网络配置
命令:
你的虚拟机也可能是ens33
vi /etc/sysconfig/network-scripts/ifcfg-ens32
修改如下
IPADDR的网段要与上图中的子网IP网段一致,GATEWAY的网段也要一致(前段数字都要一样,最后一段数字随意
不要用2-255)

配置网络工作
在 /etc/sysconfig/network 文件里增加如下配置
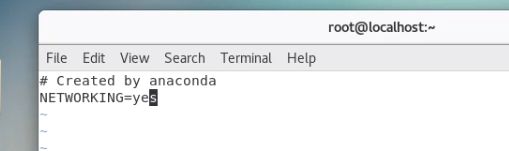
关闭防火墙并重启

我们发现ping无法使用时

ctrl+c退出
centos7配置(三台虚拟机都需要配置)
1.配置自动时钟同步
该项同时需要在HadoopSlave节点配置。
1.1使用Linux命令配置
[root@master ~]# crontab -e
vi下的操作大家一定要会
该命令是vi编辑命令,按i进入插入模式,按Esc,然后键入:wq保存退出
键入下面的一行代码,输入i,进入插入模式(星号之间和前后都有空格)
*/5 * * * * ntpdate -u ntp1.aliyun.com
2.配置主机名
2.1HadoopMaster节点
使用vi编辑主机名
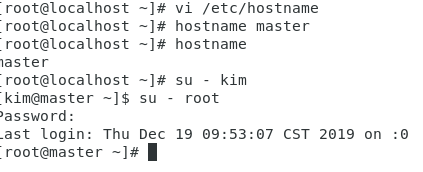
[root@master ]# vi /etc/hostname
配置信息如下,如果已经存在则不修改,将HadoopMaster节点的主机名改为master,即下面代码的第2行所示。
master
确实修改生效命令:
[root@master kkb]# hostname master
检测主机名是否修改成功命令如下,在操作之前需要关闭当前终端,重新打开一个终端:
[root@master kkb]# hostname
2.2HadoopSlave节点(两个Slave节点)
使用vi编辑主机名:
[root@slave kkb]# vi /etc/hostname
配置信息如下,如果已经存在则不修改,将Hadoopslave节点的主机名改为slave,即下面代码的第
2行所示。 slave01
另一台改为
slave02
确实修改生效命令:
[root@slave kkb]# hostname slave01

另一台执行
[root@slave kkb]# hostname slave02

检测主机名是否修改成功命令如下,在操作之前需要关闭当前终端,重新打开一个终端: [root@slave kkb]#
hostname
[图片上传中...(image.png-ba3c18-1576726720350-0)]
5.配置hosts列表(配置映射列表)
该项也需要在HadoopSlave节点配置。
需要在root用户下(使用su命令),编辑主机名列表的命令:
[root@master ~]# vi /etc/hosts
将下面两行添加到/etc/hosts文件中:
192.168.48.128 master
192.168.48.129 slave01
192.168.48.130 slave02
三台虚拟机都需要配置
注意:这里master节点对应IP地址是192.168.48.128,slave1对应的IP是192.168.48.129,slave2对应的IP是192.168.48.130,而自己在做配置时,需要将这两个IP地址改为你的master和slave对应的IP地址

配置完毕后查看ifconfig
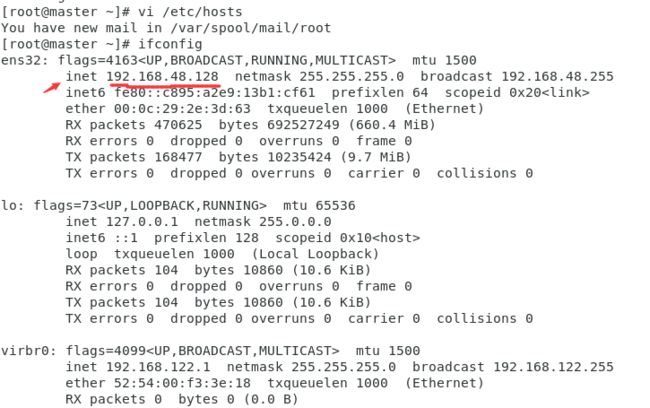
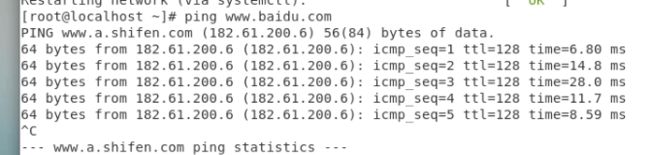
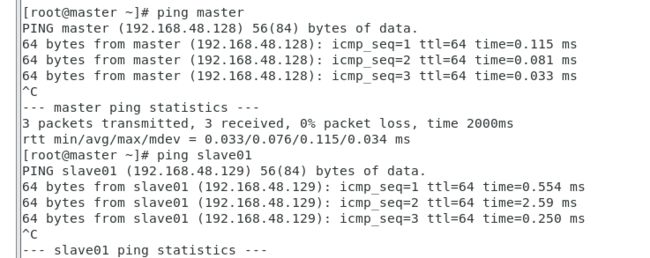
可以用ping来查看是否连通
[root@master ~]$ ping slave01
[kkb@master ~]$ ping slave02
[kkb@slave01 ~]$ ping master
[kkb@slave02 ~]$ ping master
如果出现下图的信息表示配置成功:
6.安装JDK
该项也需要在HadoopSlave节点配置。
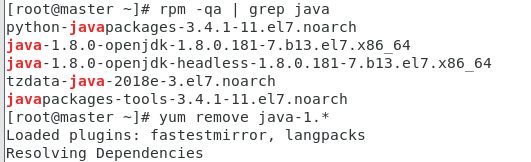
首先查询系统自带的jdk,但我们一般不使用
[kkb@master ~]$ rpm -qa | grep java
然后移除系统自带的jdk
[root@master ~]# yum remove java-1.* # *号代表是占位符
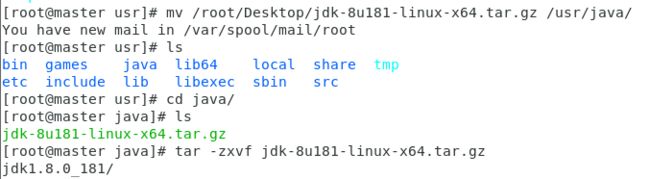
将JDK文件解压,放到/usr/java目录下

