Apache Flink的简介
Apache Flink是一个开源的针对批量数据和流数据的处理引擎,已经发展为ASF的顶级项目之一。Flink 的核心是在数据流上提供了数据分发、通信、具备容错的分布式计算。同时,Flink 在流处理引擎上构建了批处理引擎,原生支持了迭代计算、内存管理和程序优化。
Flink的技术栈
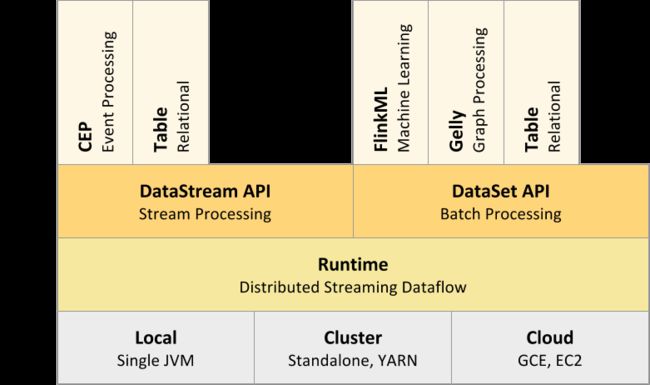
Flink主要API
- DataSet API:对静态数据进行批处理操作,将静态数据抽象成分布式的数据集,用户可以方便地使用Flink提供的各种操作符对分布式数据集进行处理,支持Java、Scala和Python。
- DataStream API:对数据流进行流处理操作,将流式的数据抽象成分布式的数据流,用户可以方便地对分布式数据流进行各种操作,支持Java和Scala。
- Table API:对结构化数据进行查询操作,将结构化数据抽象成关系表,并通过类SQL的DSL对关系表进行各种查询操作,支持Java和Scala。
- Flink ML:Flink的机器学习库,提供了机器学习Pipelines API并实现了多种机器学习算法。
- Gelly:Flink的图计算库,提供了图计算的相关API及多种图计算算法实现。
Flink的部署方式
- 本地模式
- 集群模式或yarn集群
- 云集群部署
另外,Flink也可以方便地和Hadoop生态圈中其他项目集成,例如Flink可以读取存储在HDFS或HBase中的静态数据,以Kafka作为流式的数据源,直接重用MapReduce或Storm代码,或是通过YARN申请集群资源等。
Apache Flink的架构

当Flink集群启动后,首先会启动一个JobManger和一个或多个的 TaskManager。由Client提交任务给JobManager,JobManager再调度任务到各个TaskManager去执行,然后TaskManager将心跳和统计信息汇报给 JobManager。TaskManager之间以流的形式进行数据的传输。上述三者均为独立的JVM进程。
- Client:提交Job的客户端,可以是运行在任何机器上(与JobManager环境连通即可)
- JobManager:Flink系统的协调者,负责任务的排定分配、快照协调、失败恢复控制等,有三种部署模式:单机、一主多备集群、Yarn集群
- TaskManger:负责具体数据分析任务的执行,主要有业务数据的计算、传输等,相对于Storm的Worker把内存交给jvm管理,Flink的TaskManager还自己管理了部分内存
- TaskSlot:运行TaskManager中固定大小的资源子集,一个TaskManager中有多少个TaskSlot意味着可以执行多少个Task
- Task:执行组件,即业务计算的执行实体
Flink运行例子
package com.shopee.flink;
import org.apache.flink.api.common.functions.FlatMapFunction;
import org.apache.flink.api.common.functions.ReduceFunction;
import org.apache.flink.api.java.utils.ParameterTool;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.api.windowing.time.Time;
import org.apache.flink.util.Collector;
import java.util.Arrays;
public class FlinkDemo {
public static void main(String[] args) throws Exception {
// Checking input parameters
final ParameterTool params = ParameterTool.fromArgs(args);
// set up the execution environment
final StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
// make parameters available in the web interface
env.getConfig().setGlobalJobParameters(params);
DataStream text;
if (params.has("input")) {
text = env.readTextFile(params.get("input"));
} else {
// get default
text = env.socketTextStream("127.0.0.1", 9999);
}
DataStream counts = text.flatMap(new FlatMapFunction() {
public void flatMap(String s, Collector collector) {
Arrays.stream(s.split(",")).forEach(word -> collector.collect(new WordWithCount(word, 1L)));
}
}).keyBy("word")
.timeWindow(Time.seconds(5L), Time.seconds(1L))
.reduce(new ReduceFunction() {
@Override
public WordWithCount reduce(WordWithCount a, WordWithCount b) throws Exception {
return new WordWithCount(a.word, a.count + b.count);
}
});
// emit result
if (params.has("output")) {
counts.writeAsText(params.get("output"));
} else {
System.out.println("Printing result to stdout. Use --output to specify output path.");
counts.print();
}
// execute program
env.execute("Streaming WordCount");
}
public static class WordWithCount {
public String word;
public long count;
public WordWithCount() {
}
public WordWithCount(String word, long count){
this.word = word;
this.count = count;
}
public String toString(){
return word + " : " + count;
}
}
}
将最后一行代码 env.execute 替换成 System.out.println(env.getExecutionPlan()); 得到该拓扑的逻辑执行计划图的 JSON 串,将该 JSON 串粘贴到 http://flink.apache.org/visualizer/

