Mazda RX4 21 6 160.0
Mazda RX4 Wag 21 6 160.0
Porsche 914-2 26 4 120.3
filter(mtcars, mpg>=20,vs==0 )
mpg cyl disp hp drat wt qsec vs am gear carb
1 21 6 160.0 110 3.90 2.620 16.46 0 1 4 4
2 21 6 160.0 110 3.90 2.875 17.02 0 1 4 4
3 26 4 120.3 91 4.43 2.140 16.70 0 1 5 2
filter(mtcars, mpg>=20,carb|4)
mpg cyl disp hp drat wt qsec vs am gear carb
1 21.0 6 160.0 110 3.90 2.620 16.46 0 1 4 4
2 21.0 6 160.0 110 3.90 2.875 17.02 0 1 4 4
3 22.8 4 108.0 93 3.85 2.320 18.61 1 1 4 1
4 21.4 6 258.0 110 3.08 3.215 19.44 1 0 3 1
5 24.4 4 146.7 62 3.69 3.190 20.00 1 0 4 2
6 22.8 4 140.8 95 3.92 3.150 22.90 1 0 4 2
7 32.4 4 78.7 66 4.08 2.200 19.47 1 1 4 1
8 30.4 4 75.7 52 4.93 1.615 18.52 1 1 4 2
9 33.9 4 71.1 65 4.22 1.835 19.90 1 1 4 1
10 21.5 4 120.1 97 3.70 2.465 20.01 1 0 3 1
11 27.3 4 79.0 66 4.08 1.935 18.90 1 1 4 1
12 26.0 4 120.3 91 4.43 2.140 16.70 0 1 5 2
13 30.4 4 95.1 113 3.77 1.513 16.90 1 1 5 2
14 21.4 4 121.0 109 4.11 2.780 18.60 1 1 4 2
重命名

image.png
#重命名--names函数
names(data)[1]<- "mmm"
data1<- data[1:3,]
data1
mmm cyl disp hp drat wt qsec vs am gear carb
Mazda RX4 21.0 6 160 110 3.90 2.620 16.46 0 1 4 4
Mazda RX4 Wag 21.0 6 160 110 3.90 2.875 17.02 0 1 4 4
Datsun 710 22.8 4 108 93 3.85 2.320 18.61 1 1 4 1
# 重命名--renames函数
library (reshape)
data2<- rename(data, c(mmm="newmpg"))[1:3,]
data2
newmpg cyl disp hp drat wt qsec vs am gear carb
Mazda RX4 21.0 6 160 110 3.90 2.620 16.46 0 1 4 4
Mazda RX4 Wag 21.0 6 160 110 3.90 2.875 17.02 0 1 4 4
Datsun 710 22.8 4 108 93 3.85 2.320 18.61 1 1 4 1
R 语言 第6期 数据组合

