论文:CTPN-Detecting Text in Natural Image with Connectionist Text Proposal Network
0 背景
文本长度、模式变化大和背景高度杂乱构成了文本精确检测的主要挑战。
很难将通用目标检测系统直接应用于场景文本检测,文本检测通常需要更高的定位精度。在通用目标检测中,每个目标都有一个明确的封闭边界,而在文本中可能不存在这样一个明确定义的边界,因为文本行或单词是由许多单独的字符或笔划组成的。对于目标检测,典型的正确检测是松散定义的,例如,检测到的边界框与其实际边界框之间的重叠>0.5,因为人们可以容易地从目标的主要部分识别它。相比之下,综合阅读文本是一个细粒度的识别任务,需要正确的检测,覆盖文本行或字的整个区域。
1 关键的Idea
文本检测和一般目标检测的不同——文本线是一个sequence(字符、字符的一部分、多字符组成的一个sequence),而不是一般目标检测中只有一个独立的目标。这既是优势,也是难点。优势体现在同一文本线上不同字符可以互相利用上下文,可以用sequence的方法比如RNN来表示。难点体现在要检测出一个完整的文本线,同一文本线上不同字符可能差异大,距离远,要作为一个整体检测出来难度比单个目标更大——因此,作者认为预测文本的竖直位置(文本bounding box的上下边界)比水平位置(文本bounding box的左右边界)更容易。所以将文本检测的问题转化为一系列细粒度的文本区域,开发了一个新的锚点回归机制,可以联合预测每个文本区域的垂直位置和文本/非文本分数,从而获得出色的定位精度。这背离了整个目标的RPN预测,RPN预测难以提供令人满意的定位精度。
Top-down(先检测文本区域,再找出文本线)的文本检测方法比传统的bottom-up的检测方法(先检测字符,再串成文本线)更好。自底向上的方法的缺点在于,总结起来就是没有考虑上下文,不够鲁棒,系统需要太多子模块,太复杂且误差逐步积累,性能受限。 作者提出了一种在卷积特征图中优雅连接序列文本区域的网络内循环机制。通过这种连接,检测器可以探索文本行有意义的上下文信息,使其能够可靠地检测极具挑战性的文本。
RNN和CNN两种方法无缝集成可以提高检测精度,CNN用来提取深度特征,RNN用来序列的特征识别(2类),以符合文本序列的性质,从而形成统一的端到端可训练模型。我们的方法能够在单个过程中处理多尺度和多语言的文本,避免进一步的后过滤或细化。
2 细节
2.1 Detecting Text in Fine-scale Proposals
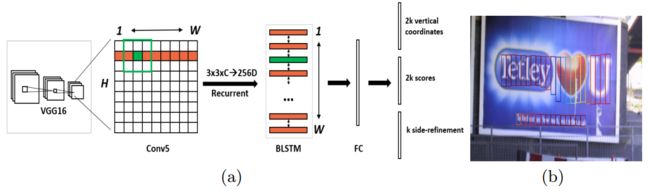
类似于RPN,CTPN本质上是一个全卷积网络,允许任意大小的输入图像。它通过在卷积特征图上密集地滑动小窗口来检测文本行,并且输出一系列细粒度的(例如,宽度为固定的16个像素)文本区域。VGG16的conv5的特征图作为输入,滑动窗口为3x3,conv5特征图的大小由输入图像的大小决定,而总步长和感受野分别固定为16和228个像素(相对于原始图片)。
由RPN进行的单词检测很难准确预测单词的水平边,因为单词中的每个字符都是孤立的或分离的,这使得查找单词的开始和结束位置很混乱。显然,文本行是一个序列,它是文本和通用目标之间的主要区别。将文本行视为一系列细粒度的文本区域是很自然的,其中每个区域通常代表文本行的一小部分,例如宽度为16个像素的文本块。每个区域可能包含单个或多个笔划,字符的一部分,单个或多个字符等。我们认为,通过固定每个区域的水平位置来预测其垂直位置会更准确,水平位置更难预测。与预测目标4个坐标的RPN相比,这减少了搜索空间。我们开发了垂直锚点机制,可以同时预测每个细粒度区域的文本/非文本分数和y轴的位置。检测一般固定宽度的文本区域比识别分隔的字符更可靠,分隔字符容易与字符或多个字符的一部分混淆。此外,检测一系列固定宽度文本区域中的文本行也可以在多个尺度和多个长宽比的文本上可靠地工作。
