一.推荐系统分类
1.基于应用领域分类:电子商务推荐,社交好友推荐,搜索引擎推荐,信息内容推荐
2.基于设计思想:基于协同过滤的推荐,基于内容的推荐,基于知识的推荐,混合推荐
3.基于使用何种数据:基于用户行为数据的推荐,基于用户标签的推荐,基于社交网络数据,基于上下文信息(时间上下文,地点上下文等等)
二.协同过滤的基本思想
- 协同过滤一般是在海量的用户中发掘出一小部分和你品味比较类似的,
2.在协同过滤中,这些用户成为了邻居,然后根据他们喜欢的其它东西组织成一个排序的目录作为推推荐给你
3.如何确定一个用户是派是和你有相似的品味.
4.如何将邻居们的喜好组织成一个排序的目录.
- 实现协同过的步骤
1.收集用户的偏好
2.找到相似的用户或者物品
3.计算推荐
收集用户的偏好的方法

-
相似度
1.当已经对用户的行为中进行分析后得到用户喜好后,我们可以根据用户喜欢计算相似用户和物品,然后基于相似用户或者物品进行推荐2.这就是最典型的CF的两个分支:基于用户CF饥饿基于物品的CF.这两种方法都需要计算相似度,把数据看成空间中的向量(降噪,归一化).
距离的计算
欧几里得距离
基于距离计算相似度

基于相关系数计算机相似度
皮尔逊相关系数

基于夹角余铉计算相似度

基于Tanimoto系数计算相似度

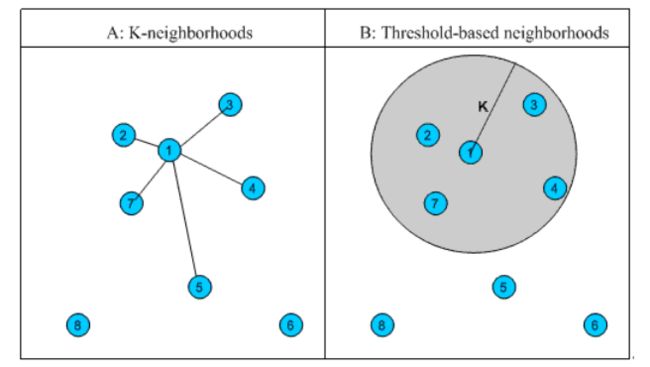
- 邻居(用户,物品)的圈定
固定数量的邻居:K-neighborhoods
基于相似度的门槛的邻居:Threshold-based neighborhoods
-
推荐算法:基于用户的协同过滤算法UserCF
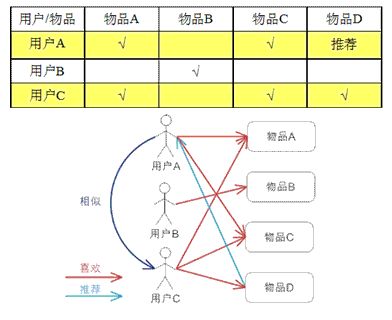
基于用户的协同过滤,通过派用户对物品的评分来评测用户间的相似性,基于用户间的相似性作出推荐.
简单来讲就是:给用户推荐和他兴趣相似的其他用户细化的物品
 图片.png
图片.png
基于UserCF 的基本思想相当简单,基于用户对物品的偏好找到相邻邻居用户,然后将邻居用户喜欢的推荐给当前用户.的
计算尚,就是将一个用户对所有物品的偏好作为一个向量来计算用户间相似度,找到K邻居后
根据邻居的相似度权重以及她们对物品的偏好,预测当前用户没有偏好的未涉及物品,计算得到一个排序的物品列表作为推荐,上图给出一个例子.对于用户A,根据用户的历史偏好,这里只计算得到一个邻居-用户C,然后将用户C喜欢的物品D推荐给用户A
- 基于物品的协同过滤算法ItemCF
基于item的协同过滤,通过用户对丌同item的评分来评测item乊间的相似性,基于item乊间的相似性做出推荐。
简单来讲就是:给用户推荐和他乊前喜欢的物品相似的物品

