前言
本篇文章是汇编这一部分的最终章了,主要讲解4部分内容:
- 编译器优化
- 指针
- OC反汇编
- Block反汇编
一、编译器优化
首先看看编译器的优化,这个其实是XCode编译器自身的优化功能,编译器会自动精简优化汇编代码的逻辑。这个知识点我们知道即可,不需要了解太深。
还是老规矩,举例看看编译器是如何优化的?示例
int global = 10;
int main(int argc, char * argv[]) {
int a = 20;
int b = global + 1;
return UIApplicationMain(argc, argv, nil, NSStringFromClass([AppDelegate class]));
}
Xcode默认不优化的情况下,汇编代码
接着我们改变编译器优化的规则
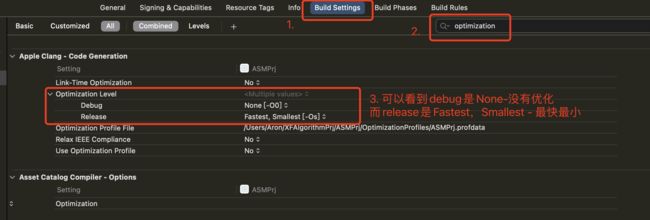
下表是优化配置的说明
| 配置选项 | 说明 | 具体含义 |
|---|---|---|
| None [-O0] | 不优化 | 编译器的目标是降低编译消耗,保证调试时输出期望的结果。程序的语句之间是独立的:如果在程序的停在某一行的断点出,我们可以给任何变量赋新值抑或是将程序计数器指向方法中的任何一个语句,并且能得到一个和源码完全一致的运行结果。 |
| Fast [-O, O1] | 大函数所需的编译时间和内存消耗都会稍微增加 | 在这种设置下,编译器会尝试减小代码文件的大小,减少执行时间,但并不执行需要大量编译时间的优化。在苹果的编译器中,在优化过程中,严格别名,块重排和块间的调度都会被默认禁止掉。此优化级别提供了良好的调试体验,堆栈使用率也提高,并且代码质量优于None[-O0]。 |
| Faster [-O2] | 编译器执行所有不涉及时间空间交换的所有的支持的优化选项 | 更高的性能优化Fast[-O1]。在这种设置下,编译器不会进行循环展开、函数内联或寄存器重命名。和‘Fast[-O1]’项相比,此设置会增加编译时间和生成代码的性能。 |
| Fastest [-O3] | 在开启Fast[-O1]项支持的所有优化项的同时,开启函数内联和寄存器重命名选项 | 是更高的性能优化Faster[-O2],指示编译器优化所生成代码的性能,而忽略所生成代码的大小,有可能会导致二进制文件变大。还会降低调试体验。 |
| Fastest, Smallest [-Os] | 在不显着增加代码大小的情况下尽量提供高性能 | 这个设置开启了Fast[-O1]项中的所有不增加代码大小的优化选项,并会进一步的执行可以减小代码大小的优化。增加的代码大小小于Fastest[-O3]。与Fast[-O1]相比,它还会降低调试体验。 |
| Fastest, Aggressive Optimizations [-Ofast] | 与Fastest, Smallest[-Os]相比该级别还执行其他更激进的优化 | 这个设置开启了Fastest[-O3]中的所有优化选项,同时也开启了可能会打破严格编译标准的积极优化,但并不会影响运行良好的代码。该级别会降低调试体验,并可能导致代码大小增加。 |
| Smallest, Aggressive Size Optimizations [-Oz] | 不使用LTO的情况下减小代码大小 | 与-Os相似,指示编译器仅针对代码大小进行优化,而忽略性能优化,这可能会导致代码变慢。 |
使用标准
简而言之的使用标准