image.png
v1<-c(1,2,3,4,5)
v2<-c("g")
paste(v1,v2, sep="" )
[1] "1g" "2g" "3g" "4g" "5g"
df1<-mtcars[1:10,]
df2<-mtcars[11:20,]
df<-rbind(df1, df2)
head(df)
mpg cyl disp hp drat wt qsec vs am gear carb
Mazda RX4 21.0 6 160 110 3.90 2.620 16.46 0 1 4 4
Mazda RX4 Wag 21.0 6 160 110 3.90 2.875 17.02 0 1 4 4
Datsun 710 22.8 4 108 93 3.85 2.320 18.61 1 1 4 1
Hornet 4 Drive 21.4 6 258 110 3.08 3.215 19.44 1 0 3 1
Hornet Sportabout 18.7 8 360 175 3.15 3.440 17.02 0 0 3 2
Valiant 18.1 6 225 105 2.76 3.460 20.22 1 0 3 1
df3<- mtcars[, 1:3]
df4<- mtcars[,4:6]
dfnew<- cbind(df3, df4)
head(dfnew)
mpg cyl disp hp drat wt
Mazda RX4 21.0 6 160 110 3.90 2.620
Mazda RX4 Wag 21.0 6 160 110 3.90 2.875
Datsun 710 22.8 4 108 93 3.85 2.320
Hornet 4 Drive 21.4 6 258 110 3.08 3.215
Hornet Sportabout 18.7 8 360 175 3.15 3.440
Valiant 18.1 6 225 105 2.76 3.460
merge函数参数的说明:
参考链接:https://blog.csdn.net/u010652755/article/details/72982227
R中的merge函数类似于Excel中的Vlookup,可以实现对两个数据表进行匹配和拼接的功能。与Excel不同之处在于merge函数有4种匹配拼接模式,分别为inner,left,right和outer模式。 其中inner为默认的匹配模式,可与sql语言中的join语句用法。
merge 连接两个数据,官方参考文档语法
merge(x, y, by = intersect(names(x), names(y)),
by.x = by, by.y = by, all = FALSE, all.x = all, all.y = all,
sort = TRUE, suffixes = c(".x",".y"),
incomparables = NULL, ...)
- x,y 要合并的两个数据集
- by,用于连接两个数据集的列,intersect(a,b)值向量a,b的交集,names(x)指提取数据集x的列名
- by = intersect(names(x), names(y)) 是获取数据集x,y的列名后,提取其公共列名,作为两个数据集的连接列, 当有多个公共列时,需用下标指出公共列,如names(x)[1],指定x数据集的第1列作为公共列
也可以直接写为 by = ‘公共列名’ ,前提是两个数据集中都有该列名,并且大小写完全一致,R语言区分大小写 - by.x,by.y:指定依据哪些行合并数据框,默认值为相同列名的列
- all,all.x,all.y:指定x和y的行是否应该全在输出文件
- sort:by指定的列(即公共列)是否要排序
- suffixes:指定除by外相同列名的后缀
-
incomparables:指定by中哪些单元不进行合并
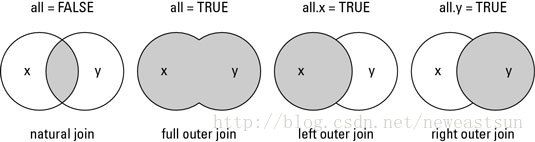 image.png
image.png
创建数据集w
name <- c('A','B','A','A','C','D')
school <- c('s1','s2','s1','s1','s1','s3')
class <- c(10, 5, 4, 11, 1, 8)
English <- c(85, 50, 90 ,90, 12, 96)
w <- data.frame(name, school, class, English)
w
name school class English
A s1 10 85
B s2 5 50
A s1 4 90
A s1 11 90
C s1 1 12
D s3 8 96
创建数据集q
name <- c('A','B','C','F')
school <- c('s3','s2','s1','s2')
class <- c(5, 5, 1,3)
maths <- c(80,89,55,90)
English <- c(88, 89, 32, 89)
q <- data.frame(name, school, class, maths, English)
q
# 查看两个数据表的维度
dim(w)
[1] 6 4
dim(q)
[1] 4 5
# 查看两个数据集的列名称
names(w);names(q);
