插入记录:
语法结构:
⑴ INSERT [ INTO ] tbl_name [( col_name,...)] { VALUES | VALUE }
({ expr | DEFAULT },...),(...),...
⑵ INSERT [ INTO ] tbl_name SET col_name = { expr | DEFAULT },...
⑶ INSERT [ INTO ] tbl_name [( col_name,...)] SELECT ...
注:第一种可以一次性插入多条记录,第二种方式可以使用子查询(SubQuery)且只能一次性插入一条记录,第三种可以将查询结果插入到指定数据表中。
案例:
创建一张表 tb_user4:

插入一条记录:

再插入一条记录:

由图可以看出,主键 id 自动增长,而赋予该字段的值可以为 NULL 也可以为 DEFAULT:

如果在插入记录的时,省略了列名:

系统提示创建失败,原因是插入的列数和数据表里的列数不一致,所以在没有对指定列插入记录时,必须对数据表里所有列进行插入记录。
同样可以同时插入多条记录:
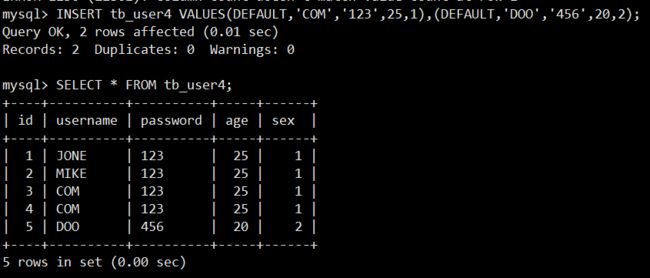
插入多条记录之间用 “,” 隔开。
我们来看看第二种插入记录方法:

插入一条记录,并查看表记录,由于 sex 允许非必填,所以插入记录的时候,可以忽略,系统自动赋值为 NULL 。
更新记录(单表更新):
语法结构:
UPDATE [ LOW_PRIORITY ] [ IGNORE ] table_reference SET
col_name1 = { expr1 | DEFAULT } [,col_name2 = { expr2 | DEFAULT }] ...
[ WHERE where_condition ]
案例:
将表 tb_user4 的所有字段 age 的值加1:

同时修改多个字段值,age 减 10,sex 等于 0:

以上更新记录没有指定 WHERE 条件,所以对表中所有的记录进行了更新。
通过条件来更新记录:

修改字段 id = 3 的年龄,并对年龄加 1 。
删除记录(单表删除):
语法结构:
DELETE FROM tbl_name [ WHERE where_condition ]
案例:
删除 id = 4 的记录:
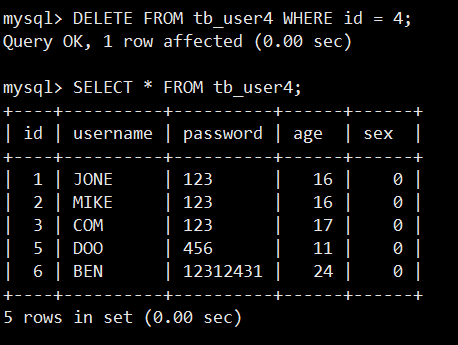
由图可以看出,id = 4 的记录已经不存在了。同样,如果没有指定 WHERE 条件,将删除数据表里所有记录。
注:如果再插入一条记录,新记录的 id 会在现有的最大 id 值加1,而并不会补充原来被删除的 id 值。
查询记录:
语法结构:
SELECT select_expr [,select_expr ...]
[
FROM table_references
[ WHERE where_condition ]
[ GROUP BY { col_name | position } [ ASC | DESC ],...]
[ HAVING where_condition ]
[ ORDER BY { col_name | expr | position } [ ASC | DESC ],...]
[ LIMIT {[ offset,] row_count | row_count OFFSET offset }]
]
其中,select_expr 查询表达式注意以下几点:
① 每个表达式表示想要的一列,必须且至少一个
② 多个列之间以 “,” 隔开
③ 星号(*)表示所有列。tbl_name.* 可以表示指定表的所有列
④ 查询表达式可以使用 [AS] alias_name 为其赋予别名
⑤ 别名可以用于 GROUP BY , ORDER BY 或 HAVING 字句
案例:
针对表 tb_user4,只查询字段 id和 username:
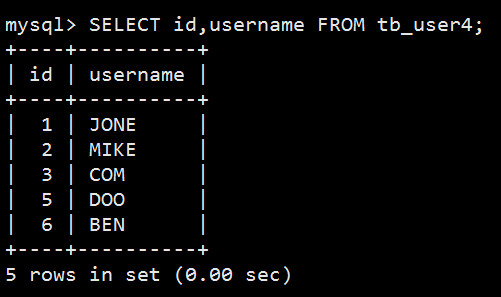
注:查询字段的顺序,影响查询结果的顺序。
也可以这么查询:

当然了,对于查询一张表来说,完全没必要这么操作,如果是对于多表查询,而多表之间的字段名称又重复,为了区别字段是属于哪张数据表,必须在字段名称前加数据表名称。
当我们在查询字段且字段名称特别长的时候,可以对其取别名:

可以发现,查询结果的字段名称已经变成我们所赋予的别名。
注:关键字 AS 一定要加上,加上,加上 !!!
WHERE(条件表达式):
⑴ 对条件进行过滤,如果没有指定 WHERE 子句,则显示所有记录
⑵ 在 WHERE 表达式中,可以使用 MySQL 支持的函数或运算符
GROUP BY(查询结果分组):
语法结构:
[ GROUP BY { col_name | position }] [ ASC | DESC ],...]
其中,ASC 是升序,系统默认;DESC 是降序。
案例:
先查看下表 tb_user4 的所有数据:
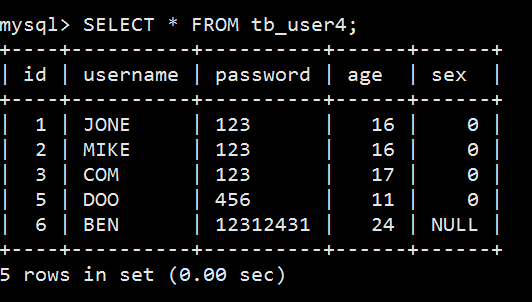
进行分组查询:

可以看出表 tb_user4 中的字段 sex 存在两种类型的值,NULL 和 0 。
HAVING(分组条件):
语法结构:
[ HAVING where_condition ]
案例:
对原有的分组过虑数量大于2的值:

在使用 HAVING 对分组结果进行过滤时,建议使用聚合函数。
ORDER BY (对分组结果进行排序):
语法结构:
[ ORDER BY { col_name | expr | position } [ ASC | DESC ],...]
案例:
查询下表 tb_user4 的记录:

可以看出,以字段 id 默认是升序排列。
以字段 id 降序排列:
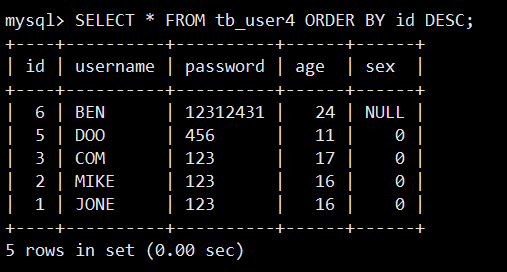
注:如果对多个字段进行排序,系统会依次对每个字段进行排序,输出用户想要的结果。
举个栗子:
如果对字段 age 进行排序(默认是升序):
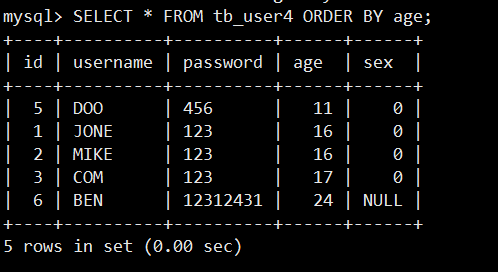
再添加一个字段 id 进行排序:

通过以上两个查询结果可以看出,id 的排列顺序是不一样的,虽然在 id=2 和 id=1 的年龄是一样,但是由于 id 值不一样,所以系统以这两个相同值的 id 进行排序。
LIMIT(限制查询结果返回的数量):
语法结构:
[ LIMIT {[ offset,] row_count | row_count OFFSET offset }]
案例:

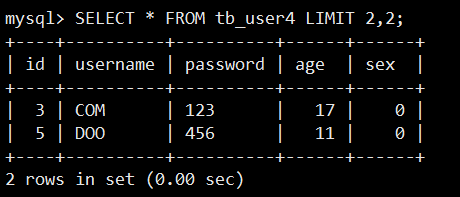
LIMIT 后只添加一个 2,查询返回从第 1 条开始,即索引位置从0开始,并返回 2 条。(与 id 无关,与记录的位置有关)
如果想查询第 3 条和第 4 条,可以这么操作:
在文章开头,INSERT 的用法里,其中第二种方法,可以将查询的结果插入到指定表里。
先新建一张表 tb_user5:

现在把表 tb_user4 中年龄大于或等于 20 的记录插入到表 tb_user5 里面:

可以发现,表 tb_user5 成功插入一条记录且该记录为表 tb_user4 里面年龄为 24 的记录。
验证一下:

以上是单表记录的一些常用操作,多表记录操作,下一篇见。
以上为本人的一些学习笔记,如有出错欢迎指正,陆续更新!!!