思考:来自运来大佬的笔记(现在走的路都是大佬为我们铺好的路,要学会珍惜!)
- 如何将空间数据与表达数据关联在一起?
- 有了空间转录组数据,如何与单细胞转录组数据联用?
- 做了多层切片如何展示真实的三维空间的转录本信息?
本教程演示了如何使用Seurat(>=3.2)来分析空间解析的RNA-seq数据。虽然分析流程类似于用于单细胞RNA-seq分析的Seurat工作流,但我们引入了更新的交互和可视化工具,特别强调空间和分子信息的集成。本教程将涵盖以下任务,我们相信这将是常见的许多空间分析:
- 归一化
- 降维和聚类
- 检测spatially-variable特性
- 交互式可视化
- 与单细胞RNA-seq数据集成
- 处理多个切片
对于我们的第一个教程,我们分析了与Visium技术从10x基因组产生的一个数据集。在不久的将来,我们将扩展Seurat以处理更多的数据类型,包括 SLIDE-Seq, STARmap, 和MERFISH.
1.加载包
library(Seurat)
library(SeuratData)
library(ggplot2)
library(patchwork)
library(dplyr)
2.数据集
在这里,我们将使用最近发布的使用Visium v1化学试剂生成的数据集矢状面小鼠脑切片。有两个连续的前部和两个(匹配的)连续的后部。
您可以从这里下载数据,并使用Load10X_Spatial函数将其加载到Seurat。这将读入spaceranger流程的输出,并返回一个Seurat对象,该对象包含位置级表达式数据以及组织切片的关联图像。您还可以使用我们的SeuratData包来方便地进行数据访问,如下所示。安装数据集之后,您可以输入?stxBrain以了解更多信息
InstallData("stxBrain")
brain <- LoadData("stxBrain", type = "anterior1")
brain
An object of class Seurat
31053 features across 2696 samples within 1 assay
Active assay: Spatial (31053 features, 0 variable features)
brain@assays$Spatial[1:4,1:4]
AAACAAGTATCTCCCA-1 AAACACCAATAACTGC-1 AAACAGAGCGACTCCT-1 AAACAGCTTTCAGAAG-1
Xkr4 . . . .
Gm1992 . . . .
Gm37381 . . . .
Rp1 . . . .
数据包含了31053个基因,2696个spot
来自10x的visium数据包括以下数据类型,数据存储结构如下:
- 一个点基因表达矩阵:每一行为一个基因,每一列为一个spot,每个spot可能包含多个细胞。
- 组织切片图像(数据采集时通过H&E染色获得)
- 将原始高分辨率图像与此处用于可视化的低分辨率图像关联的缩放因子。
在这里spot表达矩阵是需要重点理解的:
在Seurat实验对象中,spot基因表达矩阵类似于典型的“RNA”实验,但包含了spot水平,而不是单细胞水平的数据。映像本身存储在Seurat对象中的一个新的映像槽中。图像插槽还存储了必要的信息,以关联的位置与其在组织图像上的物理位置。
3.数据预处理
spot水平的基因表达数据的初始预处理步骤与典型的scRNA-seq实验相似。我们首先需要对数据进行归一化,以解释数据点间序列深度的差异。我们注意到,分子counts/spot的差异对于空间数据集来说是实质性的,特别是当组织中的细胞密度存在差异时。我们在这里看到了大量的异质性,这需要有效的规范化。
plot1 <- VlnPlot(brain, features = "nCount_Spatial", pt.size = 0.1) + NoLegend()
plot2 <- SpatialFeaturePlot(brain, features = "nCount_Spatial") + theme(legend.position = "right")
wrap_plots(plot1, plot2)

这些图表明,不同spot的分子计数的差异不仅是技术上的,而且还取决于组织解剖学。例如,神经元减少的组织区域(如皮质白质cortical white matter),重复地表现出较低的分子计数。因此,标准方法(如LogNormalize函数)在标准化后强制每个数据点具有相同的底层“大小”,这可能会带来问题。