检测器密集地调查了conv5中的每个空间位置。文本区域被定义为具有16个像素的固定宽度(在输入图像中)。这相当于在conv5的映射上密集地移动检测器,其中总步长恰好为16个像素。然后,我们设计 k 个垂直锚点来预测每个区域的 y 坐标。k 个锚点具有相同的水平位置,固定宽度为16个像素,但其垂直位置在 k 个不同的高度变化。k=10,其高度在输入图像中从11个像素变化到273个像素(每次÷0.7)。明确的垂直坐标是通过提议边界框的高度和y轴中心来度量的。我们计算相对于锚点的边界框位置的相对预测的垂直坐标(v),如下所示:

检测处理总结如下。给定输入图像,我们有 W×H×C conv5特征图(通过使用VGG16模型),其中C是特征图深度或通道的数目,并且W×H是空间尺寸。当我们的检测器通过conv5密集地滑动3×3窗口时,每个滑动窗口使用3×3×C的卷积特征来产生预测。对于每个预测,水平位置(x轴坐标)和k个锚点位置是固定的,可以通过将conv5中的空间窗口位置映射到输入图像上来预先计算。我们的检测器在每个窗口位置输出k个锚点的文本/非文本分数和预测的y轴坐标(v)。检测到的文本区域是从具有 >0.7(具有非极大值抑制)的文本/非文本分数的锚点生成的。通过设计的垂直锚点和细粒度的检测策略,我们的检测器能够通过使用单尺度图像处理各种尺度和长宽比的文本行。这进一步减少了计算量,同时预测了文本行的准确位置。与RPN或Faster R-CNN系统相比,我们的细粒度检测提供更详细的监督信息,自然会导致更精确的检测。

2.2 Recurrent Connectionist Text Proposals
为了提高定位精度,我们将文本行分成一系列细粒度的文本提议,并分别预测每个文本提议。显然,将每个孤立的提议独立考虑并不鲁棒。这可能会导致对与文本模式类似的非文本目标的误检,如窗口,砖块,树叶等。还可以丢弃一些含有弱文本信息的模糊模式。图3给出了几个例子(上)。文本具有强大的序列特征,序列上下文信息对做出可靠决策至关重要。最近的工作已经证实了这一点,其中应用递归神经网络(RNN)来编码用于文本识别的上下文信息。他们的结果表明,序列上下文信息极大地促进了对裁剪的单词图像的识别任务。

上下文信息对于我们的检测任务也很重要,检测器应该能够探索这些重要的上下文信息,以便在每个单独的提议中都可以做出更可靠的决策。此外,我们的目标是直接在卷积层中编码这些信息,从而实现细粒度文本提议优雅无缝的网内连接。RNN提供了一种自然选择,使用其隐藏层对这些信息进行循环编码。为此,我们提出在conv5后设计一个RNN层,它将每个窗口的卷积特征作为序列输入,并在隐藏层中循环更新其内部状态:Ht。
其中Xt∈R3×3×C是第t个滑动窗口(3×3)的输入conv5特征。滑动窗口从左向右密集移动,导致每行的t=1,2,…,W序列特征。W是conv5的宽度。Ht是从当前输入(Xt)和以Ht−1编码的先前状态联合计算的循环内部状态。递归是通过使用非线性函数φ来计算的,它定义了循环模型的确切形式。我们利用长短时记忆(LSTM)架构作为我们的RNN层。通过引入三个附加乘法门:输入门,忘记门和输出门,专门提出了LSTM以解决梯度消失问题。因此,RNN隐藏层中的内部状态可以访问所有先前窗口通过循环连接扫描的序列上下文信息。我们通过使用双向LSTM来进一步扩展RNN层,这使得它能够在两个方向上对递归上下文进行编码,以便连接感受野能够覆盖整个图像宽度,例如228×width。我们对每个LSTM使用一个128维的隐藏层,从而产生256维的RNN隐藏层Ht∈R256。