启动 nc 命令:

Maven package 打包后,执行:flink run -c com.shopee.flink.FlinkDemo /Users/zhironghu/Documents/shopee/git/shopee-flink/target/flink-1.0-SNAPSHOT.jar -output /tmp/flink.log
则结果:
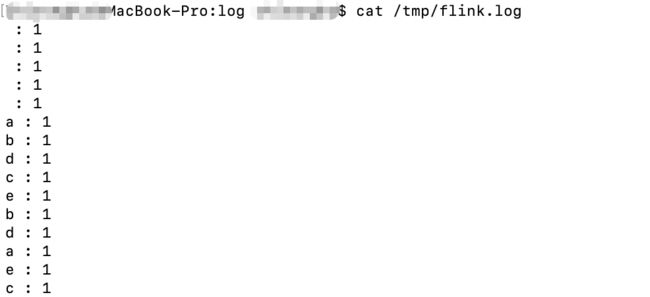

- Source:Collection Source:收据数据源,当前是从字符串数数组里面读取
- Flat Map:把每一条句子分隔成一个个的单词,设置每个单词的出现次数为1,并提交到下游
- Windows:时间窗口
- ReduceFunction:对单词进行聚合统计
- Sink Unamed:输出统计结果
Graph
Flink 中的执行图可以分成四层:StreamGraph -> JobGraph -> ExecutionGraph -> 物理执行图。
- StreamGraph: 是根据用户通过 Stream API 编写的代码生成的最初的图。用来表示程序的拓扑结构。
- JobGraph: StreamGraph经过优化后生成了 JobGraph,提交给 JobManager 的数据结构。主要的优化为,将多个符合条件的节点 chain 在一起作为一个节点,这样可以减少数据在节点之间流动所需要的序列化/反序列化/传输消耗。
- ExecutionGraph: JobManager 根据 JobGraph 生成的分布式执行图,是调度层最核心的数据结构。
-
物理执行图: JobManager 根据 ExecutionGraph 对 Job 进行调度后,在各个TaskManager 上部署 Task 后形成的“图”,并不是一个具体的数据结构。
 四层执行图的演变过程
四层执行图的演变过程
相关概念
StreamGraph:根据用户通过 Stream API 编写的代码生成的最初的图。
StreamNode:用来代表 operator 的类,并具有所有相关的属性,如并发度、入边和出边等。
StreamEdge:表示连接两个StreamNode的边。
JobGraph:StreamGraph经过优化后生成了 JobGraph,提交给 JobManager 的数据结构。
JobVertex:经过优化后符合条件的多个StreamNode可能会chain在一起生成一个JobVertex,即一个JobVertex包含一个或多个operator,JobVertex的输入是JobEdge,输出是IntermediateDataSet。
IntermediateDataSet:表示JobVertex的输出,即经过operator处理产生的数据集。producer是JobVertex,consumer是JobEdge。
JobEdge:代表了job graph中的一条数据传输通道。source 是 IntermediateDataSet,target 是 JobVertex。即数据通过JobEdge由IntermediateDataSet传递给目标JobVertex。
ExecutionGraph:JobManager 根据 JobGraph 生成的分布式执行图,是调度层最核心的数据结构。
ExecutionJobVertex:和JobGraph中的JobVertex一一对应。每一个ExecutionJobVertex都有和并发度一样多的 ExecutionVertex。
ExecutionVertex:表示ExecutionJobVertex的其中一个并发子任务,输入是ExecutionEdge,输出是IntermediateResultPartition。
IntermediateResult:和JobGraph中的IntermediateDataSet一一对应。每一个IntermediateResult的IntermediateResultPartition个数等于该operator的并发度。
-IntermediateResultPartition:表示ExecutionVertex的一个输出分区,producer是ExecutionVertex,consumer是若干个ExecutionEdge。ExecutionEdge:表示ExecutionVertex的输入,source是IntermediateResultPartition,target是ExecutionVertex。source和target都只能是一个。
Execution:是执行一个 ExecutionVertex 的一次尝试。当发生故障或者数据需要重算的情况下 ExecutionVertex 可能会有多个 ExecutionAttemptID。一个 Execution 通过 ExecutionAttemptID 来唯一标识。JM和TM之间关于 task 的部署和 task status 的更新都是通过 ExecutionAttemptID 来确定消息接受者。
物理执行图:JobManager 根据 ExecutionGraph 对 Job 进行调度后,在各个TaskManager 上部署 Task 后形成的“图”,并不是一个具体的数据结构。
Task:Execution被调度后在分配的 TaskManager 中启动对应的 Task。Task 包裹了具有用户执行逻辑的 operator。
ResultPartition:代表由一个Task的生成的数据,和ExecutionGraph中的IntermediateResultPartition一一对应。
ResultSubpartition:是ResultPartition的一个子分区。每个ResultPartition包含多个ResultSubpartition,其数目要由下游消费 Task 数和 DistributionPattern 来决定。
InputGate:代表Task的输入封装,和JobGraph中JobEdge一一对应。每个InputGate消费了一个或多个的ResultPartition。
InputChannel:每个InputGate会包含一个以上的InputChannel,和ExecutionGraph中的ExecutionEdge一一对应,也和ResultSubpartition一对一地相连,即一个InputChannel接收一个ResultSubpartition的输出。