作为一种替代方法,我们建议使用sctransform (Hafemeister和Satija, Genome Biology 2019),该方法构建正则化的负二项基因表达模型,以解释技术人工产物,同时保留生物方差。有关sctransform的更多细节,请参见这里的论文和这里的Seurat教程。sctransform对数据进行规范化,检测高方差特征,并将数据存储在SCT assay中。
brain <- SCTransform(brain, assay = "Spatial", verbose = FALSE)
注意这里有一个默认参数:variable.features.n = 3000,选择的是3000个基因。
SCTransform与LogNormalize两种标化方法相比:
为了探究归一化方法的差异,我们研究了sctransform和log归一化结果如何与UMIs的数量相关联。为了进行比较,我们首先重新运行sctransform来存储所有基因的值,并通过NormalizeData运行LogNormalize过程。
# rerun normalization to store sctransform residuals for all genes
brain <- SCTransform(brain, assay = "Spatial", return.only.var.genes = FALSE, verbose = FALSE)
# also run standard log normalization for comparison
brain <- NormalizeData(brain, verbose = FALSE, assay = "Spatial")
# Computes the correlation of the log normalized data and sctransform residuals with the number
# of UMIs
brain <- GroupCorrelation(brain, group.assay = "Spatial", assay = "Spatial", slot = "data", do.plot = FALSE)
brain <- GroupCorrelation(brain, group.assay = "Spatial", assay = "SCT", slot = "scale.data", do.plot = FALSE)
p1 <- GroupCorrelationPlot(brain, assay = "Spatial", cor = "nCount_Spatial_cor") + ggtitle("Log Normalization") +
theme(plot.title = element_text(hjust = 0.5))
p2 <- GroupCorrelationPlot(brain, assay = "SCT", cor = "nCount_Spatial_cor") + ggtitle("SCTransform Normalization") +
theme(plot.title = element_text(hjust = 0.5))
p1 + p2
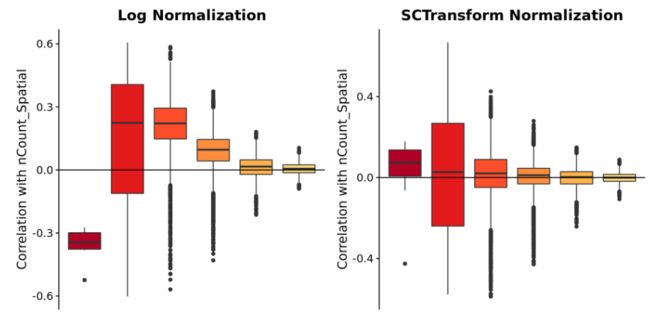
对于上面的箱线图,我们计算每个特征(基因)与UMIs(这里的nCount_Spatial变量)数量的相关性。然后,我们根据基因的平均表达水平将其分组,并生成这些相关性的箱线图。你可以看到,在前三组LogNormalize未能充分正常化基因,这表明技术因素继续影响标准化表达估计高表达基因。相反,sctransform标准化实质上减轻了这种影响。
4.基因表达的可视化
在Seurat v3.2中,我们添加了一些新功能,用于探索空间数据固有的视觉特性并与之交互。Seurat的空间特征图功能扩展了特征图,可以将分子数据覆盖在组织组织学上。例如,在这组小鼠大脑的数据中,Hpca基因是一个强大的海马标记,而Ttr是脉络膜丛的标记。
SpatialFeaturePlot(brain, features = c("Hpca", "Ttr"))
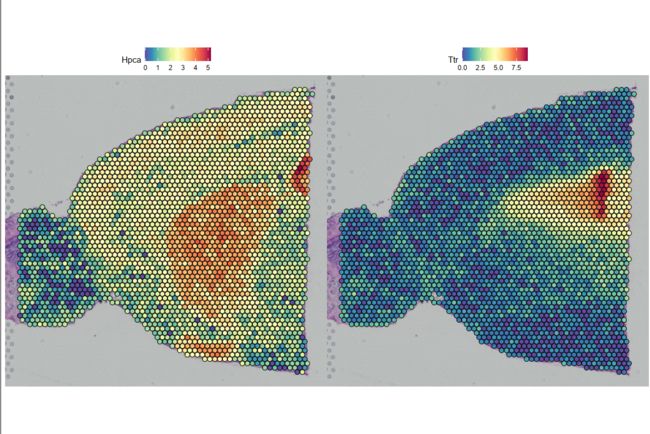
Seurat的默认参数强调分子数据的可视化。但是,也可以通过更改以下参数来调整斑点的大小(及其透明度),以提高组织学图像的可视化:
- pt.size:因子-这将缩放斑点的大小。默认是1.6
- alpha:最小和最大透明度。默认为c(1,1)
尝试设置为alpha c(0.1, 1),来降低表达式较低的点的透明度
p1 <- SpatialFeaturePlot(brain, features = "Ttr", pt.size.factor = 1)