Ht中的内部状态被映射到后面的FC层,并且输出层用于计算第t个提议的预测。因此,我们与RNN层的集成非常优雅,从而形成了一种高效的模型,可以在无需额外成本的情况下进行端到端的训练。RNN连接的功效如图3所示。显然,它大大减少了错误检测,同时还能够恢复很多包含非常弱的文本信息的遗漏文本提议。
2.3 Side-refinement(边缘细化)
文本线构造算法(多个细长的proposal合并成一条文本线) 。主要思想:每两个相近的proposal组成一个pair,合并不同的pair直到无法再合并为止(没有公共元素)
判断两个proposal,Bi和Bj组成pair的条件:
- Bj->Bi, 且Bi->Bj。(Bj->Bi表示Bj是Bi的最好邻居)
- Bj->Bi条件1:Bj是Bi的邻居中距离Bi最近的,且该距离小于50个像素
- Bj->Bi条件2:Bj和Bi的垂直重叠大于0.7
细粒度的检测和RNN连接可以预测垂直方向的精确位置。在水平方向上,图像被分成一系列相等的宽度为16个像素的区域。当两个水平边的文本区域完全没有被实际文本行区域覆盖,或者某些边的区域被丢弃(例如文本得分较低)时,这可能会导致不准确的定位。这种不准确性在通用目标检测中可能并不重要,但在文本检测中不应忽视,特别是对于那些小型文本行或文字。为了解决这个问题,我们提出了一种边缘细化的方法,可以精确地估计左右两侧水平方向上的每个锚点/区域的偏移量(称为边缘锚点或边缘区域)。与y坐标预测类似,我们计算相对偏移为:
,其中x_side是最接近水平边(例如,左边或右边)到当前锚点预测的x坐标。x∗side是x轴的实际(GT)边缘坐标,它是从实际边界框和锚点位置预先计算的。cax是x轴的锚点的中心。wa是固定的锚点宽度,wa=16。当我们将一系列检测到的细粒度文本提议连接到文本行中时,这些提议被定义为开始和结束提议。我们只使用边缘提议的偏移量来优化最终的文本行边界框。模型同时预测了边缘细化的偏移量,不是通过额外的后处理步骤计算的。
2.4 模型输出与损失函数
提出的CTPN有三个输出共同连接到最后的FC层。这三个输出同时预测公式(2)中的文本/非文本分数,垂直坐标(v={vc,vh})和边缘细化偏移(o)。我们将探索k个锚点来预测它们在conv5中的每个空间位置,从而在输出层分别得到2k,2k和k个参数。

,其中每个锚点都是一个训练样本,i是一个小批量数据中一个锚点的索引。si是预测的锚点i作为实际文本的预测概率。si∗={0,1}是真实值。j是y坐标回归中有效锚点集合中锚点的索引,定义如下。有效的锚点是定义的正锚点(sj∗=1,如下所述),或者与实际文本区域重叠的交并比(IoU)>0.5。vj和vj∗是与第j个锚点关联的预测的和真实的y坐标。k是边缘锚点的索引,其被定义为在实际文本行边界框的左侧或右侧水平距离(例如32个像素)内的一组锚点。ok和ok∗是与第k个锚点关联的x轴的预测和实际偏移量。Lscl是我们使用Softmax损失区分文本和非文本的分类损失。Lvre和Lore是回归损失。我们遵循以前的工作,使用平滑L1函数来计算它们。λ1和λ2是损失权重,用来平衡不同的任务,将它们经验地设置为1.0和2.0。Ns, Nv和No是标准化参数,表示Lscl,Lvre, Lore分别使用的锚点总数。
2.5 训练
通过使用标准的反向传播和随机梯度下降(SGD),可以对CTPN进行端对端训练。与RPN类似,训练样本是锚点,其位置可以在输入图像中预先计算,以便可以从相应的实际边界框中计算每个锚点的训练标签。
