参考:
① Tensorflow的可视化工具Tensorboard的初步使用
Link: https://blog.csdn.net/sinat_33761963/article/details/62433234?utm_source=copy
Tensorboard 可视化
可以记录的数据类型
(1) scalar
(2) Graph
(3) Distribution
...
可视化的过程
(1) 建立graph
(2) 确定在哪些节点放置summary operations记录信息
这里的summary操作也是operations
tf.summary.scalar 用来记录标量
tf.summary.distributation 用来记录数据分布图
tf.summary.image 用来记录图像数据
(3)我们需要的summary可能很多,这里的summary作为operations自然需要去run, 但是这些operations并没有被其他的operation 所依赖, 所以每个operation需要手动的去run, 为了方便,使用了tf.summary.merge_all()来将所有的summary节点合并成为一个节点, 只要运行这个节点,就能获得之前设置的summary data。
(4) 使用tf.summary.FileWriter将运行后的数据全部的写入到磁盘中。
(5) tensorboard --logdir=xxx
Code
# -*- coding: utf-8 -*-
import tensorflow as tf
from tensorflow.examples.tutorials.mnist import input_data
max_step = 1000
learning_rate = 0.001
dropout = 0.9
data_dir = "/tmp/mnist"
# log_dir下将会分为两个目录, train, test,分别存放了train, test的summary
log_dir = "/tmp/tensorflow"
mnist = input_data.read_data_sets(data_dir, one_hot=True)
config = tf.ConfigProto()
config.gpu_options.allow_growth = True
session = tf.Session(config=config)
with tf.name_scope("input"):
x = tf.placeholder(tf.float32, [None, 784], name="x-input")
y_ = tf.placeholder(tf.float32, [None, 10], name="y-input")
with tf.name_scope("input_shape"):
image_shape_input = tf.reshape(x, [-1, 28, 28, 1])
tf.summary.image("input", image_shape_input, 10) # 命名,数据, 显示10张
# 初始化参数
def weight_variable(shape):
initial = tf.truncated_normal(shape, stddev=0.1)
return tf.Variable(initial)
def bias_variable(shape):
initial = tf.constant(0.1, shape=shape)
return tf.Variable(initial)
def variable_summaries(var):
with tf.name_scope("summaries"):
mean = tf.reduce_mean(var)
tf.summary.scalar("mean", mean)
with tf.name_scope("stddev"):
stddev = tf.sqrt(tf.reduce_mean(tf.square(var - mean)))
tf.summary.scalar("stddev", stddev)
tf.summary.scalar("max", tf.reduce_max(var))
tf.summary.scalar("min", tf.reduce_min(var))
tf.summary.histogram("histogram", var)
def nn_layer(input_tensor, input_dim, output_dim, layer_name, act=tf.nn.relu):
with tf.name_scope(layer_name):
with tf.name_scope("weights"):
weights = weight_variable([input_dim, output_dim])
variable_summaries(weights)
with tf.name_scope("bias"):
biases = bias_variable([output_dim, ])
variable_summaries(biases)
with tf.name_scope("linear_compute"):
preactivate = tf.matmul(input_tensor, weights) + biases
tf.summary.histogram("linear", preactivate)
activations = act(preactivate, name="activation")
tf.summary.histogram("activations", activations)
return activations
hidden1 = nn_layer(x, 784, 500, "layer_1")
with tf.name_scope("dropout"):
keep_prob = tf.placeholder(tf.float32) # 这里使用了一个placeholder, 可以使用variable, assign代替
tf.summary.scalar("dropout_keep_probability", keep_prob)
dropped = tf.nn.dropout(hidden1, keep_prob)
# predict
y = nn_layer(dropped, 500, 10, "layer_2", act=tf.identity)
with tf.name_scope("loss"):
diff = tf.nn.softmax_cross_entropy_with_logits(labels=y_, logits=y)
with tf.name_scope("total"):
cross_entropy = tf.reduce_mean(diff)
tf.summary.scalar("loss", cross_entropy)
with tf.name_scope("train"):
train_step = tf.train.AdamOptimizer(learning_rate).minimize(cross_entropy)
with tf.name_scope("accuracy"):
with tf.name_scope("correct_pridiction"):
correct_prediction = tf.equal(tf.argmax(y, 1), tf.argmax(y_, 1))
with tf.name_scope("accuracy"):
accuracy = tf.reduce_mean(tf.cast(correct_prediction, tf.float32))
tf.summary.scalar("accuracy", accuracy)
merged = tf.summary.merge_all()
train_writer = tf.summary.FileWriter(log_dir+"/train", session.graph)
