1. Automatic 3D bi-ventricular segmentation of cardiac images by a shape-constrained multi-task deep learning approach
第一作者:
尽管DL在心脏磁共振图像(CMR)分割中实现了SOTA性能,但是关于整合解剖形状先验的关注还比较少。本文整合多任务深度学习方法和atlas传播,得到一个用于短轴CMR体数据 形状约束的双心室分割pipeline。首先采用2.5D FCN同时分割和定位landmark。其次显示的施加形状约束,这对克服图像artifacts非常有效。在1831个健康被试和649个肺动脉高压被试上做了实验。
20个合成数据上的分割结果对比
| Model | Endocardium Dice | Myocardium |
|---|---|---|
| 3D Unet | 0.923 | 0.764 |
| 3D ACNN(TMI) | 0.939 | 0.811 |
| 本文方法 | 0.943 | 0.854 |
Notes: 比baseline提升了2个点,比通过自动编码学习到的形状提升了不到一个点。显示的解剖约束要比学到的约束更好一点。
2. Norm matters: efficient and accurate normalization schemes in deep networks
作者:Elad Hoffer,Israel Institute of Technology;(pytorch代码)
让BN有优势背后的原因还不很清楚,从而在拿到一个新的任务时,不知道该不该用BN。本文对normalization和weight-decay方法的目的和功能展示了一个新的视角:, as tools to decouple weights’ norm from the underlying optimized objective. 本文也展示了normalization, weight decay和learning-rate adjustments之间的联系,最后建议在L1和L无穷空间(取代常用的L2)中使用BN,能在低精度实现中提升稳定性。
问题:BN如何与weight decay (L2正则)搭配或者已经有BN了,是否有必要加上weight decay?
在normalization之前使用weight delay是冗余的。通过调整学习率或者normalization方法,我们可以精确模拟权重下降对learning dynamics的影响。
BN中一个关键的假设是每个batch出现的样本是独立的。这对大部分CNN都是成立的,但是对于样本相关性很大的domain就不成立了,比如时间序列数据。
本文贡献
- 通过 bounding the norm in weight normalization scheme,可以显著的提升CNN在imagenet上的性能(跟BN接近),同时减小计算量。重要的一点是,为了让方法work well,我们需要很小心的选择初始化权重的scale。
- 用L1和L无穷取代L2,不降低精度的情况下提升了速度,这两个范数更适合于硬件上的低精度实现。重要的是,for these normalization schemes to work well, precise
scale adjustment is required, which can be approximated analytically.
总之,神经网络学习过程对权重的范数非常敏感,将来重要的研究是search for precise and theoretically justifiable methods to adjust the scale for these norms。
最优的学习率和batch-size之间,以及weight-decay factor和学习率之间,有很强的关联。
3. 机器学习那些事,A Few Useful Things to Know About Machine Learning
作者:Pedro Domingos,刘知远译,2012,Communications of the ACM
成功的使用机器学习,还得掌握一些课本上没有的“民间知识”。本文以分类任务为例介绍。
1. 学习=表示+评价+优化
绝大部分机器学习算法都是由这三部分组成的。表示就意味着为ML建立假设空间,评价即建立损失函数,优化是在假设空间中找到分类性能最优的参数。大部分教科书主要以表示为视角组织内容,但实际上,这三部分同等重要。
2. 将泛化作为目标
但此时无法获得希望优化的函数,因此不得不用测试误差代替训练误差。但从积极的角度讲, 由于这个目标函数不过是真实目标的替身, 我们也
许没有必要完全优化它; 而实际上, 通过简单的贪心搜索返回的局部最优也许比全局最优更好。
3. 仅仅有数据还不够
每个学习器都必须包含一些数据之外的知识或假设( assumption) , 才能够将数据泛化。(Wolpert形式化为没有免费的午餐)。选择表示学习的关键标准之一是:它比较易于表达什么类型的知识。比如有很多图像以及相应的分割结果,那么基于实例的方法更合适;如果有每个类别要求的先决条件,那么if-than的规则表示更适合。机器学习需要知识,学习器将知识和数据结合种出程序。
4. 过拟合
一个强错误假设比那些弱正确假设更好, 这是因为后者需要更多的数据才能避免过拟合。??怎么理解
避免过拟合的方法
- 交叉验证
- 对评价函数加正则项
- 统计显著性检验:chi-squre测试
- 错误发现率方法(false discovery rate)???
