scikit-learn模型建立与评估
scikit-learn模型建立与评估
使用python库分析汽车油耗效率
import pandas as pd
import matplotlib.pyplot as plt
columns = ["mpg", "cylinders", "displacement", "horsepower", "weight", "acceleration", "model year", "origin", "car name"]
# delim_whitespace指定数据中以空格为切割符
cars = pd.read_table("auto-mpg.data", delim_whitespace=True, names=columns)
print(cars.head(5))

fig = plt.figure()
# 加子图
ax1 = fig.add_subplot(2,1,1)
ax2 = fig.add_subplot(2,1,2)
# kind='scatter'是散点图
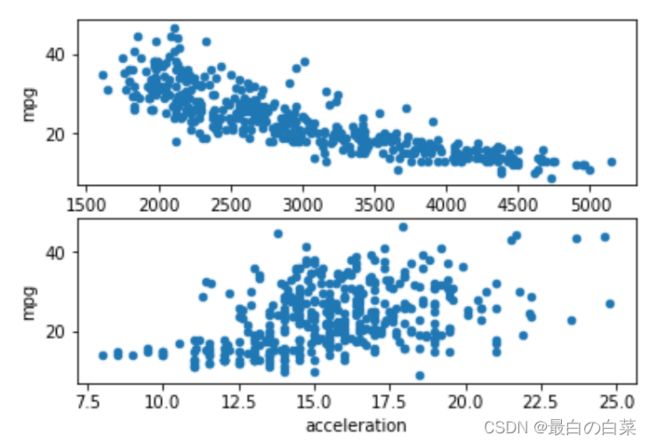
cars.plot("weight", "mpg", kind='scatter', ax=ax1)
cars.plot("acceleration", "mpg", kind='scatter', ax=ax2)
plt.show()
# 线性回归
import sklearn
from sklearn.linear_model import LinearRegression
lr = LinearRegression()
# 训练这个数据,后面那个指定label值
lr.fit(cars[["weight"]], cars["mpg"])
import sklearn
from sklearn.linear_model import LinearRegression
lr = LinearRegression(fit_intercept=True)
lr.fit(cars[["weight"]], cars["mpg"])
# 预测
predictions = lr.predict(cars[["weight"]])
print(predictions[0:5])
print(cars["mpg"][0:5])
[19.41852276 17.96764345 19.94053224 19.96356207 19.84073631]
0 18.0
1 15.0
2 18.0
3 16.0
4 17.0
Name: mpg, dtype: float64
plt.scatter(cars["weight"], cars["mpg"], c='red')
plt.scatter(cars["weight"], predictions, c='blue')
plt.show()

lr = LinearRegression()
lr.fit(cars[["weight"]], cars["mpg"])
predictions = lr.predict(cars[["weight"]])
from sklearn.metrics import mean_squared_error
# 均方误差
mse = mean_squared_error(cars["mpg"], predictions)
print(mse)
18.780939734628397
mse = mean_squared_error(cars["mpg"], predictions)
# 求根号
rmse = mse ** (0.5)
print (rmse)
4.333698159150957
使用逻辑回归改进模型效果
import pandas as pd
import matplotlib.pyplot as plt
admissions = pd.read_csv("admissions.csv")
print(admissions.head())
plt.scatter(admissions['gpa'], admissions['admit'])
plt.show()

import numpy as np
# Logit Function
def logit(x):
# np.exp(x) raises x to the exponential power, ie e^x. e ~= 2.71828
return np.exp(x) / (1 + np.exp(x))
# Generate 50 real values, evenly spaced, between -6 and 6.
x = np.linspace(-6,6,50, dtype=float)
# Transform each number in t using the logit function.
y = logit(x)
# Plot the resulting data.
plt.plot(x, y)
plt.ylabel("Probability")
plt.show()

from sklearn.linear_model import LinearRegression
linear_model = LinearRegression()
linear_model.fit(admissions[["gpa"]], admissions["admit"])
from sklearn.linear_model import LogisticRegression
logistic_model = LogisticRegression()
logistic_model.fit(admissions[["gpa"]], admissions["admit"])
logistic_model = LogisticRegression()
logistic_model.fit(admissions[["gpa"]], admissions["admit"])
# 预测可能性
pred_probs = logistic_model.predict_proba(admissions[["gpa"]])
plt.scatter(admissions["gpa"], pred_probs[:,1])
plt.show()