二、指针
接下来我们看看指针,它在汇编中是如何进行读写的?我们都知道,指针指向的是地址,我们先来看看指针相关的基础点
2.1指针基础
2.1.1 指针的宽度
指针的宽度(Swift中也可称步长)为8字节,即指针在内存中所占的大小为8字节。例如下面的示例打印
void function() {
//指针的宽度8字节
int *a;
printf("%lu",sizeof(a));
}
int main(int argc, char * argv[]) {
function();
return UIApplicationMain(argc, argv, nil, NSStringFromClass([AppDelegate class]));
}
查看function()的汇编

上图可知,sizeof操作符得到的结果在汇编中,是常量0x8,十进制即8。
2.1.2指针的运算
指针++
- int*++
int *a;
a = (int *)100;
a++;
结果 104,因为int占4字节,所以指针+1每次平移4个字节。
- char*++
char *a;
a = (char *)100;
a++;
结果 101,跟上面一个道理,char只占1个字节。
- 二级指针++:
int **a;
a = (int **)100;
a++;
结果 108,a是个2级指针,即指向指针的指针,可以看作是int * (*a),而int *是指针类型占8字节,所以a++平移就是+8,即108。
指针+
int **a;
a = (int **)100;
a = a + 1;
很显然,a是个二级指针,指向的是int*类型(指针类型),那么+1当然就是平移+8了,结果即108。
⚠️注意:
a = a + 1等价于a++。
++(自增)、 --(自减)这两个运算符是与编译器有关的。
指针-
int *a;
a = (int *)100;
int *b;
b = (int *)200;
int x = a - b;
x的结果 -25,why?
- 指针的运算与指向的
数据类型宽度(步长)有关 - 指针的
运算单位是执行的数据类型的宽度 -
结构体和基本类型不能强制转换,普通类型可以通过&
基于上面3点原则,那么a = 100/4 = 25, b = 200/4 = 50,所以x = a-b = 25-50 = -25。
2.2指针的反汇编
请看下面示例
void func() {
int* a;
int b = 10;
a = &b;
}
汇编

[sp, #0x8]其实是个指针,内存中从0x8~0x10保存的就是指针。
数组和指针
最后,我们看看一种常见的场景 数组和指针的示例
void function() {
int arr[5] = {1,2,3,4,5};
//int *a == &arr[0] == arr
int *a = arr;
for (int i = 0; i < 5; i++) {
printf("%d\n",arr[i]);
printf("%d\n",*(arr + i));
printf("%d\n",*(arr++));
printf("%d\n",*(a++));
}
}

很明显,*(arr++) 会报错。int *a = arr;之后a++这样就不会报错。
数组名和指针变量名是一样的,唯一的区别是一个是常量,一个是变量。
所以,int *a == &arr[0] == arr。
2.3 指针的基本用法
大家请看下面这个示例,会有什么问题?
void function() {
char *p1;
char c = *p1;
printf("%c",c);
}
汇编