对过拟合的一个误解:是由噪声造成的。训练集没有噪音也会过拟合。
5. 直觉不适用于高维空间
Bellman于1961年提出的维数灾难:低维空间表现很好的算法,当输入是高维数据的时候,就变得intractable。 随着样例维度( 即特征数目) 的增长, 正确泛化的难度会以指数级增加, 原因是同等规模的训练集只能覆盖越来越少的输入空间比例。更严格的讲,机器学习所依赖的基于相似度的推理在高维空间不再有效。
我们来自三维世界的直觉在高维空间通常并不奏效。高维空间多元高斯分布的大部分质量并不分布在均值附近而是在逐渐远离均值的一层壳上面。打个比方:一个高维橘子的大部分质量不在瓤上,而是在皮上。
如果数量一定的样例均匀分布在一个( 维数不断增加的) 高维的超立方体中, 那么超出某个维数后, 大部分样例与超立方体的某一面的距离要小于与它们最近邻的距离。 如果我们在超立方体中内接一个超球面, 那么超立方体的几乎所有质量都会分布在超球面之外。 这对机器学习是一个坏消息, 因为机器学习常常用一种类型的形状来近似另一种类型的形状。
在高维空间中人们很难理解正在发生什么。 因此也就很难设计一个好的分类器。 人们也许会天真地认为收集更多的特征永远不会有什么坏处, 因为最坏的情况也不过是没有提供关于类别的新信息而已。 但实际上这样做的好处可能要远小于维度灾难带来的问题。
幸运的是blessing of nonuniformity效应可以在一定程度上抵消维数灾难,在大多数应用中, 样例在空间中并非均匀分布, 而是集中在一个低维流形( manifold) 上面或附近。 比如手写数字识别,把每一个像素点都作为单独的特征,KNN也可以表现的不错,因为数字图像的空间要远远小于整个可能的空间。学习器可以隐式地充分利用这个有效的更低维空间, 也可以显式地进行降维。
6. 理论保证与看上去的不一样
- 常用的一种是保证泛化所需样本数目的边界。
首先要注意这些保证是否可行。 - 另一种是渐进(asymptotic):给定无穷数据,学习器将保证输出正确的分类器。
机器学习中理论保证的主要作用并不是在实践中作为决策的标准,而是在算法设计中作为理解和驱动的来源。在这方面,它们作用巨大; 但是使用者需要谨慎: 学习是一个复杂现象, 因为一个学习器既有理论证明又有实际应用,而前者并未成为后者的依据。
7. 特征工程是关键
通常原始数据不能直接拿来学习, 你需要从中构建特征。 这是机器学习项目的主要工作。
现在经常采用的一种方式是先自动产生大量的候选特征, 然后根据它们与分类类别的信息增益等方法来选取最好的特征。 但是要牢记:**特征独立地看也许与分类无关, 但组合起来也许就相关了。 **
8. 更多的数据胜过更聪明的算法
假设已经尽力构建好了特征集合,但是分类器性能还是不好,通常接下来有2种选择
- 设计更好的学习算法
- 收集更多的数据。从实用和经验的角度,有大量数据的笨办法要胜过数据量较少的聪明办法。
即使理论上说, 更多数据意味着我们可以学习更复杂的分类器, 但在实践中由于复杂分类器需要更多的学习时间, 我们只能选用更简单的分类器。
机器学习的工作机制基本上是相同的,都是将临近的样例归类到同一个类别中。关键的不同在于临近的意义。
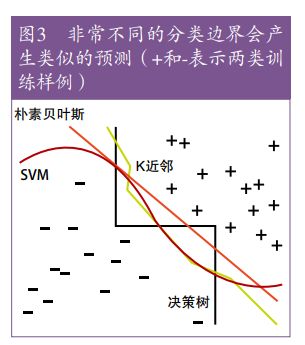 对于非均匀分布的数据,不同的学习器可以产生不同的分类边界。这也解释了能力强的分类器虽然不稳定,但是很精确
对于非均匀分布的数据,不同的学习器可以产生不同的分类边界。这也解释了能力强的分类器虽然不稳定,但是很精确
推荐采纳的规则:先尝试简单的学习器(例如先朴素贝叶斯再logistics,先KNN再SVM)。
学习器可以分为两类:一类的表示是大小不变的,比如线性分类器;另一类会随着数据而增长,比如决策树。
数据超过一定数量后,大小不变的学习器就不能再从中获益。
4. Multi-Institutional Deep Learning Modeling Without Sharing Patient Data: A Feasibility Study on Brain Tumor Segmentation
作者: Micah J Sheller, G Anthony Reina, Brandon Edwards, Jason Martin, Spyridon Bakas
采用Federated Learning. 每个机构不分享自己的数据,只提到模型权重的更新到中央服务器。 Each iteration of this process: local training, update aggregation, and
distribution of new parameters, is called a federated round。
5. Can We Gain More from Orthogonality Regularizations in Training Deep CNNs? NIPS 2018 (code)
We develop novel orthogonality regularizations on training deep CNNs, utilizing various advanced analytical tools such as mutual coherence and restricted isometry property. These plug-and-play regularizations can be conveniently incorporated into training almost any CNN without extra hassle.
