Tensorflow1.15实现Transformer(一):使用self-attention来实现文本分类
要学会一个算法,最好的办法还是自己复现一遍
这里也是对自己学习的过程做一个记录了o( ̄▽ ̄)ブ
尽量用最简洁的语言和最短的代码来实现一个Transformer,ViT,BERT,Swin Transformer
这篇主要实现了Transformer里面的Self-Attention,并实践了文本分类问题
Transformer介绍
Transformer结构是google在17年的Attention Is All You Need论文中提出,在NLP的多个任务上取得了非常好的效果,可以说目前NLP发展都离不开transformer。最大特点是抛弃了传统的CNN和RNN,整个网络结构完全是由Attention机制组成。
更准确地讲,Transformer由且仅由self-Attenion和Feed Forward Neural Network组成。一个基于Transformer的可训练的神经网络可以通过堆叠Transformer的形式进行搭建,作者的实验是通过搭建编码器和解码器各6层,总共12层的Encoder-Decoder,并在机器翻译中取得了BLEU值得新高。
谷歌团队近期提出的用于生成词向量的BERT[3]算法在NLP的11项任务中取得了效果的大幅提升,堪称2018年深度学习领域最振奋人心的消息。而BERT算法的最重要的部分便是本文中提出的Transformer的概念。
参考资料:
TF 2.0 Keras 实现 Multi-Head Attention
TF 2.0 Keras 实现 Transformer
【从 0 开始学习 Transformer】 上篇:Transformer 搭建与理解
【从 0 开始学习 Transformer】 下篇:Transformer 训练与评估
【从 0 开始学习 Transformer】 番外:导师监督,前瞻掩码
3W字长文带你轻松入门视觉transformer
十分钟理解Transformer
详解Transformer (Attention Is All You Need)
论文阅读:Attention Is All You Need
这里就不怎么重复讨论Transformer的结构问题了,我们探讨下代码的实现问题
Embedding
Embedding目的主要是为了将自然语言处理中离散的单词转化为连续的变量,进而运用神经网络进行训练,具体的,是将单词转化为词向量,可以看作一种无监督聚类算法(或者应该是自监督学习?这里我不是很确定),单词语义相近的对应的词向量会比较相近
" Once again Mr. Costner has dragged out a movie for far longer than necessary. Aside from the terrific sea rescue sequences, of which there are very few I just did not care about any of the characters. Most of us have ghosts in the closet, and Costner’s character are realized early on, and then forgotten until much later, by which time I did not care. The character we should really care about is a very cocky, overconfident Ashton Kutcher. The problem is he comes off as kid who thinks he’s better than anyone else around him and shows no signs of a cluttered closet. His only obstacle appears to be winning over Costner. Finally when we are well past the half way point of this stinker, Costner tells us all about Kutcher’s ghosts. We are told why Kutcher is driven to be the best with no prior inkling or foreshadowing. No magic here, it was all I could do to keep from turning it off an hour in."
如何将这个内容转为一个词向量?
首先要有一个字典,字典有固定的长度,字典囊括了数据集中出现的词,词在字典中的位置按照词在数据集中出现的次数从大到小排列。比如这个字典中,‘the’在评论中出现次数最大,the放在字典的第一个位置上;‘and’出现的次数第二多,所以排在第二 …
评论为“I like this movie!”
‘I’在字典中的index为9;
‘like’在字典中的index为37;
‘this’‘在字典中的index为10;
‘movie’在字典中的index为16;
‘!’在字典中的index为28;
这个评论对应的词向量为[9 37 10 16 28]
我们会训练出一个矩阵,大小为[字典大小,词向量维度]
这个矩阵的每一个行向量,都是对应一个单词的词向量
class Embedding(Layer):
def __init__(self,vocab_size,model_dim,**kwargs):
self.vocab_size=vocab_size
self.model_dim=model_dim
super(Embedding,self).__init__(**kwargs)
def build(self,input_shape):
self.embeddings=self.add_weight(
shape=(self.vocab_size,self.model_dim),
initializer="glorot_uniform",
trainable=True,
name="embeddings"
)
super(Embedding,self).build(input_shape)
def call(self,inputs):#其实就是简单的取个行向量出来
inputs=tf.cast(inputs,tf.int32)
embeddings=tf.gather(self.embeddings,inputs)
embeddings*=self.model_dim**0.5 #暂时不清楚为什么
return embeddings
def get_config(self):
config=super(Embedding,self).get_config()
config.update({
"vocab_size":self.vocab_size,
"model_dim":self.model_dim
})
return config
PositionEncoding
区别如RNN,Transformer模型并没有捕捉顺序序列的能力,也就是说无论句子的结构怎么打乱,Transformer都会得到类似的结果。换句话说,Transformer只是一个功能更强大的词袋模型而已。
为了解决这个问题,论文中在编码词向量时引入了位置编码(Position Embedding)的特征。具体地说,位置编码会在词向量中加入了单词的位置信息,这样Transformer就能区分不同位置的单词了。
那么怎么编码这个位置信息呢?常见的模式有:a. 根据数据学习;b. 自己设计编码规则。在这里作者采用了第二种方式(而在ViT中采用了第一种方式)。那么这个位置编码该是什么样子呢?通常位置编码是一个长度为 model_dim 的特征向量,这样便于和词向量进行单位加的操作