logistic_model = LogisticRegression()
logistic_model.fit(admissions[["gpa"]], admissions["admit"])
# 得到准确的类别
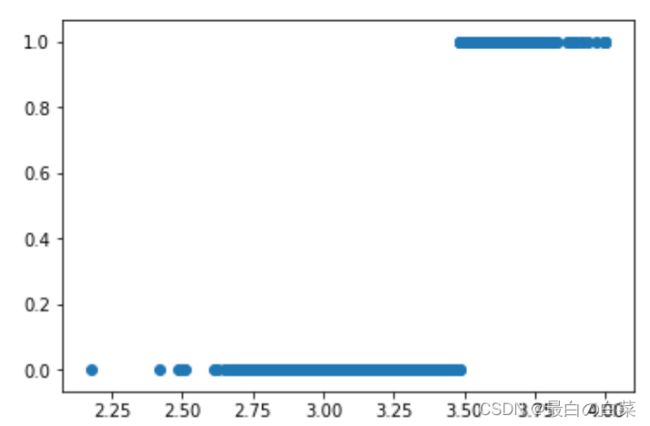
fitted_labels = logistic_model.predict(admissions[["gpa"]])
plt.scatter(admissions["gpa"], fitted_labels)
plt.show()
模型效果衡量标准
import pandas as pd
import matplotlib.pyplot as plt
from sklearn.linear_model import LogisticRegression
admissions = pd.read_csv("admissions.csv")
model = LogisticRegression()
model.fit(admissions[["gpa"]], admissions["admit"])
admissions = pd.read_csv("admissions.csv")
model = LogisticRegression()
model.fit(admissions[["gpa"]], admissions["admit"])
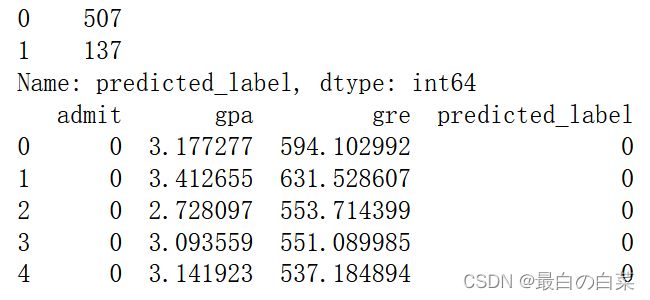
labels = model.predict(admissions[["gpa"]])
admissions["predicted_label"] = labels
print(admissions["predicted_label"].value_counts())
# 0代表被拒绝;1代表被接受
print(admissions.head())
admissions["actual_label"] = admissions["admit"]
# 将预测结果与真实结果进行比较
matches = admissions["predicted_label"] == admissions["actual_label"]
correct_predictions = admissions[matches]
print(correct_predictions.head())
accuracy = len(correct_predictions) / float(len(admissions))
# 精度衡量
print(accuracy)

# TP;FP;FN;TN
true_positive_filter = (admissions["predicted_label"] == 1) & (admissions["actual_label"] == 1)
true_positives = len(admissions[true_positive_filter])
true_negative_filter = (admissions["predicted_label"] == 0) & (admissions["actual_label"] == 0)
true_negatives = len(admissions[true_negative_filter])
print(true_positives)
print(true_negatives)
89
352
true_positive_filter = (admissions["predicted_label"] == 1) & (admissions["actual_label"] == 1)
true_positives = len(admissions[true_positive_filter])
false_negative_filter = (admissions["predicted_label"] == 0) & (admissions["actual_label"] == 1)
false_negatives = len(admissions[false_negative_filter])
sensitivity = true_positives / float((true_positives + false_negatives))
# 100人有36人被正确检测录取了,还有64人没检测出来,所以不能光看之前的68%的精度
print(sensitivity)
0.36475409836065575
true_positive_filter = (admissions["predicted_label"] == 1) & (admissions["actual_label"] == 1)
true_positives = len(admissions[true_positive_filter])
false_negative_filter = (admissions["predicted_label"] == 0) & (admissions["actual_label"] == 1)
false_negatives = len(admissions[false_negative_filter])
true_negative_filter = (admissions["predicted_label"] == 0) & (admissions["actual_label"] == 0)
true_negatives = len(admissions[true_negative_filter])
false_positive_filter = (admissions["predicted_label"] == 1) & (admissions["actual_label"] == 0)
false_positives = len(admissions[false_positive_filter])
specificity = (true_negatives) / float((false_positives + true_negatives))
# 检测负例的效果。100人,88个人不该来,确实却测出了他不应该被录取,12个没检测出来
print(specificity)
0.88
ROC指标与测试集的价值
# 实际应用中都是分为训练集和测试集的,不能用训练集既当训练集又当测试集
import pandas as pd
from sklearn.linear_model import LogisticRegression
admissions = pd.read_csv("admissions.csv")
admissions["actual_label"] = admissions["admit"]
admissions = admissions.drop("admit", axis=1)
print(admissions.head())