p1指针没有初始化,编译时不会报错,但是运行会报错。因为在iOS中,指针p1未初始化,那么系统默认取值0,运行就会直接野指针报错。
指向char的指针+0
再看这个示例
void func() {
char *p1;
char c = *p1;
char d = *(p1 + 0);
}
汇编
ASMPrj`func:
0x104b661bc <+0>: sub sp, sp, #0x10 ; =0x10
//p1 -> 0x0 x8指向p1
0x104b661c0 <+4>: ldr x8, [sp, #0x8]
//c = [x8] 给到 w9
-> 0x104b661c4 <+8>: ldrb w9, [x8]
0x104b661c8 <+12>: strb w9, [sp, #0x7]
0x104b661cc <+16>: ldr x8, [sp, #0x8]
//d = [x8] 给到 w9
0x104b661d0 <+20>: ldrb w9, [x8]
0x104b661d4 <+24>: strb w9, [sp, #0x6]
0x104b661d8 <+28>: add sp, sp, #0x10 ; =0x10
0x104b661dc <+32>: ret
从上面的汇编代码中可以看出,每次ldr x8, [sp, #0x8],sp指向栈顶地址,从栈顶平移0x8(十进制是8)字节后,存入x8,接着ldrb w9, [x8],将x8地址中的值存入w9,所以,可以看出,c和d的值是相同的。
指向char的指针+1
改变下代码,我们+1
void func() {
char *p1;
char c = *p1;
char d = *(p1 + 1);
}
汇编
ASMPrj`func:
0x1041f21bc <+0>: sub sp, sp, #0x10 ; =0x10
//p1
0x1041f21c0 <+4>: ldr x8, [sp, #0x8]
//c
-> 0x1041f21c4 <+8>: ldrb w9, [x8]
0x1041f21c8 <+12>: strb w9, [sp, #0x7]
0x1041f21cc <+16>: ldr x8, [sp, #0x8]
//d
0x1041f21d0 <+20>: ldrb w9, [x8, #0x1]
0x1041f21d4 <+24>: strb w9, [sp, #0x6]
0x1041f21d8 <+28>: add sp, sp, #0x10 ; =0x10
0x1041f21dc <+32>: ret
d的那行,变成了ldrb w9, [x8, #0x1],0x1就是十进制1,因为char类型占1个字节大小,所以d相对于c而言,平移了1个字节。
指向int的指针+1
接着我们把char类型改成int类型
void func() {
int *p1;
int c = *p1;
int d = *(p1 + 1);
}
ASMPrj`func:
0x1040e61bc <+0>: sub sp, sp, #0x10 ; =0x10
//p1 [x8]
0x1040e61c0 <+4>: ldr x8, [sp, #0x8]
//c
-> 0x1040e61c4 <+8>: ldr w9, [x8]
0x1040e61c8 <+12>: str w9, [sp, #0x4]
0x1040e61cc <+16>: ldr x8, [sp, #0x8]
//d
0x1040e61d0 <+20>: ldr w9, [x8, #0x4]
0x1040e61d4 <+24>: str w9, [sp]
0x1040e61d8 <+28>: add sp, sp, #0x10 ; =0x10
0x1040e61dc <+32>: ret
因为char类型占1个字节,而int类型占4字节,变成了ldr w9, [x8, #0x4],其中0x4所对应的十进制就是4,所以d相对于c而言,地址平移了4个字节。
指向int的指针的指针+1
继续升级难度
void func() {
int **p1;
int *c = *p1;
int *d = *(p1 + 1);
}
ASMPrj`func:
0x1041821b8 <+0>: sub sp, sp, #0x20 ; =0x20
//p1 [x8]
0x1041821bc <+4>: ldr x8, [sp, #0x18]
//c
-> 0x1041821c0 <+8>: ldr x8, [x8]
0x1041821c4 <+12>: str x8, [sp, #0x10]
0x1041821c8 <+16>: ldr x8, [sp, #0x18]
//d
0x1041821cc <+20>: ldr x8, [x8, #0x8]
0x1041821d0 <+24>: str x8, [sp, #0x8]
0x1041821d4 <+28>: add sp, sp, #0x20 ; =0x20
0x1041821d8 <+32>: ret
d变成了ldr x8, [x8, #0x8],变成了0x8,why? 前面我们分析过,p1是个2级指针,本身就是指针,指针占8字节大小,所以p1 + 1 按照p1类型的宽度平移,当然平移8字节大小。
⚠️注意:这里栈空间拉伸了
#0x20,涉及了指针的指针,至少需要16字节,而要保持16字节对齐,至少拉伸32字节,所以是#0x20。
指向指针的指针
按照之前的指针运算的实例,当然最后就是指针的指针了
void func() {
char **p1;
char c = **p1;
}
ASMPrj`func:
0x102cf61c4 <+0>: sub sp, sp, #0x10 ; =0x10
//初始值
0x102cf61c8 <+4>: ldr x8, [sp, #0x8]
//两次ldr,二级指针在寻址
-> 0x102cf61cc <+8>: ldr x8, [x8]
0x102cf61d0 <+12>: ldrb w9, [x8]
0x102cf61d4 <+16>: strb w9, [sp, #0x7]
0x102cf61d8 <+20>: add sp, sp, #0x10 ; =0x10
0x102cf61dc <+24>: ret
由上可知,两次ldr,说明是二级指针在寻址。
指针的指针&指针混合偏移
最后一个
void func() {
char **p1;
char c = *(*(p1 + 2) + 2);
}
运行会不会有问题?请看
上面我们分析过报错的原因。先不看报错,我们注意到char c = *(*(p1 + 2) + 2)对应的汇编是
ldr x8, [x8, #0x10]
ldrp w9,[x8, #0x2]
说明 p1 偏移 (2 * 8(指针宽度)) +(2 * 1(char宽度)),同样的道理,下面的例子呢?
void func() {
char **p1;
char c = *(*(p1 + 2) + 2);
char c2 = p1[1][2];
}
c知道了平移多少了,那c2呢?留给大家自行分析!
⚠️提示:
p1[1][2]等价于*(*(p1 + 1) + 2)
三、OC反汇编
接下来看看第三个点 OC反汇编,老规矩,上示例代码
//LGPerson.h
@interface LGPerson : NSObject
@property (nonatomic, copy) NSString *name;
@property (nonatomic, assign) int age;
+ (instancetype)person;
@end
//LGPerson.m
#import "LGPerson.h"
@implementation LGPerson
+ (instancetype)person {
return [[self alloc] init];
}
@end
在main.m中调用
#import "LGPerson.h"
int main(int argc, char * argv[]) {
LGPerson *person = [LGPerson person];
return 0;
}
接着看汇编