p2 <- SpatialFeaturePlot(brain, features = "Ttr", alpha = c(0.1, 1))
p1 + p2
5.降维、聚类和可视化
然后,我们可以继续对RNA表达数据进行降维和聚类,使用与我们用于scRNA-seq分析相同的工作流程。
brain <- RunPCA(brain, assay = "SCT", verbose = FALSE)
brain <- FindNeighbors(brain, reduction = "pca", dims = 1:30)
brain <- FindClusters(brain, verbose = FALSE)
brain <- RunUMAP(brain, reduction = "pca", dims = 1:30)
然后,我们可以在UMAP空间(使用DimPlot)或在图像上使用SpatialDimPlot叠加显示聚类结果
p1 <- DimPlot(brain, reduction = "umap", label = TRUE)
p2 <- SpatialDimPlot(brain, label = TRUE, label.size = 3)
p1 + p2
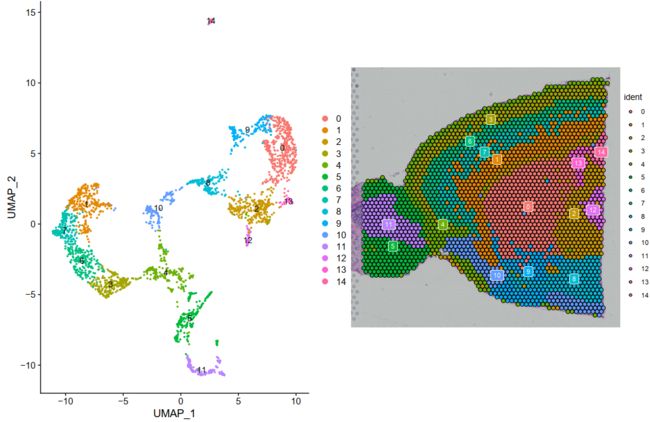
由于有许多颜色,它可能是具有挑战性的可视化哪个体素属于哪个cluster。我们有一些策略来帮助解决这个问题。设置label参数会在每个集群的中间位置放置一个彩色框(见上面的图)。
您还可以使用cells.highlight参数来标定空间图上感兴趣的特定单元格。这对于区分单个集群的空间定位非常有用,如下所示:
SpatialDimPlot(brain, cells.highlight = CellsByIdentities(object = brain, idents = c(2, 1, 4, 3, 5, 8)), facet.highlight = TRUE, ncol = 3)
6.识别空间变量特征
Seurat提供了两个工作流程来识别组织内与空间位置相关的分子特征。第一种是基于组织内预先注释的解剖区域来进行差异表达,这可以通过无监督聚类或先验知识来确定。在这种情况下,这个策略是有效的,因为上面的cluster有明确的空间限制。
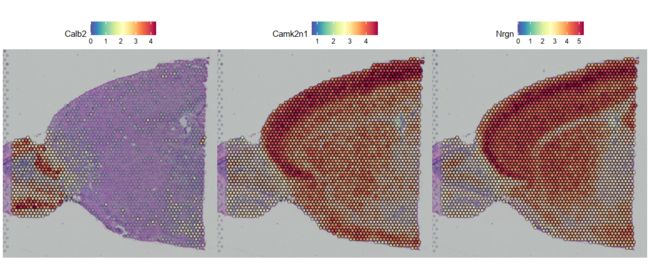
de_markers <- FindMarkers(brain, ident.1 = 5, ident.2 = 6)
SpatialFeaturePlot(object = brain, features = rownames(de_markers)[1:3], alpha = c(0.1, 1), ncol = 3)
在FindSpatiallyVariables中实现的另一种方法是在没有预先注释的情况下搜索显示空间模式的特性。默认的方法(method = 'markvariogram ')受到 Trendsceek的启发,后者将空间转录组数据建模为一个标记点过程,并计算一个'variogram',它识别基因的表达水平取决于它们的空间位置。更具体地说,这个过程计算gamma(r)值,测量的是距离为一定“r”的两点之间的依赖关系。默认情况下,我们在这些分析中使用的r值为“5”,并且仅为可变基因计算这些值(其中变异的计算独立于空间位置)以节省时间。
我们注意到在文献中有多种方法来完成这项任务,包括空间法SpatialDE和斑点法Splotch。我们鼓励有兴趣的用户探索这些方法,并希望在不久的将来增加对它们的支持。
brain <- FindSpatiallyVariableFeatures(brain, assay = "SCT", features = VariableFeatures(brain)[1:1000], selection.method = "markvariogram")
现在我们将通过这种方法确定的前6个特征的表达形象化
top.features <- head(SpatiallyVariableFeatures(brain, selection.method ="markvariogram"), 6)
SpatialFeaturePlot(brain, features = top.features, ncol = 3, alpha = c(0.1, 1))
7.划分解剖区域
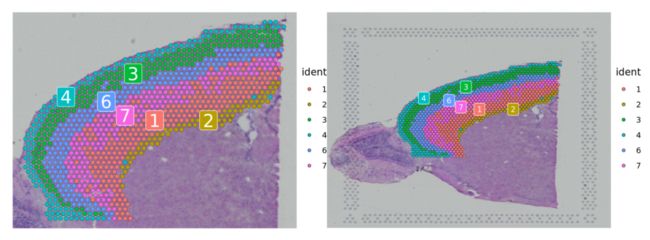
与单细胞对象一样,可以对对象进行子集化,以集中于数据的子集。这里,我们大致划分了额叶皮层。这个过程还将在下一节中促进这些数据与皮质scRNA-seq数据集的集成。首先选取cluster的子集,然后根据具体位置进一步细分。经过亚设置,我们可以在完整的图像或裁剪的图像上看到皮质细胞。