import numpy as np
np.random.seed(8)
admissions = pd.read_csv("admissions.csv")
admissions["actual_label"] = admissions["admit"]
admissions = admissions.drop("admit", axis=1)
# 通过np.random.permutation函数对index进行洗牌操作,将数据集的顺序打乱,消除一致性,返回的是索引列表shuffled_index
shuffled_index = np.random.permutation(admissions.index)
# print shuffled_index
# 再.loc重排序索引
shuffled_admissions = admissions.loc[shuffled_index]
# 取前515个数据做训练集
train = shuffled_admissions.iloc[0:515]
test = shuffled_admissions.iloc[515:len(shuffled_admissions)]
print(shuffled_admissions.head())

shuffled_index = np.random.permutation(admissions.index)
shuffled_admissions = admissions.loc[shuffled_index]
train = shuffled_admissions.iloc[0:515]
test = shuffled_admissions.iloc[515:len(shuffled_admissions)]
model = LogisticRegression()
model.fit(train[["gpa"]], train["actual_label"])
labels = model.predict(test[["gpa"]])
test["predicted_label"] = labels
matches = test["predicted_label"] == test["actual_label"]
correct_predictions = test[matches]
accuracy = len(correct_predictions) / float(len(test))
print(accuracy)
0.7286821705426356
model = LogisticRegression()
model.fit(train[["gpa"]], train["actual_label"])
labels = model.predict(test[["gpa"]])
test["predicted_label"] = labels
matches = test["predicted_label"] == test["actual_label"]
correct_predictions = test[matches]
accuracy = len(correct_predictions) / len(test)
true_positive_filter = (test["predicted_label"] == 1) & (test["actual_label"] == 1)
true_positives = len(test[true_positive_filter])
false_negative_filter = (test["predicted_label"] == 0) & (test["actual_label"] == 1)
false_negatives = len(test[false_negative_filter])
sensitivity = true_positives / float((true_positives + false_negatives))
print(sensitivity)
false_positive_filter = (test["predicted_label"] == 1) & (test["actual_label"] == 0)
false_positives = len(test[false_positive_filter])
true_negative_filter = (test["predicted_label"] == 0) & (test["actual_label"] == 0)
true_negatives = len(test[true_negative_filter])
specificity = (true_negatives) / float((false_positives + true_negatives))
print(specificity)
0.46808510638297873
0.8780487804878049
正例效果不好,负例大多都对
接下来根据真实值,和预测值来画roc曲线
要小心过拟合的现象:数据在训练集上表现很好,但是测试集上数据差异很大,就表示遇到了过拟合。一般测试集和训练集上的结果都要表现的差不多才行。
import matplotlib.pyplot as plt
from sklearn import metrics
probabilities = model.predict_proba(test[["gpa"]])
fpr, tpr, thresholds = metrics.roc_curve(test["actual_label"], probabilities[:,1])
# 阈值threshold。每个点都代表不同的阈值,对应不同的指标值
print(thresholds)
plt.plot(fpr, tpr)
plt.show()

from sklearn.metrics import roc_auc_score
probabilities = model.predict_proba(test[["gpa"]])
# Means we can just use roc_auc_curve() instead of metrics.roc_auc_curve()
auc_score = roc_auc_score(test["actual_label"], probabilities[:,1])
# 得到roc评分值,越高越好
print(auc_score)
0.7210690192008302
交叉验证
import pandas as pd
import numpy as np
admissions = pd.read_csv("admissions.csv")
admissions["actual_label"] = admissions["admit"]
admissions = admissions.drop("admit", axis=1)
shuffled_index = np.random.permutation(admissions.index)
shuffled_admissions = admissions.loc[shuffled_index]
admissions = shuffled_admissions.reset_index()
# 切成5块
admissions.loc[0:128, "fold"] = 1
admissions.loc[129:257, "fold"] = 2
admissions.loc[258:386, "fold"] = 3
admissions.loc[387:514, "fold"] = 4
admissions.loc[515:644, "fold"] = 5
# Ensure the column is set to integer type.
admissions["fold"] = admissions["fold"].astype('int')
print(admissions.head())
print(admissions.tail())

