python基础爬虫——爬取天气预报信息
困于心衡于虑而后作
今天的学习目标是:编写爬虫程序爬取天气预报信息并保存到数据库
技术实现:
1、 爬取普通的网页信息,查看浏览器的user-agnet
2、 编写sql语句,创建相应的数据表,并编写存储数据的语句
3、 实现爬取中国天气网的信息(由于地区限制,现在爬取不了天气,之后将在其他网站上实现)
1.python代码爬取网页信息并显示运行结果
首先查看自己浏览器的user-agent
打开检查,点击网络network,然后重新加载自己的页面,就会出现如下界面:
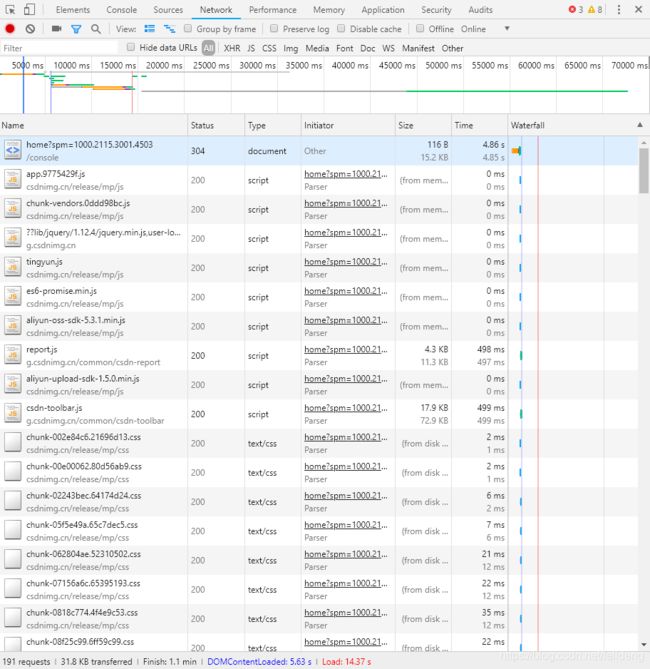
随便点击一项进去之后,就可以看见返回信息或者是请求信息,这里查看的是header信息
我们可以将这个header信息做成字典,然后在爬虫程序中将信息提交,让爬虫程序模拟浏览器访问网页,在配合使用time库时,爬取网页信息不会给服务器造成太大的负担,能减少爬虫被屏蔽的概率
这里我们可以看到浏览器的user-agent
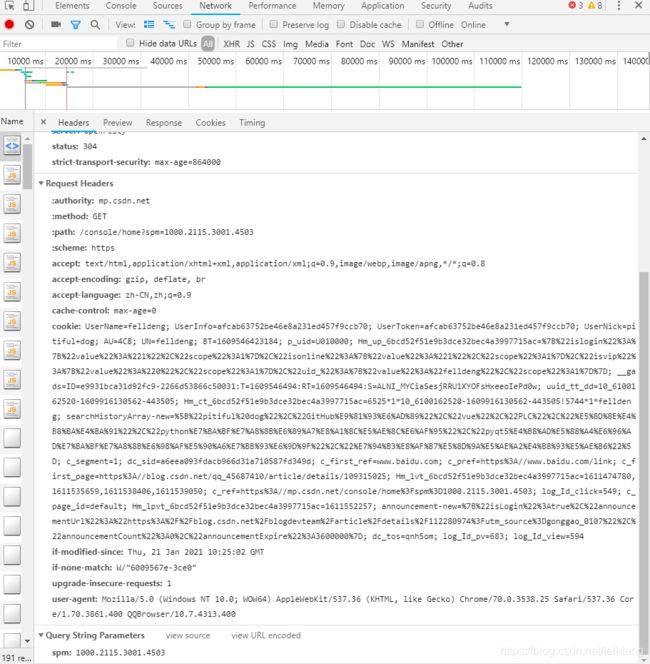
在爬虫程序中,将user-agent做成字典
from bs4 import BeautifulSoup
from bs4 import UnicodeDammit
import urllib.request
url = 'http://www/weather.com.cn/weather/101280601.shtml'
try:
headers = {
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.25 Safari/537.36 Core/1.70.3861.400 QQBrowser/10.7.4313.400'}
req = urllib.request.Request(url, headers=headers)
data = urllib.request.urlopen(req)
data = data.read()
dammit = UnicodeDammit(data, ['utf-8', 'gbk'])
data = dammit.unicode_markup
soup = BeautifulSoup(data, 'lxml')
lis = soup.select("ul[class='t clearfix'] li")
for li in lis:
try:
date = li.select('h1')[0].text
weather = li.select("p[class='wea']")[0].text
temp = li.select("p[class='tem'] span")[0].text + '/' + li.select("p[class='tem'] i")[0].text
print(date, weather, temp)
except Exception as e:
print(e)
except Exception as e:
print('错误', e)
# 错误 2.python代码创建数据库并存取所爬取的信息
由于地区限制,这段代码暂时无法验证和调试,等待时机会将这段代码调试完成
from bs4 import BeautifulSoup
from bs4 import UnicodeDammit
import urllib.request
import sqlite3
class WeatherDB:
def openDB(self):
self.con = sqlite3.connect('weather.db')
self.cursor = self.con.cursor()
try:
self.cursor.execute(
'create table weathers(wCity varchar(16),wDate varchar(16),wWeather varchar(64),wTemp varchar(32),constraint pk_weather primary key (wCity,wDate))')
except:
self.cursor.execute('delete from weathers')
def closeDB(self):
self.con.commit()
self.con.close()
def insert(self, city, date, weather, temp):
try:
self.cursor.execute("insert into weathers(wCity,wDate,wWeather,wTemp) values(?,?,?,?)",
(city, date, weather, temp))
except Exception as err:
print(err)
def show(self):
self.cursor.execute("select * from weathers")
rows = self.cursor.fetchall()
print("%-16s%-16s%-32s%-16s%" % ("city", "date", 'weather', 'temp'))
for row in rows:
print("%-16s%-16s%-32s%-16s%" % (row[0], row[1], row[2], row[3]))
class WeatherForecast:
def __init__(self):
self.headers = {
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.25 Safari/537.36 Core/1.70.3861.400 QQBrowser/10.7.4313.400'
}
self.cityCode = {
"北京": '101010100', '上海': '101020100', '广州': '101280101', '深圳': '101280601'
}
def forecastCity(self, city):
if city not in self.cityCode.keys():
print(city + 'code cannot be found')
return
url = 'http://www.weather.com.cn/weather/' + self.cityCode[city] + '.shtml'
try:
req = urllib.request.Request(url, headers=self.headers)
data = urllib.request.urlopen(req)
data = data.read()
dammit = UnicodeDammit(data, ['utf-8', 'gbk'])
data = dammit.unicode_markup
soup = BeautifulSoup(data, 'lxml')
lis = soup.select("ul[class='t clearfix'] li")
for li in lis:
try:
date = li.select('h1')[0].text
weather = li.select("p[class='wea']")[0].text
temp = li.select("p[class='tem'] span")[0].text + '/' + li.select("p[class='tem'] i")[0].text
print(city, date, weather, temp)
self.db.insert(city, date, weather, temp)
except Exception as err:
print(err)
except Exception as err:
print(err)
def process(self, cities):
self.db = WeatherDB()
self.db.openDB()
for city in cities:
self.forecastCity(city)
#self.db.show()
self.db.closeDB()
ws = WeatherForecast()
ws.process(['北京', '上海', '广州', '深圳'])
print('completed')