R语言学习第三天
迟来的作业,因为坑爹的开题报告,话说之前不知道是咨询了哪个龟儿子,告诉老子开题报告就一张纸,不用担心随便写写就可以了。。我。。算了,算了,要淡定。
看到了今日教程,我尼玛这是什么鬼。。准备工作就这么长,宝宝不开心啊。。
准备工作正式开启
1.tidyr包的安装
最近忙于坑爹开题报告,安装tidyr的时候,遇到了个拦路虎,按照教程将rstdio的packages参数更改为国内的什么广州啊,上海啊,一律都是报错,(原谅本宝宝一气之下给IDE关闭了,没办法截图了)都是无法连接URL啊,无法安装啦。。在此时,我突然想到,卧槽,anaconda这一神器当中是用到清华源的,曾经清华源崩了我还换了科大源用了一段时间,那R语言的CRAN实际上也是在清华源上面有的啊。故去查找了一下清华源的切换方法,想用清华源的宝宝看过来~~
首先,用everthing搜索Rprofile。因为之前用anaconda安装过两次RSTDIO,这尼玛我搜到了一大堆的Rprofile,机智的选择了我现在用的这个路径的Rprofile,按照清华源的要求,打开此文档,将下面代码框中的代码放入文档的最后一行,之后保存。重新开启RSTDIO,即可使用清华源来安装包了
options("repos" = c(CRAN="https://mirrors.tuna.tsinghua.edu.cn/CRAN/"))
自从换了清华源,妈妈再也不用担心我不能安装R语言的包了~~哦,不仅仅是R语言,还有python的包也是可以安装的速度搜搜滴。
2.新建数据框
a <- data.frame(GeneId = rep("gene5",times=3),SampleName = paste("Sample",1:3,sep=""),expression=c(14,19,18))
将上述数据输入到rstdio中之后,得到结果,观察a值,发现如下数据框

根据对上述代码所致结果的拆分,rep=表示的是要重复的值,times是次数,paste是连接字符串,sep=是分隔符。期中这个牛逼的1:3,我们上一次作业已经知道了,是从1到3的这个部分。
那sepression是干啥的呢?是填充无序的数字的例子咯~
3.数据统一化
说实话,我第一次看到tidy的时候,我以为是脏数据(呃。我的英语啊,实在是太差了。)原来是整齐的数据。。正好弄反了。那这个数据统一化呢,作用数据分析的相关处理的小伙伴们都知道是什么啦~再此就不重复了。(其实,是我只能理解,但是无法用语言描述。只可意会不可言传啊。。)
准备工作到此结束咯
天灵灵地灵灵,分割线快显灵。
好了,上面成功的召唤出来了分割线。
一 首先接触的是两个函数
一个是数据统一化的函数:gather
另外一个是让统一化的数据变成不符合统一化的:spread
1.gather 就是变成符合我们的数据统一化的数据函数
gather(数据框,原数据框中的列赋值一个新变量key, 原数据框中的列赋值所有赋值一个新变量value, 指定汇总到一列的列, na.rm = FALSE, convert = FALSE)
na.rm就是是否删除缺失值啦~
那我们之前建立的那个数据表啊,是一个符合的数据表,我们要从新建立一个
X <- data.frame(country=c("a","B","C"),`1999`=paste(c(0.7,37,212),"K"),`2000`=paste(c(2,80,213),"K"))
X长这样
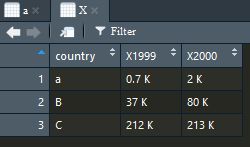
之后,我们按照上面的那个gather的内容敲击进去,但是我们发现数据1999前面多了X,那我们也要多敲进去X哦
结果是这样的

居然还有警告哦~~好高级
2.spread函数
将刚才数据统一化的变成不统一化的。(个人感觉这个函数是将机器容易理解的格式,变成人容易理解的格式)
spread(转换的数据, 增加变量的字段, 需要散开的值, fill = NA, convert = FALSE, drop = TRUE)
fill是缺失值的处理,后面的玩意。。不太清楚啦后面再查~
二 处理丢失的数据
这里面直接用了昨天的doudou.txt数据来作为缺失值的例子
R语言的一大特色就是原生支持excel,比python要好很多啊,所以多用read.csv方便快捷啦~
csv文件的特点是分隔符是, 这个不要忘记就好啦
下面是处理方法函数
- 整行删除 drop_na(数据框名,有空列的列名)
宁杀错不放过的删法,只要有空值,一行都清掉,就是drop_na函数啦,人如其名啊。哦不是。是函数如其名。
-同上填充 fill(数据框名,有空列的列名)
这玩意啦。就是直接给上个数字抄下来,就是同上填充啦。
-同列空值填同数 replace_na(数据框名,填充的列名)
第二个比较奇葩啦。一般来说用这个玩意
list(填充的列名=填充的数字)
三 Expand Tables(展开表格?)
- 补全空值 complete
complete(数据框名,nesting(第一列名),fill = list(第二列名=5))
这玩意和上述的那个,同列空值填同数的方法差不多啦~不过好像可以批量的改诶
- 列出所有可能的值组合 expand
expand(数据框,第一列,第二列,第三列)
这个就牛逼了,真的是所有可能性都列出来了卧槽。
**四 一列拆多列(多列指两列及以上)
这个牛逼了,要是我的钱能一摞变多摞就好了。。
- 按列分割 separate
separate(数据框, 拆分的列, 要建立的列名, sep = “传说中的分隔符”, remove = TRUE, 是否要删除被分割的那一列)
- 按行分割 separate_rows
和上一个差不多啦,不过就是按照某一行来分割
最后一个
- 分割之后在合并(这玩意确定不是脱裤子放屁??后来证明,真不是)
unite(数据框, 组合的新列名, 那些列要组合(和之前1:3差不多啦), sep = “传说中的分隔符,默认下划线”, remove = TRUE是否要删除被分割的那一列)
这个玩意就贼牛逼了。不过我今天实在是太累了。。数据例子的图先不截图了。。后面补充~~
啊坑爹的开题报告幸亏这是老子最后一次写这个JB玩意了。等我毕业了,这玩意就下地狱去吧~拜拜了您内。。