title: [Extracting PDF Text with R and Creating Tidy Data]
author: 富士山下裸奔
date: 2018.4.10.

前言:
在当今的数字时代,数据有多种形式。许多常见的文件类型,如CSV、XLSX和纯文本(TXT)都很容易访问和管理。然而,有时候,我们需要的数据被锁定在文件格式中,这种格式不太容易访问,比如PDF。如果你发现自己处于这种困境,不要担心——pdftools包帮你解决难题。
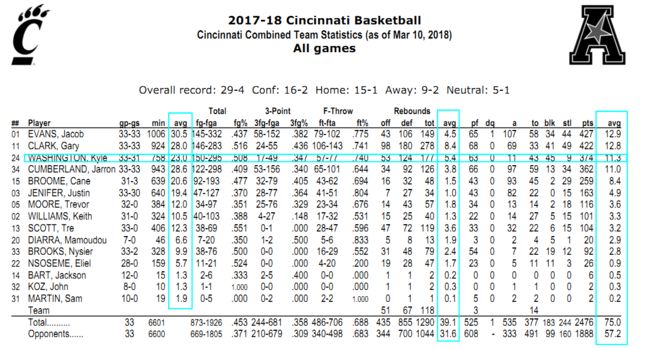
在这篇文章中,您将学习如何:使用pdftools从PDF中提取文本,使用stringr包来操作字符串的文本,并创建一个整洁的数据集。数据来源来自加州大学男子篮球队的统计数据。
最后,我将会创建一个显示赛季统计数据的tibble,包括每个球员的上场时间、投篮命中率、总得分和平均每场得分。
step 1
是加载所需的R包。stringr 包是R包的tidyverse集合中的一个成员中的一个,其中的软件包旨在使数据科学变得容易。我强烈推荐Hadley Wickham和Garrett Grolemund编写的R for Data Science。对于初学者来说,这是一本很棒的书,对于更高级的程序员来说,这也是一个口袋参考。
library(pdftools)
library(tidyverse)
step 2
下一步将使用pdf_text命令来读取文件的文本,创建新对象UC_text, read_lines()函数读取文件的行。
UC_text <- pdf_text("./data/UC_stats.pdf") %>%
readr::read_lines()
head(UC_text)
把重点放在球员的赛季统计上,这是我们文件的第6行到第24行。第6行包含我们生成的数据的列名,将数据框命名为season_stats。
season_stats <- UC_text[6:24]
head(season_stats)
step 3
在接下来的一系列步骤中,将使用 stringr·包中的函数来将文本行转换成一个理想的形式。处理的第一个问题是每一行文本中不同元素之间的空白。str_squish()函数的作用是:减少每个字符串之间的重复空格。还需要删除每个玩家的名字和名字之间的逗号。将使用str_replace_all()来删除逗号。
str_squish()同str_trim().用法如下:
str_trim()removes whitespace from start and end of string
str_squish()also reduces repeated whitespace inside a string
str_trim(" String\t") #String
str_squish("\n\nString with\n\n") #String with
在删除了空格和逗号之后,我可以把重点放在分离每个元素上。我将使用strsplt()将每个字符串的元素拆分为子字符串。
all_stats_lines <- season_stats[1:16] %>%
str_squish() %>%
str_replace_all(",", "") %>%
strsplit(split = " ")
head(all_stats_lines)
all_stats_lines对象的结构是一个列表。现在关注第一个元素,它将是数据框的列名。这里有两个问题:1.有三个元素被命名为“avg”2.)只有一个元素被命名为Player,但是每个玩家的名字都被分成两列(我稍后会修正)。现在,我将重点讨论更改列名。我将使用unlist()将第一个元素和转换列表设置为一个字符向量。一旦我将它们转换回字符向量,可以很容易地将新值赋给我们的列名。
var_lines <- all_stats_lines[1] %>%
unlist()
var_lines
var_lines的第5个、第15个和第23个元素都被命名为avg。根据矢量(和一些篮球技术)的前面元素,我们可以推断出这些元素分别代表平均上场时间、平均篮板数和平均得分。我将重命名这些元素,' avg_min ', ' avg_min ', ' avg_pts '
var_lines[c(5, 15, 23)] <- c("avg_min", "avg_reb", "avg_pts")
str(var_lines)
var_lines
step 4
下一个主要障碍是将球员统计数据转换成一个数据框。我将在plyr 包中使用ldply()函数,该函数将一个函数应用于列表中的每个元素,并将结果合并到一个数据框中。
stats_lines <- all_stats_lines[2:16]
head(stats_lines)
现在是时候回到玩家名字的问题上来了。请记住,列名称的数量与篮球统计数据的列不一致,因为在stats_df对象中每个参与者的名称都是由两个列(“V1”和“V2”)分隔的。
为了将这些列与每个参与者的名字和名字组合起来,将使用unite()函数
Unite multiple columns into one.
`Description`
Convenience function to paste together multiple columns into one.
Usage
unite(data, col, ..., sep = "_", remove = TRUE)
stats_df <- plyr::ldply(stats_lines) %>%
unite(v2v2, V2, V3, sep = ",")
head(stats_df)
colnames(stats_df) <- var_lines
head(stats_df)
现在我们的列终于对齐了,我终于可以组装最终的数据框架了。第一步是使用colnames()附加列名。我想把我最后的数据帧转换成一个小块。有很多理由可以让你的生活成为一个数据科学家的生活。其中之一就是tibbles容易处理non-syntactic 变量。为了引用non-syntactic变量,它们必须在backticks中被包围。
Find_DF <- as.tibble(stats_df) %>%
select("##", Player, min,"fg%", pts, avg_pts)
head(Find_DF)
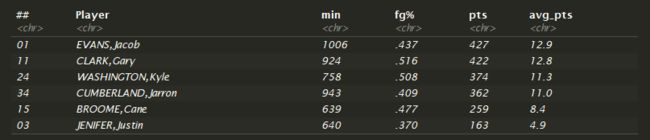
现在有了一个干净整洁的最终数据集,可以进行分析、可视化或导出。
参考文献:
https://www.r-bloggers.com/extracting-pdf-text-with-r-and-creating-tidy-data/