训练标签:
- 对于文本/非文本分类,二值标签分配给每个正(文本)锚点或负(非文本)锚点。它通过计算与实际边界框的IoU重叠(除以锚点位置)来定义。正锚点被定义为:(i)与任何实际边界框具有>0.7的IoU重叠;或者(ii)与实际边界框具有最高IoU重叠。通过条件(ii),即使是非常小的文本模式也可以分为正锚点。这对于检测小规模文本模式至关重要,这是CTPN的主要优势之一。负锚点定义为与所有实际边界框具有<0.5的IoU重叠。
- y坐标回归(v∗)和偏移回归(o∗)的训练标签分别按公式(2)和(4)计算。
训练数据。在训练过程中,每个小批量样本从单张图像中随机收集。每个小批量数据的锚点数量固定为Ns=128,正负样本的比例为1:1。如果正样本的数量少于64,则会用小图像块填充负样本。我们的模型在3000张自然图像上训练,其中包括来自ICDAR 2013训练集的229张图像。我们自己收集了其他图像,并用文本行边界框进行了手工标注。在所有基准测试集中,所有自我收集的训练图像都不与任何测试图像重叠。为了训练,通过将输入图像的短边设置为600来调整输入图像的大小,同时保持其原始长宽比。
实现细节。我们遵循标准实践,并在ImageNet数据[26]上探索预先训练的非常深的VGG16模型[27]。我们通过使用具有0均值和0.01标准差的高斯分布的随机权重来初始化新层(例如,RNN和输出层)。该模型通过固定前两个卷积层中的参数进行端对端的训练。我们使用0.9的动量和0.0005的重量衰减。在前16K次迭代中,学习率被设置为0.001,随后以0.0001的学习率再进行4K次迭代。我们的模型在Caffe框架[17]中实现。
3 基本流程
- 用VGG16的前5个Conv stage(到conv5)得到feature map(WHC)。
- 在Conv5的feature map的每个位置上取3x3xC的窗口的特征,这些特征将用于预测该位置k个anchor对应的类别信息,位置信息。
- 将每一行的所有窗口对应的3x3xC的特征(Wx3x3xC)输入到RNN(BLSTM)中,得到Wx256的输出。
- 将RNN的Wx256的输出输入到512维的fc层。
- fc层输出的特征输入到三个分类或者回归层中。第二个2k scores 表示的是k个anchor的类别信息(是字符或不是字符)。第一个2k vertical coordinate和第三个k side-refinement是用来回归k个anchor的位置信息。2k vertical coordinate表示的是bounding box的高度和中心的y轴坐标(可以决定上下边界),k个side-refinement表示的bounding box的水平平移量。这边注意,只用了3个参数表示回归的bounding box,因为这里默认了每个anchor的width是16,且不再变化(VGG16的conv5的stride是16)。
- 用简单的文本线构造算法,把分类得到的文字的proposal中的细长的矩形)合并成文本线。
4 实验结果
- 时间:0.14s with GPU
- ICDAR2011,ICDAR2013,ICDAR2015库上检测结果

5 总结
- 这篇文章的方法最大亮点在于把RNN引入检测问题(以前一般做识别)。文本检测,先用CNN得到深度特征,然后用固定宽度的anchor来检测text proposal(文本线的一部分),并把同一行anchor对应的特征串成序列,输入到RNN中,最后用全连接层来分类或回归,并将正确的text proposal进行合并成文本线。这种把RNN和CNN无缝结合的方法提高了检测精度。