论文给出的编码公式如下:

在上式中, pos表示单词的位置, i 表示单词的维度。作者这么设计的原因是考虑到在NLP任务中,除了单词的绝对位置,单词的相对位置也非常重要。
根据公式 ![]()
以及
![]()
这表明位置 K+P的位置向量可以表示为位置 K 和P的特征向量的线性变化,这为模型捕捉单词之间的相对位置关系提供了非常大的便利
可视化编码的结果可以得到如下图像:

代码实现就是公式所示
class PositionEncoding(Layer):
def __init__(self,**kwargs):
super(PositionEncoding,self).__init__(**kwargs)
def build(self,input_shape):
def get_position_encoding(seq_len,model_dim):
position_encoding=np.zeros(shape=(seq_len,model_dim))
for pos in range(seq_len):
for i in range(model_dim):
position_encoding[pos,i]=pos/(np.power(10000,2*i/model_dim))
position_encoding[::,::2]=np.sin(position_encoding[::,::2])
position_encoding[::,1::2]=np.cos(position_encoding[::,1::2])
return np.expand_dims(position_encoding,axis=0)
seq_len,model_dim=input_shape.as_list()[1:3]
self.position_encoding=self.add_weight(
shape=(1,seq_len,model_dim),
initializer=Constant(get_position_encoding(seq_len,model_dim)),
trainable=False,
name="position_encoding"
)
super(PositionEncoding,self).build(input_shape)
def call(self,inputs):
return self.position_encoding
ScaledDotProductAttention
这一步就是实现SelfAttention过程
具体内容请参阅开头的阅读资料
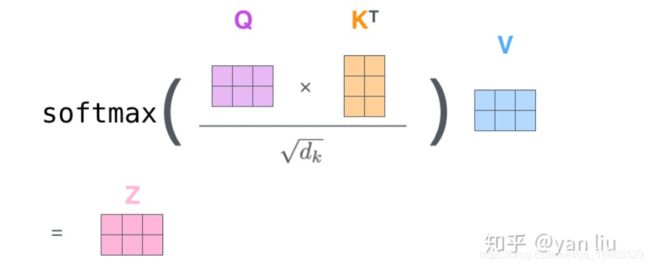
Attention的计算方法,整个过程可以分成7步:
如上文,将输入单词转化成嵌入向量;
根据嵌入向量得到 q,k,v 三个向量;
为每个向量计算一个score=q·k
为了梯度的稳定,Transformer使用了score归一化,即除以 model_dim**0.5
对score施以softmax激活函数;
softmax点乘Value值 ,得到加权的每个输入向量的评分
相加之后得到最终的输出结果
每个 Query 序列对应着一个 Key 序列,但这 Query-Key 组合彼此之间是独立的。完全可以将 Query、Key、Value 堆叠成批,一次运算搞定。矩阵乘法或是转置是针对最后的两个维度,所以只需要保持前置维度匹配(对应,下方注释的要求1.),计算结果和上面完全等效。