放入文件有2种方式:
第一种直接复制
因为我们的解压包在桌面上所以先移动/usr/java/下,再解压
使用cd命令回到root用户的家目录下
[root@master java]$ cd
使用vi配置环境变量root用户下
[root@master ~]$ vi .bash_profile
复制粘贴以下内容添加到到上面vi打开的文件中:
#我们提前把hadoop的环境变量设好了
JAVA_HOME=/usr/java/jdk1.8.0_181/
HADOOP_HOME=/software/hadoop/hadoop-2.7.3
PATH=$PATH:$HOME/bin:$JAVA_HOME/bin:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
export JAVA_HOME
export HADOOP_HOME
export PATH
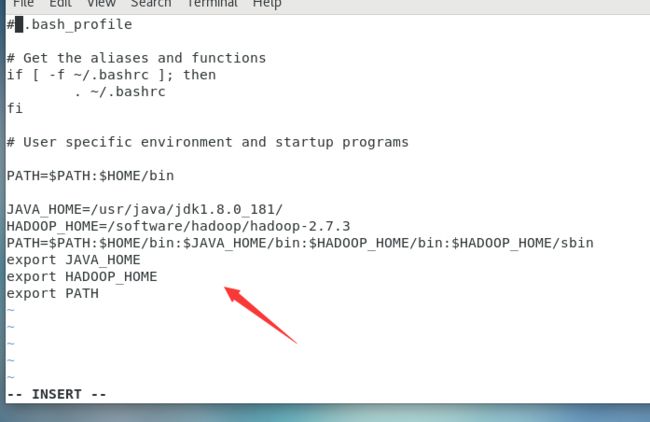
接着让环境变量生效
#环境变量生效
[root@master ~]$ source .bash_profile
#测试配置:
root@master ~]$ java -version

7.免密钥登录配置(root用户与普通用户均需要配置)
7.1三个节点分别执行生成秘钥的命令
[root@master ~]# ssh-keygen -t rsa #一路回车完成秘钥生成
[root@slave01 ~]# ssh-keygen -t rsa #一路回车完成秘钥生成
[root@slave02 ~]# ssh-keygen -t rsa #一路回车完成秘钥生成
7.2在master节点上做示范,以下的命令需要在所有节点上执行
[root@master ~]# ssh-copy-id -i slave01
[root@master ~]# ssh-copy-id -i slave02
以node1节点作为示范,其他节点需要相应的验证.如果免密码登录失败,会提示输入登录密码,此时重复7.1和7.2等两个步骤
[root@master ~]# ssh slave01
[root@master ~]# ssh slave02
ssh远程登录其他节点后,可使用exit退回到本机节点
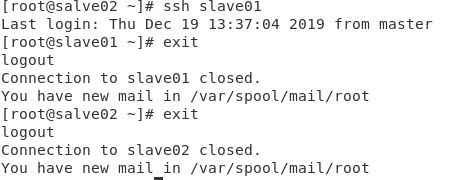
8. 创建hadoop用户和hadoop组
此用户用于操作hadoop集群,因此也需要对此用进行免密码登录配置.此处以node1节点为例,其他节点也需要按照以下步骤操作.
[root@node1 ~] useradd kkb
[root@node1 ~] passwd kkb #密码输入kkb
[root@node1 ~] groupadd kkb #创建kkb用户组
[root@node1 ~] usermod -G kkb kkb #讲hadoop添加到hadoop组中
[root@node1 ~] su - kkb #切换到hadoop用户目录下
[kkb@master ~]# ssh-keygen -t rsa #一路回车完成秘钥生成
[kkb@master ~]$ cd .ssh
[kkb@master .ssh]$ cat id_rsa.pub >> authorized_keys #将生成的公钥添加到认证文件中
在普通用户下做ssh操作与上面root用户做ssh操作相同,三台都要做,只是多出一步将公钥添加到认证文件
(普通用户意味着权限稍弱)
先cd 返回根目录,重复上面7.2,7.3操作