cortex <- subset(brain, idents = c(1, 2, 3, 4, 6, 7))
# now remove additional cells, use SpatialDimPlots to visualize what to remove
# SpatialDimPlot(cortex,cells.highlight = WhichCells(cortex, expression = image_imagerow > 400 |
# image_imagecol < 150))
cortex <- subset(cortex, anterior1_imagerow > 400 | anterior1_imagecol < 150, invert = TRUE)
cortex <- subset(cortex, anterior1_imagerow > 275 & anterior1_imagecol > 370, invert = TRUE)
cortex <- subset(cortex, anterior1_imagerow > 250 & anterior1_imagecol > 440, invert = TRUE)
p1 <- SpatialDimPlot(cortex, crop = TRUE, label = TRUE)
p2 <- SpatialDimPlot(cortex, crop = FALSE, label = TRUE, pt.size.factor = 1, label.size = 3)
p1 + p2
8.与单细胞数据整合
在50um时,来自visium的斑点将包围多个细胞的表达谱。对于不断增长的可用scRNA-seq数据的系统列表,用户可能会对“反褶积”每个空间体素感兴趣,以预测细胞类型的底层组成。在准备这个教程时,我们测试了各种各样的decovonlution和集成方法,使用参考的reference scRNA-seq dataset,包括来自Allen研究所的约14,000成年小鼠皮质细胞分类,由SMART-Seq2生成。我们一直发现使用积分方法(相对于反褶积方法)会有更好的性能,这可能是因为描述空间和单细胞数据集的噪声模型存在本质上的差异,而积分方法是专门设计来应对这些差异的。因此我们应用“锚”的集成工作流最近在修v3,介绍,使注释的概率转移从一个参考查询集。因此,我们遵循这里介绍的标签转移流程,利用sctransform正常化,但预测新方法被开发来完成这项任务。
我们首先加载数据(这里可以下载),预处理scRNA-seq参考数据集,然后执行标签传输。该过程为每个点输出每个scRNA-seq派生类的概率分类。我们在Seurat对象中加入这些预测作为一个新的分析。
allen_reference <- readRDS("../data/allen_cortex.rds")
# note that setting ncells=3000 normalizes the full dataset but learns noise models on 3k cells this speeds up SCTransform dramatically with no loss in performance
library(dplyr)
allen_reference <- SCTransform(allen_reference, ncells = 3000, verbose = FALSE) %>% RunPCA(verbose = FALSE) %>% RunUMAP(dims = 1:30)
# After subsetting, we renormalize cortex
cortex <- SCTransform(cortex, assay = "Spatial", verbose = FALSE) %>% RunPCA(verbose = FALSE)
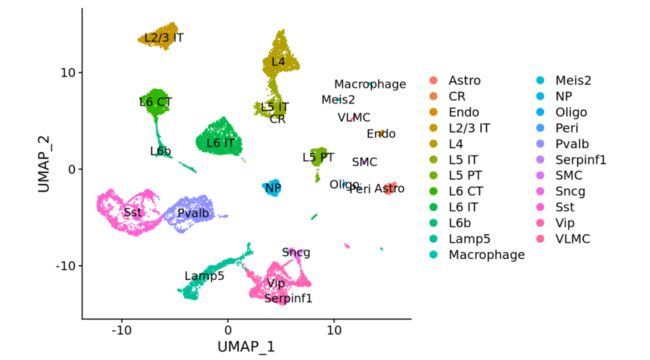
# the annotation is stored in the 'subclass' column of object metadata
DimPlot(allen_reference, group.by = "subclass", label = TRUE)
anchors <- FindTransferAnchors(reference = allen_reference, query = cortex, normalization.method = "SCT")