from sklearn.linear_model import LogisticRegression
# Training
model = LogisticRegression()
# 训练是2,3,4,5块
train_iteration_one = admissions[admissions["fold"] != 1]
test_iteration_one = admissions[admissions["fold"] == 1]
model.fit(train_iteration_one[["gpa"]], train_iteration_one["actual_label"])
# Predicting
labels = model.predict(test_iteration_one[["gpa"]])
test_iteration_one["predicted_label"] = labels
matches = test_iteration_one["predicted_label"] == test_iteration_one["actual_label"]
correct_predictions = test_iteration_one[matches]
iteration_one_accuracy = len(correct_predictions) / float(len(test_iteration_one))
print(iteration_one_accuracy)
0.6434108527131783
import numpy as np
fold_ids = [1,2,3,4,5]
# 五次迭代
def train_and_test(df, folds):
fold_accuracies = []
for fold in folds:
model = LogisticRegression()
train = admissions[admissions["fold"] != fold]
test = admissions[admissions["fold"] == fold]
model.fit(train[["gpa"]], train["actual_label"])
labels = model.predict(test[["gpa"]])
test["predicted_label"] = labels
matches = test["predicted_label"] == test["actual_label"]
correct_predictions = test[matches]
fold_accuracies.append(len(correct_predictions) / float(len(test)))
return(fold_accuracies)
accuracies = train_and_test(admissions, fold_ids)
print(accuracies)
average_accuracy = np.mean(accuracies)
print(average_accuracy)
[0.6434108527131783, 0.7131782945736435, 0.6666666666666666, 0.75, 0.6821705426356589]
0.6910852713178295
# 以上是手写的交叉验证算法,下面是使用sklearn里面的交叉验证
from sklearn.model_selection import KFold
from sklearn.model_selection import cross_val_score
admissions = pd.read_csv("admissions.csv")
admissions["actual_label"] = admissions["admit"]
admissions = admissions.drop("admit", axis=1)
# 报错TypeError: __init__() takes from 1 to 2 positional arguments but 3 positional arguments (and 2 keyword-only arguments) were given
# kf = KFold(len(admissions), 5, shuffle=True, random_state=8)
kf = KFold(5, shuffle=True, random_state=8)
lr = LogisticRegression()
#roc_auc ;scoring指定什么参数,就可以返回什么值
accuracies = cross_val_score(lr,admissions[["gpa"]], admissions["actual_label"], scoring="roc_auc", cv=kf)
average_accuracy = sum(accuracies) / len(accuracies)
print(accuracies)
print(average_accuracy)
[0.70790123 0.69550265 0.65987934 0.73363017 0.57864583]
0.6751118445238359