我们都知道,objc_msgSend默认有两个参数self 和 cmd,分别是id和SEL类型。接着我们根据汇编的地址来验证下
-
0x1006ea000 <+24>: adrp x8, 3执行完这句,3左移3位->0x300,加上x8的地址0x1006ea000->0x1006ed000 -
add x8, x8, #0x6a0执行完这句,x8地址是0x1006ed6a0 - 接着查看
0x1006ed6a0的值,读取前8位(第一个入参id类型,是个指针占8位)

果然是LGPerson,因为是[LGPerson person]是类方法,所以第一个入参是LGPerson,同理,接着看第2个入参SEL

果然是方法名称person。以下是lldb查看的指令代码(大家可以自行手动调试验证一遍)
(lldb) x 0x1006ed6a0
0x1006ed6a0: 90 d7 6e 00 01 00 00 00 40 d7 6e 00 01 00 00 00 [email protected].....
0x1006ed6b0: c8 d6 6e 00 01 00 00 00 08 00 00 00 08 00 00 00 ..n.............
(lldb) po 0x01006ed790
LGPerson
(lldb) x 0x1006ed670
0x1006ed670: fc cb 9c 64 02 00 00 00 da d8 8c 64 02 00 00 00 ...d.......d....
0x1006ed680: 40 91 fb 70 02 00 00 00 50 40 fb 70 02 00 00 00 @[email protected]....
(lldb) po 0x02649ccbfc
10277932028
(lldb) po (SEL)0x02649ccbfc
"person"
继续,我们进入person方法里面,汇编
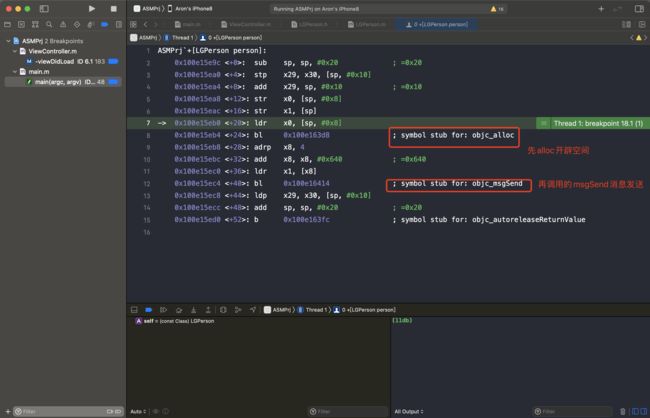
上图可知,先走objc_alloc,再走的objc_msgSend方法
⚠️:这块和支持的
最低版本有关。
iOS9为objc_msgSend和objc_msgSend对应alloc和init。iOS11为objc_alloc和objc_msgSend,这里优化了alloc直接调用了objc_alloc,没有调用objc_msgSend。iOS13为objc_alloc_init,这里同时优化了alloc和init。
接下来,我们看看[LGPerson person]的返回值相关汇编

