Transformer新秀:多块嵌入+多路径=MPViT

论文链接:https://arxiv.org/abs/2112.11010
推荐文章
- Python 程序员需要掌握的机器学习“四大名著”发布啦
- 浙大博士导师深度整理:Tensorflow 和 Pytorch 的笔记(包含经典项目实战)
- 值得收藏,这份机器学习算法资料着实太香
- 比 PyTorch 的官方文档还香啊,吃透PyTorch中文版来了
- 赶快收藏,PyTorch 常用代码段PDF合辑版来了
01、Abstract
本文对多尺度块嵌入与多路径结构进行探索,构建了MPViT(Multi-path Vision Transformer, MPViT)。结合重叠卷积块嵌入,MPViT可以同时对不同尺度、相同序列长度特征进行嵌入聚合。不同尺度的Token分别送入到不同的Transformer模块中(即并行架构)以构建同特征层级的粗粒度与细粒度特征的。

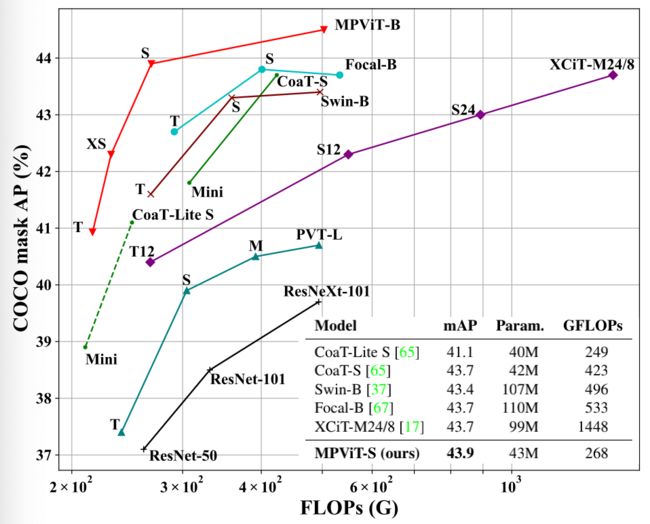
借助于灵活的多尺度特征表达,在不同任务(包含ImageNet分类、COCO目标检测以及ADE20K语义分割)下,不同大小的MPViT均取得了比已有Transformer更优的性能,可参考下图。
02、Method
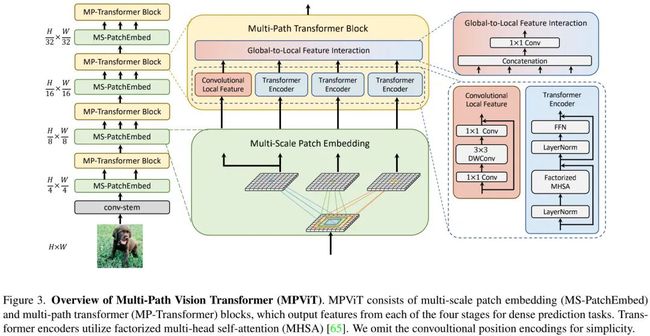
上图给出了本文所提MPViT整体架构示意图,它是一种多阶段架构,旨在提供一种用于稠密预测的强力骨干网络。
由于多阶架构具有高分辨率特征,故本文采用了CoaT中的自注意力机制以降低计算量;正如LeViT一文提到:卷积Stem模块具有更好的low-level表达能力,故我们采用了卷积Stem模块。此外,每个卷积后接BN与HardSwish激活函数。而Stage2-5部分则由本文所提多尺度块嵌入与多路径Transformer构建。
Multi-scale Patch Embedding
本文设计了一种多尺度块嵌入层以便于在同特征维度探索细粒度和粗粒度特征。具体来说,给定来自前一阶段的2D输出特征,我们采用将输入映射为新的token特征,其尺寸计算如下:

卷积块嵌入使得我们可以通过改变stride与padding调整序列长度,即不同块尺寸可以具有相同尺寸的输出。因此,我们构建了不同核尺寸的并行卷积块嵌入层,如序列长度相同但块尺寸可以为。
由于堆叠同尺寸卷积可以提升感受野且具有更少的参数量,我们采用两个卷积构建感受野,采用三个卷积构建感受野。通过上述处理,我们可以得到特征。
由于MPViT的多路径结构,它具有更多的嵌入层,我们采用深度分离卷积降低参数量与计算量。最终,不同尺寸的词嵌入特征将分别送入到不同的Transformer模块中。
Global-to-Local Feature Interaction
为进一步对多路径特征进行聚合,我们设计了一种新的特征聚合模块。可表示如下:
![]()
03、Experiments

上表给出ImageNet分类任务上不同方案的性能对比,可以看到:
-在同等参数量与计算复杂度约束下,MPViT取得了比有ViT架构更优的性能;
-MPViT-XS与Small分别比CoaT-Lite Mini与Small性能高2.0%、1.1%;
-MPViT-Small具有更大网络PVT-L、DeiT-B/16、XCiT-M24/16更优的性能;
-MPViT-B以74M参数量取得了84.3%的指标,超过了近期同等参数的Swin-Base以及Focal-Base。

上表给出了COCO检测任务上不同方案的性能对比,从中可以看到:
-相比同尺寸的其他ViT方案,MPViT均取得了更优的性能;
-基于RetinaNet,MPViT-S取得了47.6%的指标,超越了Swin-T与Focal-T;
-基于Mask R-CNN,MPViT-XS与MPViT-S优于同尺寸的CoaT-Lite Mini与Small;值得一提的是,MPViT-S取得了比XCiT-M24/8和Focal-B更高的指标,同时具有更少的FLOPs。

上图给出了ADE20K分割任务上的性能对比,从中可以看到:
-MPViT优于其他同尺寸的ViT方案;
-MPViT-S以48.3%的指标大幅超越了Swin-T、Focal-T以及XCiT-S12/16;
-MPViT-B以50.3%的指标超越了近期SOTA方案Focal-B。
技术交流
目前已开通了技术交流群,群友已超过1000人,添加时最好的备注方式为:来源+兴趣方向,方便找到志同道合的朋友
- 方式①、发送如下图片至微信,长按识别,后台回复:加群;
- 方式②、微信搜索公众号:机器学习社区,后台回复:加群;
- 方式③、可以直接加微信号:mlc2060。加的时候备注一下:研究方向 +学校/公司+CSDN,即可。然后就可以拉你进群了。