Mask(填充遮挡)
如果一个输入句子由于长短不一不方便计算或是其他原因需要补充一些填充标记(pad tokens),显然在输出结果的时候应该把这些无意义的填充标记排除,因此需要一个函数产生此用途的 mask
mask 以乘以一个极大的负数-1e9,然后在加上注意力权重,最终达到使一些位置的 Value 失效的效果
这里tensor在乘以mask后紧跟着就是softmax,一个极大的负数经过softmax后会变为0
def masks(self,inputs,masking):
masking=tf.cast(masking,tf.float32)
masking=tf.tile(masking,[tf.shape(inputs)[0]//tf.shape(masking)[0],1])
#因为MultiHeadAttention的问题,masking的长度和inputs
#长度可能并不等价,而是倍数关系,具体为n_head倍
masking=tf.expand_dims(masking,axis=1)
outputs=inputs+masking*self.masking_num
#乘以一个很大的负数,目的是为了让当前位置的数值失效
return outputs
Lookahead Mask( 前瞻遮挡)
前瞻遮挡通常用于需要只考虑序列中的前一部分的时候,这个遮挡将会用在 Transform 的解码器部分,其设计原理是预测一个单词只考虑此单词前的单词,而不考虑此单词后的部分。
这个将会在Transformer的Decoder部分用到,可以暂时不用深究,前瞻遮挡将会配合teacher forcing(导师监督)来实现一个自回归预测的能力
也就是对于翻译问题,Transformer的推理逻辑是
输入一个单词,输出一个单词的翻译结果
输入两个单词和上一步的翻译结果,输出下一个单词的翻译结果
输入三个单词和上一步的翻译结果,输出下一个单词的翻译结果
一直到翻译结束,而这样的过程就不能让Transformer得到未来的信息
他实际是一个上三角mask矩阵
inputs=tf.random.uniform(shape=(5,5))
diag_masks=1-tf.linalg.band_part(tf.ones_like(inputs),-1,0)
paddings=tf.ones_like(inputs)*(-1e9)
outputs=tf.where(tf.equal(diag_masks,0),inputs,paddings)
print(diag_masks)
print(outputs)
print(tf.nn.softmax(outputs))
'''
tf.Tensor(
[[0. 1. 1. 1. 1.]
[0. 0. 1. 1. 1.]
[0. 0. 0. 1. 1.]
[0. 0. 0. 0. 1.]
[0. 0. 0. 0. 0.]], shape=(5, 5), dtype=float32)
tf.Tensor(
[[ 9.1023731e-01 -1.0000000e+09 -1.0000000e+09 -1.0000000e+09
-1.0000000e+09]
[ 2.9178846e-01 6.4980388e-01 -1.0000000e+09 -1.0000000e+09
-1.0000000e+09]
[ 3.7263584e-01 7.0404112e-01 1.2112439e-01 -1.0000000e+09
-1.0000000e+09]
[ 1.0584772e-01 6.7557812e-01 1.6407859e-01 7.9852629e-01
-1.0000000e+09]
[ 2.9903996e-01 4.6312714e-01 3.7057233e-01 4.8857903e-01
3.9391649e-01]], shape=(5, 5), dtype=float32)
tf.Tensor(
[[1. 0. 0. 0. 0. ]
[0.41144004 0.5885599 0. 0. 0. ]
[0.31540284 0.43933225 0.24526498 0. 0. ]
[0.17162041 0.3033889 0.18191071 0.34308 0. ]
[0.17983395 0.2119014 0.19316916 0.21736394 0.19773158]], shape=(5, 5), dtype=float32)
'''
更具体的放在Transformer的Decoder部分来说
实现如下
def lookahead_mask(self,inputs):#前瞻遮挡,上三角矩阵masks
diag_masks=1-tf.linalg.band_part(tf.ones_like(inputs),-1,0)
paddings=tf.ones_like(inputs)*self.masking_num
outputs=tf.where(tf.equal(diag_masks,0),inputs,paddings)#经过softmax,outputs变为下三角矩阵
return outputs
class ScaledDotProductAttention(Layer):
def __init__(self,masking=True,lookahead_masking=False,dropout_rate=0,**kwargs):
self.masking=masking
self.lookahead_masking=lookahead_masking
self.dropout_rate=dropout_rate
self.masking_num=-1e9
super(ScaledDotProductAttention,self).__init__(**kwargs)
def masks(self,inputs,masking):
masking=tf.cast(masking,tf.float32)
masking=tf.tile(masking,[tf.shape(inputs)[0]//tf.shape(masking)[0],1])
masking=tf.expand_dims(masking,axis=1)
outputs=inputs+masking*self.masking_num
return inputs
def lookahead_masks(self,inputs):
ones=tf.ones_like(inputs)
diag_masking=1-tf.linalg.band_part(inputs,num_lower=-1,num_upper=0)
paddings=ones*self.masking_num
outputs=tf.where(tf.equal(diag_masking,0),inputs,paddings)
return outputs
def call(self,inputs):
if self.masking:
queries,keys,values,masking=inputs
else:
queries,keys,values=inputs
model_dim=queries.shape.as_list()[-1]
matmul=tf.matmul(queries,tf.transpose(keys,[0,2,1]))
scaled=matmul/model_dim**0.5
if self.masking:
scaled=self.masks(scaled,masking)
if self.lookahead_masking:
scaled=self.lookahead_masks(scaled)
softmax=tf.nn.softmax(scaled)
softmax=Dropout(self.dropout_rate)(softmax)
outputs=tf.matmul(softmax,values)
return outputs
def get_config(self):
config=super(ScaledDotProductAttention.self).get_config()
config.update({
"masking":self.masking,
"lookahead_masking":self.lookahead_masking,
"dropout_rate":self.dropout_rate,
"masking_num":self.masking_num
})
return config
MultiHeadAttention

多头注意力机制是将初始的词向量(第一层)或前一层的输入(第二层开始)通过线性变换转换为多组 Query, Key 和 Value,从而得到不同的输出 Z。最后将所有的输出拼合起来,通过可训练的线性变换W0融合为一个输出:

不过很多实现都是保证了分支数量(n_head)*每个分支的维度(head_dim)等于model_dim,也就是并没有最后一层的线性变换
对最后一个维度进行分组(n_head组),然后放在第一个维度(batch_size)的维度.
因此前文的mask需要用tf.tile复制很多倍,是因为这里MultiHeadAttention的缘故
class MultiHeadAttention(Layer):
def __init__(self,n_head=8,head_dim=64,dropout_rate=0.1,masking=True,lookahead_masking=False,trainable=True,**kwargs):
self.n_head=n_head
self.head_dim=head_dim
self.dropout_rate=dropout_rate
self.masking=masking
self.lookahead_masking=lookahead_masking
self.trainable=trainable
super(MultiHeadAttention,self).__init__(**kwargs)
def build(self,input_shape):
self.queries_weight=self.add_weight(
shape=(input_shape[0][-1],self.head_dim*self.n_head),
initializer="glorot_uniform",
trainable=self.trainable,
name="queries_weight",
)
self.keys_weight=self.add_weight(
shape=(input_shape[0][-1],self.head_dim*self.n_head),
initializer="glorot_uniform",
trainable=self.trainable,
name="keys_weight"
)
self.values_weight=self.add_weight(
shape=(input_shape[0][-1],self.head_dim*self.n_head),
initializer="glorot_uniform",
trainable=self.trainable,
name="values_weight"
)
super(MultiHeadAttention,self).build(input_shape)
def call(self,inputs):
if self.masking:
queries,keys,values,masks=inputs
else:
queries,keys,values=inputs
queries=tf.matmul(queries,self.queries_weight)
keys=tf.matmul(keys,self.keys_weight)
values=tf.matmul(values,self.values_weight)
queries=tf.concat(tf.split(queries,self.n_head,axis=-1),axis=0)
keys=tf.concat(tf.split(keys,self.n_head,axis=-1),axis=0)
values=tf.concat(tf.split(values,self.n_head,axis=-1),axis=0)
if self.masking:
attention_input=[queries,keys,values,masks]
else:
attention_input=[queries,keys,values]
attention=ScaledDotProductAttention(
masking=self.masking,
lookahead_masking=self.lookahead_masking,
dropout_rate=self.dropout_rate,
)
attention_out=attention(attention_input)
outputs=tf.concat(tf.split(attention_out,self.n_head,axis=0),axis=-1)
return outputs
def get_config(self):
config=super(ScaledDotProductAttention,self).get_config()
config.update({
"n_head":self.n_head,
"head_dim":self.head_dim,
"dropout_rate":self.dropout_rate,
"masking":self.masking,
"lookahead_masking":self.lookahead_masking,
"trainable":self.trainable
})
return config
模型构建
现在我们用MultiHeadAttention来构建一个文本分类模型
max_len=256
vocab_size=5000
batch_size=64
model_dim=512
inputs=Input(shape=(max_len,))
masking=Input(shape=(max_len,))
embedding=Embedding(vocab_size=vocab_size,model_dim=model_dim)(inputs)
encoding=PositionEncoding()(embedding)
encoding=Add()([embedding,encoding])
x=MultiHeadAttention(n_head=8,head_dim=64)([encoding,encoding,encoding,masking])
x=GlobalAveragePooling1D()(x)
x=Dense(128,activation='relu')(x)
outputs=Dense(2,activation='softmax')(x)
model=tf.keras.models.Model([inputs,masking],outputs)
model.compile(
loss="categorical_crossentropy",
optimizer=tf.keras.optimizers.Adam(lr=0.001),
metrics=['acc']
)
数据集准备
Imdb数据集
MDB数据集是Keras内部集成的,初次导入需要下载一下,之后就可以直接用了。
IMDB数据集包含来自互联网的50000条严重两极分化的评论,该数据被分为用于训练的25000条评论和用于测试的25000条评论,训练集和测试集都包含50%的正面评价和50%的负面评价。该数据集已经经过预处理:评论(单词序列)已经被转换为整数序列,其中每个整数代表字典中的某个单词。
数据集加载
(x_train,y_train),(x_test,y_test)=tf.keras.datasets.imdb.load_data(num_words=vocab_size,maxlen=max_len)
x_train=sequence.pad_sequences(x_train,maxlen=max_len)
x_test=sequence.pad_sequences(x_test,maxlen=max_len)
y_train=tf.keras.utils.to_categorical(y_train,2)
y_test=tf.keras.utils.to_categorical(y_test,2)
x_train_mask=tf.equal(x_train,0)#填充掩码
x_test_mask=tf.equal(x_test,0)
模型训练
model.fit(
[x_train,x_train_mask],
y_train,
validation_data=([x_test,x_test_mask],y_test),
batch_size=batch_size,
epochs=10
)

最终准确率:0.8744