objc_storeStrong
断点继续执行

上图我们注意到objc_storeStrong函数(在OC中用strong修饰符就会调用这个函数),objc_storeStrong调用后如果被外部引用引用计数+1,否则就销毁。
在objc4-818.2源码中objc_storeStrong源码(在NSObject.mm中)
void
objc_storeStrong(id *location, id obj)
{
id prev = *location;
if (obj == prev) {
return;
}
objc_retain(obj);
*location = obj;
objc_release(prev);
}
这个函数有两个参数 id* 和 id,函数的目的为对strong修饰的对象retain + 1,对旧对象release。
接着对LGPerson示例的汇编代码分析,我们在ViewDidLoad中调用
- (void)viewDidLoad {
[super viewDidLoad];
LGPerson *person = [LGPerson person];
}
这样汇编代码比main中简单许多
上图红框处的代码就是对objc_storeStrong的调用
// x8指向 sp + 0x8 地址
0x100f99a8c <+104>: add x8, sp, #0x8 ; =0x8
// x0中存储的就是sp + 0x8 地址,所以x8 就是指向x0的地址
0x100f99a90 <+108>: str x0, [sp, #0x8]
0x100f99a94 <+112>: mov x0, x8
// 这里将x8中的值清零
0x100f99a98 <+116>: mov x8, #0x0
// 再保存到x1中
0x100f99a9c <+120>: mov x1, x8
//objc_storeStrong 第一个参数就是x0,值是&person,第二个参数是x1,值是0x0
0x100f99aa0 <+124>: bl 0x100f9a450 ; symbol stub for: objc_storeStrong
通过对上述汇编代码的分析,调用objc_storeStrong的过程就相当于
//分别传入 &person 和 0x0
void objc_storeStrong(id *location, id obj)
{
id prev = *location;//id prev = *person
if (obj == prev) {
return;
}
objc_retain(obj);// nil
*location = obj;// location 指向第二个入参obj,即nil
objc_release(prev);//释放老对象 release person, 释放堆空间
}
所以这里objc_storeStrong调用为了释放对象。
工具反汇编
由于大部分情况下OC代码都比较复杂,自己分析起来比较麻烦。我们一般都借助工具来协助反汇编,一般会用到MachoView,Hopper,IDA。
将刚才的代码稍作修改
#import "LGPerson.h"
int main(int argc, char * argv[]) {
LGPerson *person = [LGPerson person];
person.name = @"cat";
person.age = 1;
return 0;
}
通过hopper打开macho文件
可以看到Hopper已经自动解析出了方法名和参数,那么编译器是怎么做到呢?
双击 objc_cls_ref_LGPerson会跳转到对应的地址
再去MachoView中查找对应的地址00000001000096b0

同理,查看setName setAge

对应在machoView的值
可以看到所有方法都在这块。
所以在分析汇编代码的时候就能根据地址找到这些字符串,这就是能还原的原因,所谓的反编译。
四、Block反汇编
最后我们来看看Block反汇编。示例
int main(int argc, char * argv[]) {
void(^block)(void) = ^() {
NSLog(@"block test");
};
block();
return 0;
}
查看汇编

block的实现就是invoke,地址是0x102c4e160。
block源码定义如下(Block_private.h)
struct Block_layout {
void *isa; //8字节
volatile int32_t flags; // contains ref count //4字节
int32_t reserved;//4字节
BlockInvokeFunction invoke;
struct Block_descriptor_1 *descriptor;
// imported variables
};
那么isa平移16字节就是invoke,我们可以通过lldb指令查看

