对于R语言的学习是在某位知乎大V的推荐下开始的,自己之前的学习不管是针对数据分析,数据挖掘还是机器学习,都是基于Python进行的。但在看了大量用R做数据分析的代码后,发现R在对数据进行统计分析时时非常简便的,并且其在可视化这一方面个人感觉是强于python的。于是就打算把R语言学习下,作为后面的基本统计分析和可视化这一块来使用。而在进行数据的抓取,清洗,机器学习这一方面,就用python了。
鉴于自己的后面的工作内容是游戏相关的数据分析,于是就在图书馆借了这本乐逗游戏高级数据分析师谢佳标老师写的书《R语言游戏数据分析与挖掘》,从前言和目录来看,这本书更偏实战,而不是介绍一大堆公式及其推理过程,作者也在GitHub上附上了本书案例讲解使用的数据,对自己来说,这样的书就是非常适合的了。

这本书虽然讲的是游戏行业,但是仅仅是在业务场景上是游戏行业,如果是其他行业的也没有关系,替换到自己行业的具体场景即可,所用的技术实现方法都大同小异。
一,R语言的基础
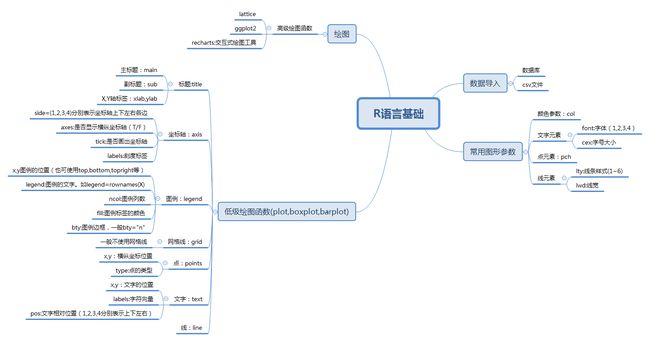
基础部分的内容都比较散,多是一些记忆类的东西,这里用Xmind做了一个大概的基础框架,细节问题,遇到再查。
二,实战篇——数据的预处理
对数据工作有了解的同学一定听过这样的一句话“garbage in,garbage out”。做数据工作不管是基本的统计分析还是预测建模,机器学习,数据的质量决定着最终结果的好坏。因此在进行正式的数据分析工作之前,最为重要的就是将数据变得干净,变成分析语言能够识别,处理的样子。
1.数据抽样
1>数据抽样的必要性
当数据中某一类数据明显多余另一类数据,这时建立的模型就会有明显的倾向性,导致最终结果的错误。
2>类失衡处理方法:SMOTE
所谓的类失衡,指的就是在数据中某两类数据的数据量不对等,差距大,这个时候需要对数据进行均衡化处理。
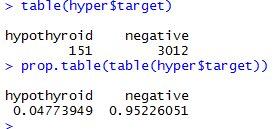
这里我们的hyper数据中标签为target的名下有两种类型的因子:一种是hypothyroid,一种是negative,他们占的比例为95:5。这样的一个差距数据明显的类失衡,需要对其做平衡处理,这里我们用DMwR包中的SMOTE函数进行处理。