6. BraTS 2018总结(paper)
Identifying the Best Machine Learning Algorithms for Brain Tumor Segmentation, Progression Assessment, and Overall Survival Prediction in the BRATS Challenge
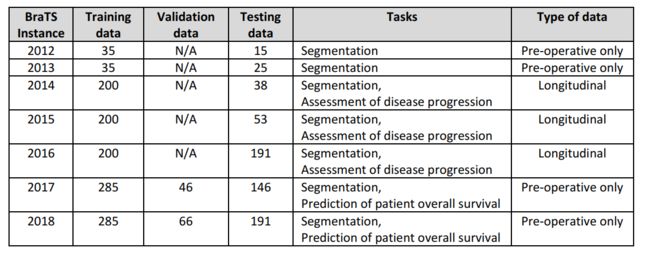
排名方法:The ranking scheme followed during the BraTS 2017 and 2018 comprised the ranking of each team relative to its competitors for each of the testing subjects, for each evaluated region (i.e., AT, TC, WT), and for each measure. The final ranking score was then calculated by averaging across all these individual rankings and then normalized by dividing by the number of teams.
BraTS 2012-2013 结论:1)尽管单个的算法perform well,但是他们没有outperform the inter-rater agreement. 2)the fusion of segmentation labels from top-ranked algorithms outperformed all individual methods and was comparable to inter-rater agreement. 单个的自动算法do not necessarily rank equally well in the
different tumor segmentation tasks and under all metrics. the fused segmentation labels do consistently rank first in all tasks and both metrics. 这表明 ensembles of fused segmentation algorithms may be the favorable approach when translating tumor segmentation methods into clinical practice.BraTS 2018:就Dice中值而言,大部分算法都perform relatively well,但是评价dice的鲁棒性受到影响by increasing number of outliers in the results。对于95% Hausdorff distance metric,the results for the AT seems to be the most robust for all three tumor labels,随后是WT和TC。 Worth noting is that the variability of the ranking of approaches at the case level does not dramatically change across teams, indicating no particular dominance of a method over the others.
Discussion: 尽管的单个的自动分割算法性能得到了提升,但是他们的鲁棒性不如专家,通过增加训练集数量以及改进网络有望提升鲁棒性。 The results of our quantitative analyses support that the fusion of segmentation labels from various individual automated methods shows robustness superior to the ground truth inter-rater agreement (provided by clinical experts), in terms of both accuracy and consistency across subjects.
Beyond segmentation: 强调clinically-relevant tasks. 利用分割结果answer clinical questions, address clinical requirements, and potentially support the clinical decision-making process.
Concentrating the segmentaiton task, the current general consensus seems to point in the direction of tackling the problem in a hierarchical/cascaded way, by first distinguishing between normal and abnormal/tumorous tissue, and then proceeding with the segmentation of the tumor sub-regions.