接着我们看看在hopper中


再双击0x00000001000060cc跳转到invoke实现

StackBlock
上面的例子是GlobalBlock全局block,现在我们看看StackBlock栈block
int main(int argc, char * argv[]) {
int a = 10;
void(^block)(void) = ^() {
NSLog(@"block test:%d",a);
};
block();
return 0;
}
汇编

lldb查看isa和invoke
(lldb) po 0x100a8c000
<__NSStackBlock__: 0x100a8c000>
signature: ""
(lldb) x 0x100a8c000
0x100a8c000: 30 88 ae df 01 00 00 00 94 3f c5 89 01 00 00 00 0........?......
0x100a8c010: 00 00 00 00 00 00 00 00 24 00 00 00 00 00 00 00 ........$.......
(lldb) po 0x01dfae8830
__NSStackBlock__
(lldb) dis -s 0x100a8a140
TestOC&BlockASM`__main_block_invoke:
0x100a8a140 <+0>: sub sp, sp, #0x30 ; =0x30
0x100a8a144 <+4>: stp x29, x30, [sp, #0x20]
0x100a8a148 <+8>: add x29, sp, #0x20 ; =0x20
0x100a8a14c <+12>: stur x0, [x29, #-0x8]
0x100a8a150 <+16>: str x0, [sp, #0x10]
0x100a8a154 <+20>: ldr w8, [x0, #0x20]
0x100a8a158 <+24>: mov x0, x8
0x100a8a15c <+28>: adrp x9, 2
invoke的imp实现通过dis -s查看汇编实现。
在hopper中

再看block的实现

与全局block不同的是:
-
global block的block和descriptor是在一起的 -
stack block并不在一起
总结
- 编译器优化
-
Debug模式下是None [-O0] -
Release模式下是Fastest, Smallest [-Os]
-
- 指针
- 指针的
宽度(也可称步长)为8字节 - 指针的运算
- 指针的运算与指向的
数据类型宽度(步长)有关-
++自增--自减,是根据指针修饰的变量类型的宽度决定的 - 2级指针
+1就是按照指针的宽度(8字节)
-
- 指针的
运算单位是执行的数据类型的宽度 -
结构体和基本类型不能强制转换,普通类型可以通过&
- 指针的运算与指向的
- 指针的反汇编
- 指针在内存中占8字节大小,例如
[sp, #0x8]其实是个指针,内存中从0x8~0x10保存指针 -
数组名和指针变量名是一样的,唯一的区别是一个是常量,一个是变量。 - 指针的基本用法
-
指针+0 +1都是根据指针指向的变量类型的宽度决定的 -
二级指针,汇编中会执行两次ldr->寻址2次
-
- 指针在内存中占8字节大小,例如
- 指针的
- OC反汇编
-
objc_msgSend默认有两个参数self和cmd,分别存储在x0和x1寄存器中 -
alloc & init和当前App所支持的最低版本有关-
iOS9为objc_msgSend和objc_msgSend对应alloc和init -
iOS11为objc_alloc和objc_msgSend,这里优化了alloc直接调用了objc_alloc,没有调用objc_msgSend -
iOS13为objc_alloc_init,这里同时优化了alloc和init
-
-
objc_storeStrong- 有两个参数
id*和id - 目的为对strong修饰的对象
retain + 1,对旧对象release
- 有两个参数
-
- Block反汇编
- block在底层是结构体
Block_layout -
Block_layout的第一个成员是isa指针,通过平移16字节可得到成员invoke,即block的实现imp-
imp实现可通过lldb指令dis -s查看汇编实现
-
-
GlobalBlock和StackBlock的区别-
global block的block和descriptor是在一起的 -
stack block并不在一起
-
- block在底层是结构体