多类别分类问题
# 方法:one vs all
import pandas as pd
import matplotlib.pyplot as plt
columns = ["mpg", "cylinders", "displacement", "horsepower", "weight", "acceleration", "year", "origin", "car name"]
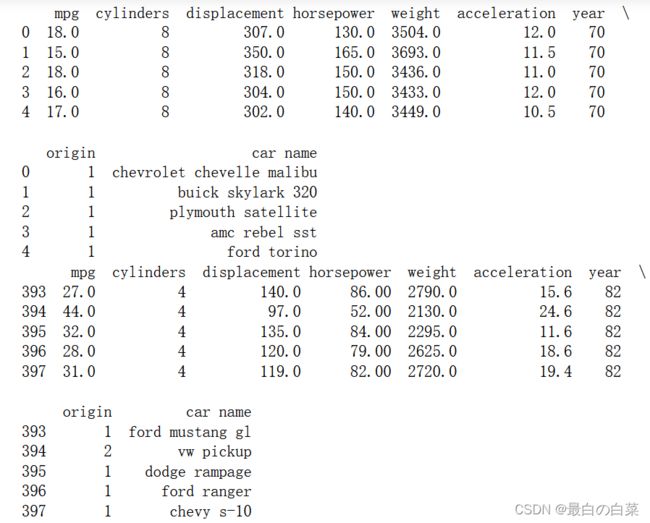
cars = pd.read_table("auto-mpg.data", delim_whitespace=True, names=columns)
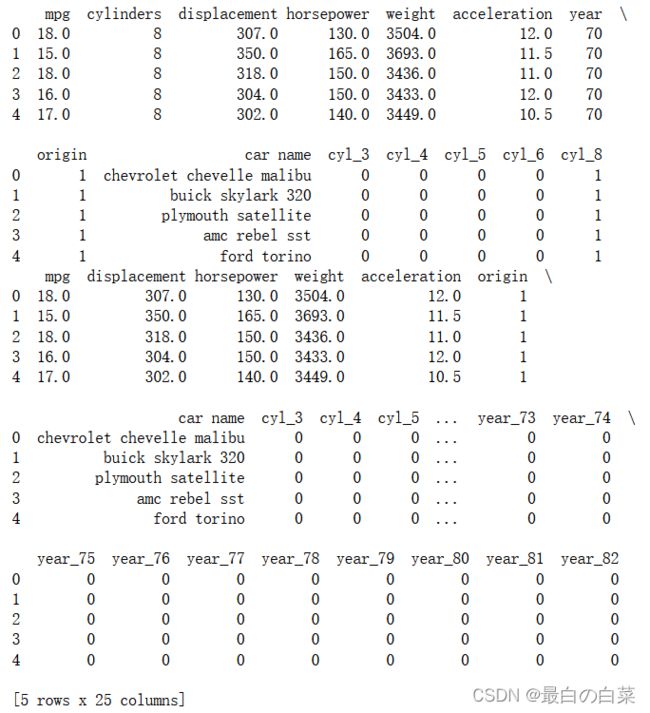
print(cars.head(5))
print(cars.tail(5))
# 将种类特征转换为dummies格式,额外提取特征
dummy_cylinders = pd.get_dummies(cars["cylinders"], prefix="cyl")
#print dummy_cylinders
cars = pd.concat([cars, dummy_cylinders], axis=1)
print(cars.head())
dummy_years = pd.get_dummies(cars["year"], prefix="year")
#print dummy_years
cars = pd.concat([cars, dummy_years], axis=1)
cars = cars.drop("year", axis=1)
cars = cars.drop("cylinders", axis=1)
print(cars.head())
import numpy as np
shuffled_rows = np.random.permutation(cars.index)
shuffled_cars = cars.iloc[shuffled_rows]
highest_train_row = int(cars.shape[0] * .70)
train = shuffled_cars.iloc[0:highest_train_row]
test = shuffled_cars.iloc[highest_train_row:]
对于多分类的问题我们发现标签origin只有三种,1,2,3,产地,于是我们分类器也要训练3个
1与2,3分,2与1,3分,3与1,2分,并把训练好的3个分类model存在字典里方便调用
from sklearn.linear_model import LogisticRegression
unique_origins = cars["origin"].unique()
unique_origins.sort()
models = {}
features = [c for c in train.columns if c.startswith("cyl") or c.startswith("year")]
for origin in unique_origins:
model = LogisticRegression()
X_train = train[features]
y_train = train["origin"] == origin
model.fit(X_train, y_train)
models[origin] = model
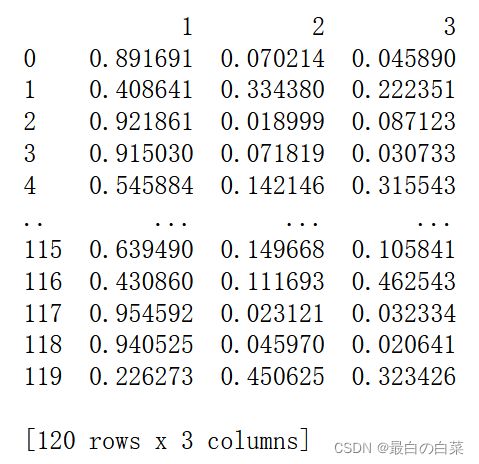
testing_probs = pd.DataFrame(columns=unique_origins)
for origin in unique_origins:
# Select testing features.
X_test = test[features]
# Compute probability of observation being in the origin.
testing_probs[origin] = models[origin].predict_proba(X_test)[:,1]
# 每一行概率最大的值对应的column就是所预测分类
print (testing_probs)
报错问题解决
TypeError: Cannot interpret ‘
https://www.cnblogs.com/LLLLgR/p/15023261.html
AttributeError: ‘DataFrame’ object has no attribute 'ix’
将ix改为loc
TypeError: init() takes from 1 to 2 positional arguments but 3 positional arguments (and 2 keyword-only arguments) were given
kf = KFold(len(admissions), 5, shuffle=True, random_state=8)删掉第一个参数就可以了,改为kf = KFold(5, shuffle=True, random_state=8)
https://www.cnblogs.com/broccoli919/p/14031935.html