test_writer = tf.summary.FileWriter(log_dir+"/test")
session.run(tf.global_variables_initializer())
def feed_dict(train):
if train:
xs, ys = mnist.train.next_batch(1000)
k = dropout
else:
xs, ys = mnist.test.images, mnist.test.labels
k = 1.0
return {x: xs, y_: ys, keep_prob: k}
for i in range(max_step):
if i % 10 == 0:
summary, acc = session.run([merged, accuracy], feed_dict=feed_dict(False))
test_writer.add_summary(summary, i)
else:
if i % 100 == 99:
pass
else:
# summary的类型为string, session.run(tensor) 返回类型可能是由tensor决定的
summary, _ = session.run([merged, train_step], feed_dict=feed_dict(train=True))
train_writer.add_summary(summary, i)
summaries:
image
variable (mean(var)| stddev(var)| max(var)| min(var)| var)
preactive
activation
keep_prob
entropy_loss
accuracy
-
image
tf.summary.image('input', image_shape_input, 10)
由于在input_shape这个name_scope下, 所以图片的标识为input_shape/input/image/0,这里的image猜测是tensorflow自己加的。
 imageinput.png
imageinput.png accuracy
accuracy = tf.reduce_sum(tf.cast(correction_prediction, tf.float32)
tf.summary.scalar("accuracy", accuracy)
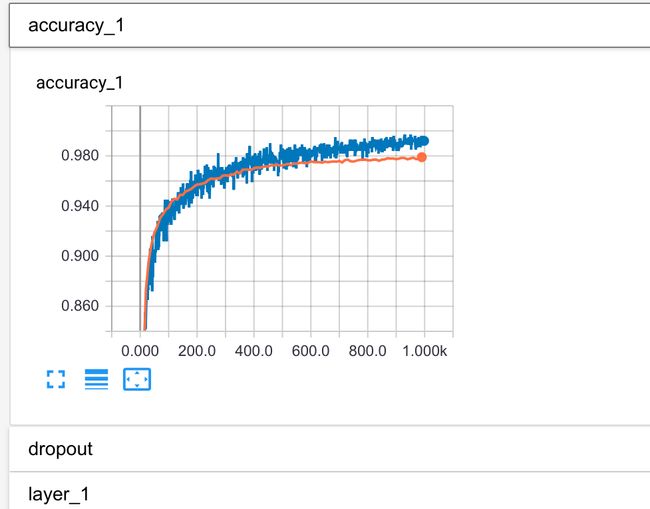
merged = tf.summary.merge_all()
summary, _ = session.run([merged, train_step], feed_dict=feed_dict(train=True))
merged集合所有的summary, 这里的summary类型为Image, scalar, histogram。session.run的返回值summary为 string, writer.add_summary相当于将这个string写入到文件中。summary格式很复杂, 因为其要包含很多的格式的数据。例如这里的summary包含了scalar, image, histogram。二进制数据与文本数据混合。
��
�input_shape/input/image/0"������"���PNG
�
���9����}�6����B�H�����o/����Q�4k�5O�nz���_�F���f�T��ӛ���Ȼ"u�w��8h\��qbM@�x�<�B�ݒ�9{�<������2tP� XH IEND�B`�
��
�input_shape/input/image/1"������"���PNG
�
��ˬO����a�4�r��4W{��?}�� �~ ��>�U�ҫ�[��[��u��s8R}�
���d��|o� �&^�J�d�g�� XY�˕i��� ̋���g1� �;��l�dhs� �����SrZ;�|�`2������p�P�����0��f]z��� �/����5Z��ċ�?��U~]�����y��mc;� IEND�B`�
��
�input_shape/input/image/2"������"���PNG
�
IHDR � Wf�H �&IDAT(�c`�H0��,�����+J���� �_�&�����������˷o?�0�I��E��pa&�����)(�������1��v��<���Y��?���� ��������ߝaF$%�er{/K>�rM3S�֟0'��E��ك��g�����`�*�d```�7����w�k�J�݇��������Y!�����0�H#x��?(#Ir�3!�L���c�������!�l���'��a``� i�c���)�To0000��c���Qc`���$U�o~�A��Er��D�f,�zV*�������_�^��˩�� "����$`� IEND�B`�
��
对于session.run(), 传入的参数为可以为Tensor, Operation(eg: train_step).
"""
def run(self, fetches, feed_dict=None, options=None, run_metadata=None):
The `fetches` argument may be a single graph element, or an arbitrarily
nested list, tuple, namedtuple, dict, or OrderedDict containing graph
elements at its leaves. A graph element can be one of the following types:
* An @{tf.Operation}.
The corresponding fetched value will be `None`.
* A @{tf.Tensor}.
The corresponding fetched value will be a numpy ndarray containing the
value of that tensor.
* A @{tf.SparseTensor}.
The corresponding fetched value will be a
@{tf.SparseTensorValue}
containing the value of that sparse tensor.
* A `get_tensor_handle` op. The corresponding fetched value will be a
numpy ndarray containing the handle of that tensor.
* A `string` which is the name of a tensor or operation in the graph.
"""
Tensor & Operation Name属性
with tf.name_scope("accuracy"):
with tf.name_scope("correct_pridiction"):
correct_prediction = tf.equal(tf.argmax(y, 1), tf.argmax(y_, 1))
with tf.name_scope("accuracy"):
accuracy = tf.reduce_mean(tf.cast(correct_prediction, tf.float32))
这里得到的两个变量accuracy, correct_prediction,分别为accuracy/accuracy/Mean:0和 accuracy/correct_pridiction/Equal:0, 那么这里Tensor的名称在name_scope的基础上再一步添加了Mean:0以及Equal:0, 表示了得到这个Tensor所进行的操作。
Tensorflow为何要使用这么多的name_scope, Operation来作为这里的Tensor的名称呢。为了方便debug么。
,