在这里:# perc.over=100:表示少数样本数=151+151*100%=302(原始数据集中每个少数的样本,都生成一个新样本)
# perc.under=200:表示多数样本数(新增少数样本数*200%=151*200%=302)
现在看,我们的hypothyroid和negative的数据量就平衡了,我在建模时就可以用hyper_new中的数据了。
3>数据随机抽样:sample函数
sample函数相对来说比较简单:sample(x,size,replace=FALSE,prob=NULL)。这里x是数值型向量,size是抽样的个数,replace表示是否有放回抽样,默认FALSE是不放回,TRUE是有放回。
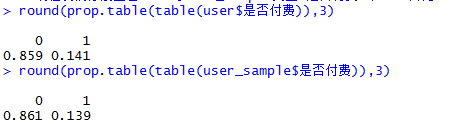
这里就是我们用户是否付费在原始数据user中的比例和经过sample函数抽取的数据user_sample中的比例。比例差距不是太大,说明还是满足随机抽样的原则的。
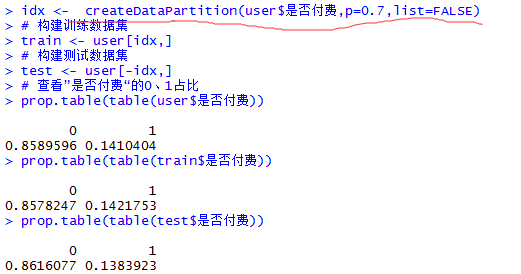
4>数据等比抽样:createDataPartition函数
createDataPartition是caret包中的一个函数,它可以快速实现对数据按照因子变量的类别进行快速等比例抽样。createDataPartition(y, times = 1, p = 0.5, list = TRUE, groups = min(5,
length(y)))。这里y是一个向量,times表示要抽样的次数,p表示从样本中抽取的比例,list表示结果是否为list形式group表示如果输出变量为数值型数据,则默认按分位数分组进行取样。
2.数据清洗
在我们收集到的数据样本中,往往会有很多的缺失值,异常值这些,如果我们不对这些数据进行清洗,那么久很有可能造成我们最终分析结果的不准确,或者分析过程中出现异常,因此在数据分析过程中,数据清洗往往占据着非常大的比重。
1>缺失值判断及其处理
One:识别缺失值
这里我们识别缺失值主要有两种方式,一种是用is.na()函数进行识别,有缺失值时返回TRUE,无缺失值时返回FALSE。
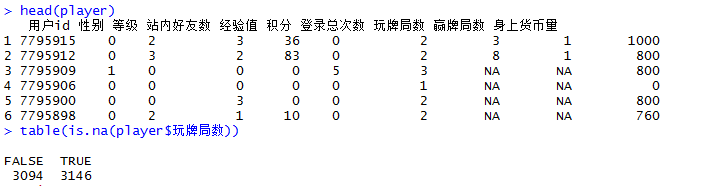
从table的展示中我们就可以看出,在玩牌局数这个标签下,缺失值就占了3146个,未缺失数据占了3094个。
当我们需要查看整体数据的缺失情况时,我们就需要用到另外一个函数md.pattern(),它可以生成一个矩阵或者数据框形式展示的表格。

这里面1表示没有缺失,0表示存在数据缺失。第一列表示符合这种模式的样本有多少个。如第一行第一列的2000就表示符合所有标签都没有缺失的数据有2000个。最后一列的0表示存在缺失的标签个数为0。最后一行表示这一列的数据中,有多少个缺失的数据。如玩牌局数的缺失量为3146,赢牌局数的数据缺失量为4240。
Two:缺失值处理
对缺失值得处理一般有三种方法:删除,替换,赋值
删除缺失样本是最为简单的,但这样做也会破坏数据的完整性,当缺失的数据占总体的比例较低时,删除一部分数据造成的影响也不会太大。当缺失数据占比较高时,则不能用这种方法。这里删除缺失值我们用na.omit()函数即可。
替换则是用均值,众数或其他预定值来直接将缺失的数据替换掉,这样做同样会影响数据的特征性,需要根据具体的业务场景来决定是否进行缺失值替换,以及替换为什么。
对缺失值的处理相对好一些的方式就是赋值了,这种方法通过回归,决策树,随机森林等算法来预测缺失值的最近替代值。
我们手里有一份用户调研的数据,首先我们看一下这些数据的缺失情况,这里我们调用VIM包中的aggr()函数对缺失数据进行可视化的展示。
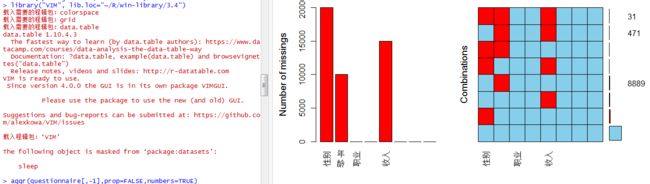
从上面的图中我们可以看出,问卷调研的数据集共有三个字段的数据存在缺失,性别缺失量在20000,年龄缺失量在10000,收入缺失量在15000。下面我们就需要对缺失数据进行预测,这里我们先用logit回归来预测缺失的性别数据。
首先将数据都变为因子型,便于分类:


而对于年龄和收入这里是多因子变量,所以这里可以用决策树或贝叶斯模型对其缺失值进行预测,这里用了随机森林迭代弥补缺失变量。
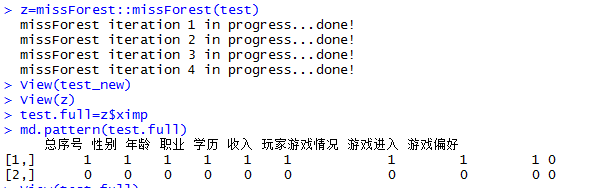
这里的test是所有数据中抽取的前10000条,跟上面一样存在缺失的字段为性别,年龄,收入。当我们用missForest函数进行预测赋值后,我们可以看见所有的缺失值都被填充好了。
2>异常值判断
数据样本中的异常值通常是指一个类别型变量中某个类别的值出现的次数太少,或者指一个区间变量中某些取值太大或者太小。忽视异常值的存在很可能会干扰模型系数的计算和评估,从而严重降低模型的稳定性。而做异常值判断的方法主要有三种:简单的统计分析(数据后台排查),3σ原则,箱线图分析,聚类分析。这里我主要了解3σ原则和聚类分析。
首先是3σ原则:这个简单来说就是大学所学质量管理学里面的质量控制图,通过一个上下界限来筛选产品的合格性。R中qcc包提供了绘制这种质量控制图的功能。