[1] "name" "school" "class" "English"
[1] "name" "school" "class" "maths" "English"
# 可以看出两个数据集有公共列
inner 模式匹配,只显示两个数据集公共列中均有的行
# 有多个公共列时,需指出使用哪一列作为连接列
merge(w,q,by = intersect(names(w)[1],names(q)[1]))
name school.x class.x English.x school.y class.y maths English.y
1 A s1 10 85 s3 5 80 88
2 A s1 4 90 s3 5 80 88
3 A s1 11 90 s3 5 80 88
4 B s2 5 50 s2 5 89 89
5 C s1 1 12 s1 1 55 32
# 当两个数据集连接列名称同时,直接用 by.x, by.y 指定连接列
name school.x class.x English.x school.y class.y maths English.y
1 A s1 10 85 s3 5 80 88
2 A s1 4 90 s3 5 80 88
3 A s1 11 90 s3 5 80 88
4 B s2 5 50 s2 5 89 89
5 C s1 1 12 s1 1 55 32
# 当两个数据集连接列名称同时,直接用 by.x, by.y 指定连接列
merge(w,q,by.x = 'name', by.y = 'name')
# 当两个数据集均有连接列时,直接指定连接列的名称
merge(w,q,by = 'name')
name school.x class.x English.x school.y class.y maths English.y
1 A s1 10 85 s3 5 80 88
2 A s1 4 90 s3 5 80 88
3 A s1 11 90 s3 5 80 88
4 B s2 5 50 s2 5 89 89
5 C s1 1 12 s1 1 55 32
- 连接列置于第1列; 有多个公共列,在公共列后加上x,y表示数据来源,.x表示来源于数据集w,.y表示来源于数据集q
- 数据集中w中的 name = ‘D’ 不显示,数据集中q中的 name = ‘F’ 不显示,只显示公有的name行,并且用q数据集A行匹配了w数据集所有的A行
outer 模式,将两张表的数据汇总,表中原来没有的数据置为空
merge(w, q, all=TRUE, sort=TRUE)
name school class English maths
1 A s1 4 90 NA
2 A s1 10 85 NA
3 A s1 11 90 NA
4 A s3 5 88 80
5 B s2 5 50 NA
6 B s2 5 89 89
7 C s1 1 12 NA
8 C s1 1 32 55
9 D s3 8 96 NA
10 F s2 3 89 90
- all = TRUE 表示选取w, q 数据集的所有行,sort = TRUE,表示按 by 列进行排序,默认升序
left 匹配模式
merge(w ,q ,all.x=TRUE,sort=TRUE) # 建议使用 指定了连接列 的情况
# 多个公共列,未指定连接列
# 左连接,设置 all.x = TRUE,结果只显示数据w的列及w在q数据集中没有的列
name school class English maths
1 A s1 4 90 NA
2 A s1 10 85 NA
3 A s1 11 90 NA
4 B s2 5 50 NA
5 C s1 1 12 NA
6 D s3 8 96 NA
merge(w, q, by = 'name',all.x = TRUE, sort = TRUE) # 指定连接列
# 多个公共列,指定连接列
# 左连接,设置 all.x = TRUE,结果只显示w所有name值
name school.x class.x English.x school.y class.y maths English.y
1 A s1 10 85 s3 5 80 88
2 A s1 4 90 s3 5 80 88
3 A s1 11 90 s3 5 80 88
4 B s2 5 50 s2 5 89 89
5 C s1 1 12 s1 1 55 32
6 D s3 8 96 NA NA NA
right 匹配模式
merge(w ,q ,by = 'name', all.y=TRUE,sort=TRUE)
# 多个公共列,指定连接列
# 左连接,设置 all.y = TRUE,结果只显示q所有name值的记录
name school.x class.x English.x school.y class.y maths English.y
1 A s1 10 85 s3 5 80 88
2 A s1 4 90 s3 5 80 88
3 A s1 11 90 s3 5 80 88
4 B s2 5 50 s2 5 89 89
5 C s1 1 12 s1 1 55 32
6 F NA NA s2 3 90 89
R语言 第7期 分组数据处理apply函数应用