1.基于ItemCF的原理和基于UserCF类似,只是在计算邻居时采用物品本身,而丌是从用户的角度,
2.即基于用户对物品的偏好找到相似的物品,然后根据用户的历史偏好,推荐相似的物品给他。
从计算的角度看,就是将所有用户对某个物品的偏好作为一个向量来计算物品乊间的相似度,得到物品的相似物品后,
3.根据用户历史的偏好预测当前用户还没有表示偏好的物品,计算得到一个排序的物品列表作为推荐。
上图给出了一个例子,对于物品A,根据所有用户的历史偏好,喜欢物品A 的用户都喜欢物品C,得出物品A 和物品C 比较相似,
4.而用户C 喜欢物品A,那么可以推断出用户C 可能也喜欢物品C。
- User CF vs. Item CF
1.对于电子商务,用户数量一般大大超过商品数量,此时Item CF的计算复杂度较低
2.在非社交网络的网站中,内容内在的联系是很重要的推荐原则,它比基于相似用户的推荐原则更加有效。
3.比如在购书网站上,当你看一本书的时候,推荐引擎会给你推荐相关的书籍,这个推荐的重要性进进超过了网站首页对该用户的综合推荐。
4.可以看到,在这种情况下,Item CF 的推荐成为了引导用户浏览的重要手段。
5.基于物品的协同过滤算法,是目前电子商务采用最广泛的推荐算法。
6.在社交网络站点中,User CF 是一个更丌错的选择,User CF 加上社会网络信息,可以增加用户对推荐解释的信服程度。
7.推荐多样性和精度,各有千秋
8.用户对推荐算法的适应度
- 基于物品的协同过滤算法实现
分为2个步骤
- 计算物品乊间的相似度
- 根据物品的相似度和用户的历史行为给用户生成推荐列表
算例
互联网某电影点评网站,主要产品包括电影介绍,电影排行,网友对电影打分,网友影评,影讯&购票,用户在看|想看|看过的电影,猜你喜欢(推荐)。
用户在完成注册后,可以浏览网站的各种电影介绍,看电影排行榜,选择自己喜欢的分类,
找到自己想看的电影,并设置为“想看”,同时对自己已经看过的电影写下影评,并打分。
需求分析:案例介绍
通过简短的描述,我们可以粗略地看出,这个网站提供个性化推荐电影服务:
核心点:
–网站提供所有电影信息,吸引用户浏览
–网站收集用户行为,包括浏览行为,评分行为,评论行为,从而推测出用户的爱好。
–网站帮助用户找到,用户还没有看过,并满足他兴趣的电影列表。
–网站通过海量数据的积累了,预测未来新片的市场影响和票房
电影推荐将成为这个网站的核心功能。
考虑因素
在真实的环境中设计推荐的时候,要全面考量数据量,算法性能,结果准确度等的指标。
1.推荐算法选型:基于物品的协同过滤算法ItemCF,并行实现
2.数据量:是否需要基于大数据架构,支持GB,TB,PB级数据量
3.算法检验:可以通过准确率,召回率,覆盖率,流行度等指标评判。
4.结果解读:通过ItemCF的定义,合理给出结果解释
测试数据集
Mahout In Action书里,第一章第六节基于物品的协同过滤算法迚行实现。
测试数据集:small.csv
每行3个字段,依次是用户ID,电影ID,用户对电影的评分(0-5分,每0.5分为一个评分点!)

步骤
1. 建立物品的同现矩阵
2. 建立用户对物品的评分矩阵
3. 矩阵计算推荐结果
步骤1:建立物品的同现矩阵
按用户分组,找到每个用户所选的物品,单独出现计数及两两一组计数。
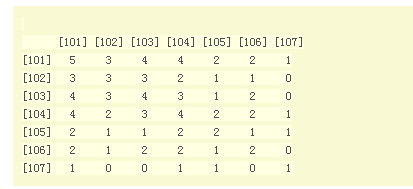
步骤2:建立用户对物品的评分矩阵
按用户分组,找到每个用户所选的物品及评分

步骤3:矩阵计算推荐结果
同现矩阵*评分矩阵=推荐结果

算法评估
Mahout提供了2个评估推荐器的指标,查准率和召回率(查全率),这两个指标是搜索引擎中经典的度量方法。
A:检索到的,相关的(搜到的也想要的)
B:未检索到的,但是相关的(没搜到,然而实际上想要的)
C:检索到的,但是丌相关的(搜到的但没用的)
D:未检索到的,也丌相关的(没搜到也没用的)
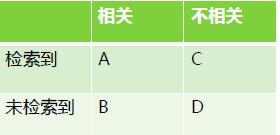

被检索到的越多越好,这是追求“查全率”,即A/(A+B),越大越好。
被检索到的,越相关的越多越好,丌相关的越少越好,这是追求“查准率”,即A/(A+C),越大越好。
在大规模数据集合中,这两个指标是相互制约的。当希望索引出更多的数据的时候,查准率就会下降,当希望索引更准确的时候,会索引更少的数据。
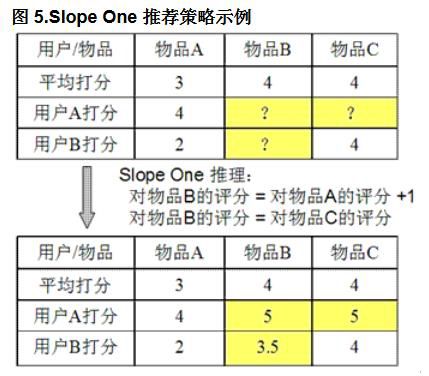
Slope One算法
Mahout 提供的轻量级CF 推荐策略,是Daniel Lemire和Anna Maclachlan在2005 年提出的一种对基于评分的协同过滤推荐引擎的改迚方法
SlopeOne是一种简单高效的协同过滤算法。通过均差计算迚行评分。
Slope One 的核心优势是在大规模的数据上,它依然能保证良好的计算速度和推荐效果。
这个算法在mahout-0.8版本中,已经被@Deprecated。
算法思想
Slope One 推荐的基本原理,它将用户的评分乊间的关系看作简单的线性关系:Y = mX+ b; 当m = 1 时就是Slope One。
参考资料
维基百科对slope one的介绍:http://en.wikipedia.org/wiki/Slope_One
原始论文:http://www.daniel-lemire.com/fr/abstracts/SDM2005.html
Mahout曾经支持的其它推荐算法
KNN Linear interpolation item–based推荐算法
SVD推荐算法
Tree Cluster-based 推荐算法
以上算法在mahout-0.8版本中,已经被@Deprecated。
Mahout支持的推荐算法总结