从图中可以看出在画红圈的部分6月5日,6日,9日这三天的七日留存率超过了最低界限,说明这些天可能存在刷量的现象,导致用户质量不高,到第七日时,很多用户都流失了,这个时候就需要引起我们运营方的关注了。
聚类分析:利用聚类分析的方式我其实就是把相近的归为一类,距离同类中心点较远的就是异常值了。
我们可以先看一下我们的数据,数据中各个字段的量纲差异性很大,如果直接用来聚类,会形成很多的离群值,于是我们就先对其进行归一化处理,使其数值映射到[0,1]。
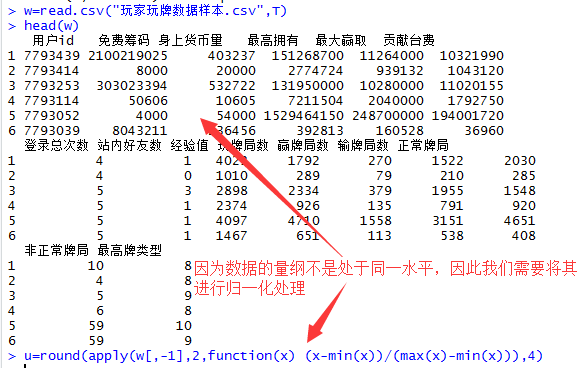
接下来就是利用K-means聚类对u进行分群,并识别出离群值。
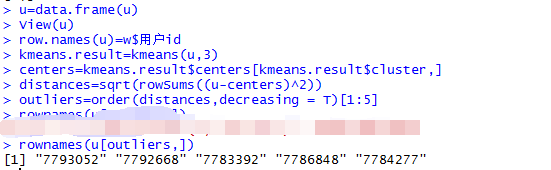
当然这里也可以将这些数据用户在整个数据集中可视化的表现出来,不过我们已经知道了用户id,可视化要不要也就无所谓了。
3>数据的标准化转换
数据的标准化的目的其实就是希望能消除变量之间量纲的影响,将数据按照比例缩放,使之落入一个相同的范围之内,让不同的变量经过标准化处理后可以有平等分析和比较的基础。
常用的有标准化手段有:
Min-Max标准化:
零-均值标准化:
preProcess()函数
4>数据哑变量处理
哑变量也叫作虚拟变量,引入哑变量的目的是不能够定量处理的变量量化。如将因子型变量转换为数值型矩阵。一般所用的package就是caret包,具体的就是用dummyVars()函数进行数据哑变量处理。
三,实战篇——游戏数据分析的常用方法
1.数据趋势分析
1>同比,环比
2>时间序列数据预测
关于时间变量的分析在我们的工作中用到的也会非常的多,比如所用户活跃时段变化,对未来某个时刻的数据的一个预测等等。时间序列分析是一种动态数据处理的统计方法,典型的假设是相邻的观测值之间存在某种依赖性,进而研究随机数据序列遵从的统计规律。
在R中ts()函数可以把一个向量转化为时间序列对象,并且可以用is.ts()来判断一个对象是否为时间序列对象。
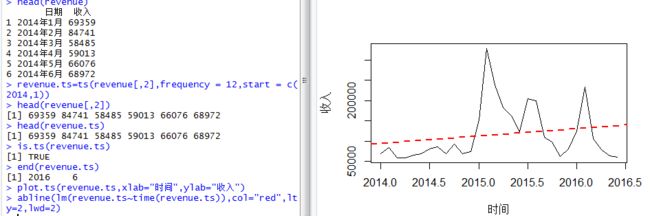
这里所做的一个工作就是将原始数据转化为时间序列,并且用可视化的方式展示出来(图中的黑色线条),而对这样的一个时间序列进行线性拟合之后,我们可以发现拟合线(红色)具有明显的 趋势性,因此,它是不稳定的。
而对于非平稳的时间序列,我们首先就需要先对其进行差分,以得到一个平稳的时间序列。这里我们用到的差分函数为diff(),差分后,我们发现p值远小于0.05,故时间序列为平稳的序列。

下面我们希望对2016年下半年的收入情况进行一个预测,这就用到了我们的HoltWinters()函数对数据进行季节性指数平滑化建立模型。当模型建立好之后,我们要想预测未来的收入情况,就需要用到forecast包中的forecast.HoltWinters()函数。