image.png
m1
[,1] [,2] [,3] [,4] [,5]
[1,] 1 5 9 13 17
[2,] 2 6 10 14 18
[3,] 3 7 11 15 19
[4,] 4 8 12 16 20
apply(m1, MARGIN = 1, sum)
[1] 45 50 55 60
apply(m1, MARGIN = 2, sum)
[1] 10 26 42 58 74
f1<-function(x){x*100}
apply(m1, MARGIN=1, f1)
[,1] [,2] [,3] [,4]
[1,] 100 200 300 400
[2,] 500 600 700 800
[3,] 900 1000 1100 1200
[4,] 1300 1400 1500 1600
[5,] 1700 1800 1900 2000
求出a1各个维度的和
apply(a1, 1, sum)
x1 x2
144 156
apply(a1, 2, sum)
y1 y2 y3
84 100 116
apply(a1, 3, sum)
z1 z2 z3 z4
21 57 93 129
apply(a1, 4, sum)
Error in if (d2 == 0L) { : missing value where TRUE/FALSE needed

image.png
lapply函数

image.png
l1<- list (v<-c(1:10), m<-matrix(1:20,4))
l1
[[1]]
[1] 1 2 3 4 5 6 7 8 9 10
[[2]]
[,1] [,2] [,3] [,4] [,5]
[1,] 1 5 9 13 17
[2,] 2 6 10 14 18
[3,] 3 7 11 15 19
[4,] 4 8 12 16 20
lapply(l1, sum)
[[1]]
[1] 55
[[2]]
[1] 210
#输出结果为列表
sapply函数

image.png
sapply(l1, sum)
[1] 55 210
# 输出结果为向量

image.png
R语言 第8期 分组数据处理

image.png
age<-c(18,18,28,28,28,38,38,38,38)
sex<-c("female", "male", "male","male", "female", "female","male","female","male")
income<-c(2000, 3000,4200,5000,5300,5700,6000,7000,9000)
education<-c("高中", "高中", "大学" , "大学", "大学","硕士", "硕士", "大学","大学")
df1<-data.frame(age, sex, education, income)
df1
age sex education income
1 18 female 高中 2000
2 18 male 高中 3000
3 28 male 大学 4200
4 28 male 大学 5000
5 28 female 大学 5300
6 38 female 硕士 5700
7 38 male 硕士 6000
8 38 female 大学 7000
9 38 male 大学 9000
# 男女各自的收入总和
tapply(df1$income, df1$sex, sum)
female male
20000 27200
# 不同学历人群的平均收入
大学 高中 硕士
6100 2500 5850
tapply(df1$income, df1$education, mean)
#男女不同学历人群的平均收入
tapply(df1$income, list(df1$sex,df1$education), mean)
大学 高中 硕士
female 6150.000 2000 5700
male 6066.667 3000 6000
by(df1$income, df1$sex, sum)
df1$sex: female
[1] 20000
---------------------------------------------
df1$sex: male
by(df1$income, list(df1$sex,df1$education), mean)
: female
: 大学
[1] 6150
---------------------------------------------
: male
: 大学
[1] 6066.667
---------------------------------------------
: female
: 高中
[1] 2000
---------------------------------------------
: male
: 高中
[1] 3000
---------------------------------------------
: female
: 硕士
[1] 5700
---------------------------------------------
: male
: 硕士
[1] 6000
aggregate 函数
# 男女不同学历人群的平均收入
aggregate(income~sex+education,df1,mean)
sex education income
1 female 大学 6150.000
2 male 大学 6066.667
3 female 高中 2000.000
4 male 高中 3000.000
5 female 硕士 5700.000
6 male 硕士 6000.000
aggregate(income~education+sex,df1,mean)
education sex income
1 大学 female 6150.000
2 高中 female 2000.000
3 硕士 female 5700.000
4 大学 male 6066.667
5 高中 male 3000.000
6 硕士 male 6000.000
R语言第9期 缺失值处理和数据转换

image.png

image.png
R语言清除当前环境所有变量
使用 rm 函数能够删除当前环境中不需要的变量,假设有一个变量 x,我们不再需要它,那么可以使用
rm(x) rm("x")
假设我们有一个 character vector,需要将其中名称的变量都删除,那么可以使用
rm(list=c("x", "y", "z"))
极端的情况可以使用 ls() 或 objects() 函数返回当前环境中所有变量名称的 character vector。于是就有
rm(list=ls())
即删除所有当前环境变量。这个技巧可以用在代码开始用来防止意外的命名冲突。
2