predictions.assay <- TransferData(anchorset = anchors, refdata =allen_reference$subclass, prediction.assay = TRUE, weight.reduction = cortex[["pca"]])
cortex[["predictions"]] <- predictions.assay
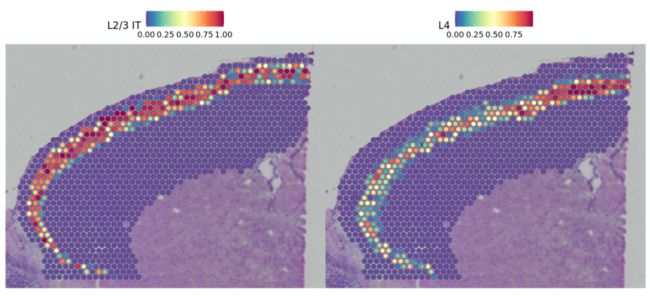
现在我们得到每个class的每个spot的预测分数。在额叶皮质区域特别有趣的是层状兴奋神经元(laminar excitatory neurons)。在这里,我们可以区分这些神经元亚型的不同顺序层,例如:
DefaultAssay(cortex) <- "predictions"
SpatialFeaturePlot(cortex, features = c("L2/3 IT", "L4"), pt.size.factor = 1.6, ncol = 2, crop = TRUE)
基于这些预测分数,我们还可以预测位置受空间限制的细胞类型。我们使用相同的基于标记点处理的方法来定义空间变量特征,但是使用细胞类型预测分数作为“标记”而不是基因表达。
cortex <- FindSpatiallyVariableFeatures(cortex, assay = "predictions", selection.method = "markvariogram", features = rownames(cortex), r.metric = 5, slot = "data")
top.clusters <- head(SpatiallyVariableFeatures(cortex), 4)
SpatialPlot(object = cortex, features = top.clusters, ncol = 2)
最后,我们证明我们的整合程序能够恢复神经和非神经亚群的已知空间定位模式,包括层兴奋性、第一层星形胶质细胞和皮质灰质。
SpatialFeaturePlot(cortex, features = c("Astro", "L2/3 IT", "L4", "L5 PT", "L5 IT", "L6 CT", "L6 IT", "L6b", "Oligo"), pt.size.factor = 1, ncol = 2, crop = FALSE, alpha = c(0.1, 1))
此处图比较大,去看官网吧。
9.在Seurat中使用多个切片
这个老鼠大脑的数据集包含了另一个对应于大脑的另一半的切片。在这里,我们读取它并执行相同的初始化。
brain2 <- LoadData("stxBrain", type = "posterior1")
brain2 <- SCTransform(brain2, assay = "Spatial", verbose = FALSE)
为了在同一个Seurat对象中使用多个片,我们提供了merge函数。
brain.merge <- merge(brain, brain2)
这样就可以减少潜在的RNA表达数据的联合维数和聚类。
DefaultAssay(brain.merge) <- "SCT"
VariableFeatures(brain.merge) <- c(VariableFeatures(brain), VariableFeatures(brain2))
brain.merge <- RunPCA(brain.merge, verbose = FALSE)
brain.merge <- FindNeighbors(brain.merge, dims = 1:30)
brain.merge <- FindClusters(brain.merge, verbose = FALSE)
brain.merge <- RunUMAP(brain.merge, dims = 1:30)
最后,数据可以联合显示在一个UMAP图中。SpatialDimPlot和SpatialFeaturePlot默认情况下将所有的切片绘制为列,将分组/特性绘制为行。
DimPlot(brain.merge, reduction = "umap", group.by = c("ident", "orig.ident"))

SpatialDimPlot(brain.merge)

SpatialFeaturePlot(brain.merge, features = c("Hpca", "Plp1"))

10.致谢
我们要感谢Nigel Delaney和Stephen Williams,感谢他们对新的空间Seurat代码的反馈和贡献。