JobGraph 之上除了 StreamGraph 还有 OptimizedPlan。OptimizedPlan 是由 Batch API 转换而来的。StreamGraph 是由 Stream API 转换而来的。为什么 API 不直接转换成 JobGraph?因为,Batch 和 Stream 的图结构和优化方法有很大的区别,比如 Batch 有很多执行前的预分析用来优化图的执行,而这种优化并不普适于 Stream,所以通过 OptimizedPlan 来做 Batch 的优化会更方便和清晰,也不会影响 Stream。JobGraph 的责任就是统一 Batch 和 Stream 的图,用来描述清楚一个拓扑图的结构,并且做了 chaining 的优化,chaining 是普适于 Batch 和 Stream 的,所以在这一层做掉。ExecutionGraph 的责任是方便调度和各个 tasks 状态的监控和跟踪,所以 ExecutionGraph 是并行化的 JobGraph。而“物理执行图”就是最终分布式在各个机器上运行着的tasks了。所以可以看到,这种解耦方式极大地方便了我们在各个层所做的工作,各个层之间是相互隔离的。
Apache Flink兼容Apache Storm
业界当前主流的流式处理引擎为Apache Storm,Flink为了更好的与业界衔接,在流处理上对Storm是做了兼容,通过复用代码的方式即可实现Storm在Flink运行环境的执行,这个也大大降低了Storm使用者过渡到Flink的难度;同理Flink也可以运行我们数平的JStorm。
Apache Flink 与Apache Storm的异同
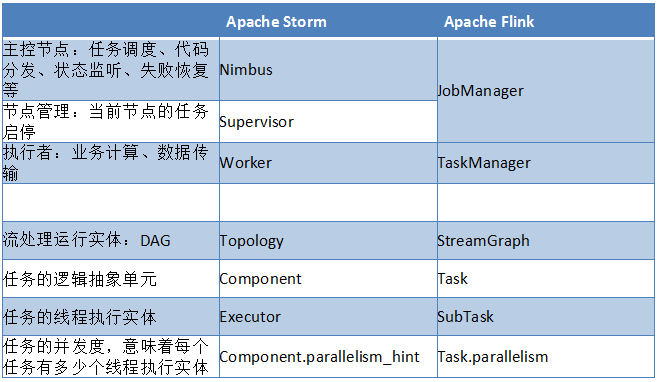
- 与Apache Storm相比,Apache Flink少了一层节点管理器,TaskManager直接由主控节点管理
- 在流处理这一块,Apache Flink与Apache Storm从运行实体到任务组件,基本上能一一对应
虽然两者运行实体的结构及代码有一定的差别,但归根到底两者运行的都是有向无环图(DAG),所以从Storm的Topology相关类转换成Flink执行的DataStream相关类是可以作转换的。
以下是粗略的转换过程:Storm Topology -> Flink Topology -> DataStream StreamGraph
举个例子:已有WordCountTopology,需要提交到Flink集群,那么只需下面几行代码:
final TopologyBuilder builder = WordCountTopology.buildTopology();//构造storm的topology
Map conf = new HashMap();
conf.put("nimbus.host", xxxx);//optional,master server
conf.put("nimbus.thrift.port", xxxx);//optional, master server port
FlinkSubmitter.submitTopology(topologyId, conf, FlinkTopology.createTopology(bgy转换成FlinkTopology再提交));