
在上一篇文章:Java集合框架—HashMap—源码研读-2 中,我们讲解的是Map接口下的HashMap,今天让我们来看看另一个Map实现类:LinkedHashMap。
本篇文章内容主要分为以下几点:
1.Map接口实现类的构成和关系图。
2.HashMap和LinkedHashMap的关系梳理
3.LinkedHashMap的底层数据结构
4.LinkedHashMap源码解读
1.Map接口实现类的构成和关系图
在说Map之前,让我们梳理一下Java集合框架的结构:
在Java集合框架中,分为两大类别:
1.实现了Collection接口的类—【单列集合】
2.实现了Map接口的类—【双列集合】
为什么区分为单列和双列?其实很好理解,Collection接口下又包含三大主接口:List、Queue、Set,实现了这三大接口的类,里面存放的都是单个元素,所以称为单列集合。而实现Map接口的类,存放的全是【key】-【value】类型的键值对,总是成双出现,故称为双列集合
让我们看一张比较完整的图:
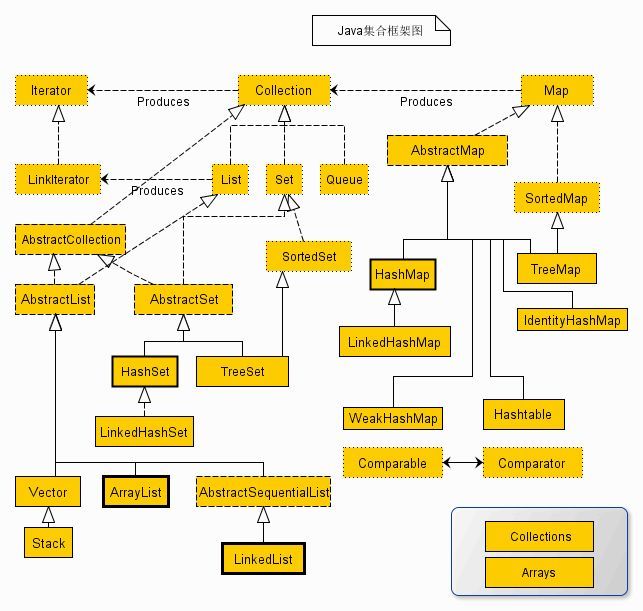
这张图乍一看可能会有点蒙,没关系,等一点点学完这些再看就OK了。
现在,让我们回到今天的主题:Map接口,来看一下Map接口下有哪些实现类?
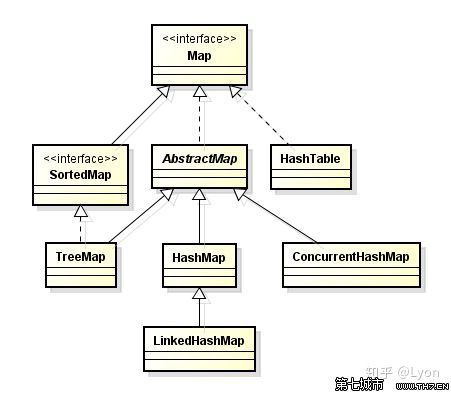
可以看到Map接口下又分为SortedMap接口、AbstractMap接口。
实现SortedMap接口的实现类有TreeMap。
实现AbstractMap接口的实现类有:TreeMap、HashMap、ConcurrentHashMap。
而LinkedHashMap直接继承自HashMap。
2.HashMap和LinkedHashMap的关系梳理
看完上面Map接口的类图,大家应该对Map系列有了一个大概的印象,现在让我们回到LinkedHashMap:
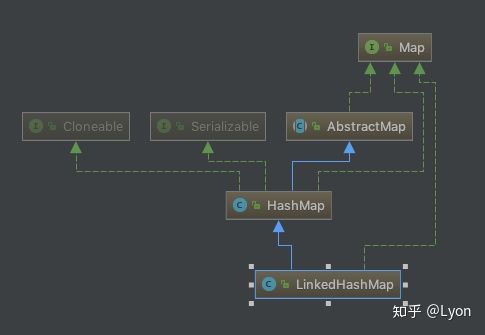
如图:LinkedHashMap直接继承了HashMap,属于其子类,且实现了Map接口。
是不是很简单?那么,问题来了,既然有HashMap了,那为什么还需要LinkedHashMap?
说到这里,就不得不从HashMap开始说起,HashMap虽然是一种高效的数据结构,既有数组随机访问的优势,又有链表能快速增删的特点,但它有个最大的缺点:不能记录key-value值插入的顺序,因为HashMap索引index是根据key通过hash(key)来随机映射的,所有并不能记录和保存元素的插入顺序,这就比较尴尬了。
为了解决这个问题,设计者们创造出了—HashMap的子类LinkedHashMap,其仍然保留HashMap的数据结构,只额外增加了双链表的设计来将插入的元素链接起来从而让其有序。这样保证了遍历LinkedHashMap时就可以根据元素的插入顺序(或访问顺序)输出元素。
3.LinkedHashMap的底层数据结构
在了解了LinkedHashMap和HashMap的关系后,让我们来看一下LinkedHashMap的底层数据结构,LinkedHashMap在HashMap增加了双链表的设计,那么究竟是怎么设计的?双链表又是如何添加到HashMap上的?
来看一张图:
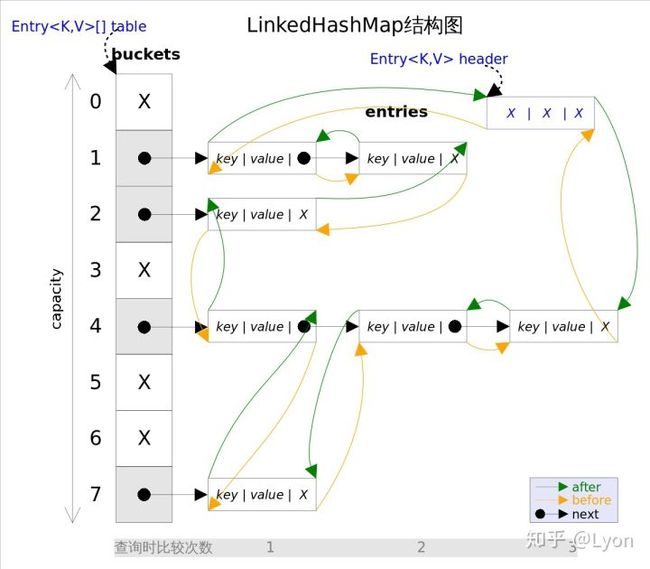
可以看到LinkedHashMap的底层数据结构,就是HashMap的链表数组,只不过对每一个原Node
4.LinkedHashMap源码解读
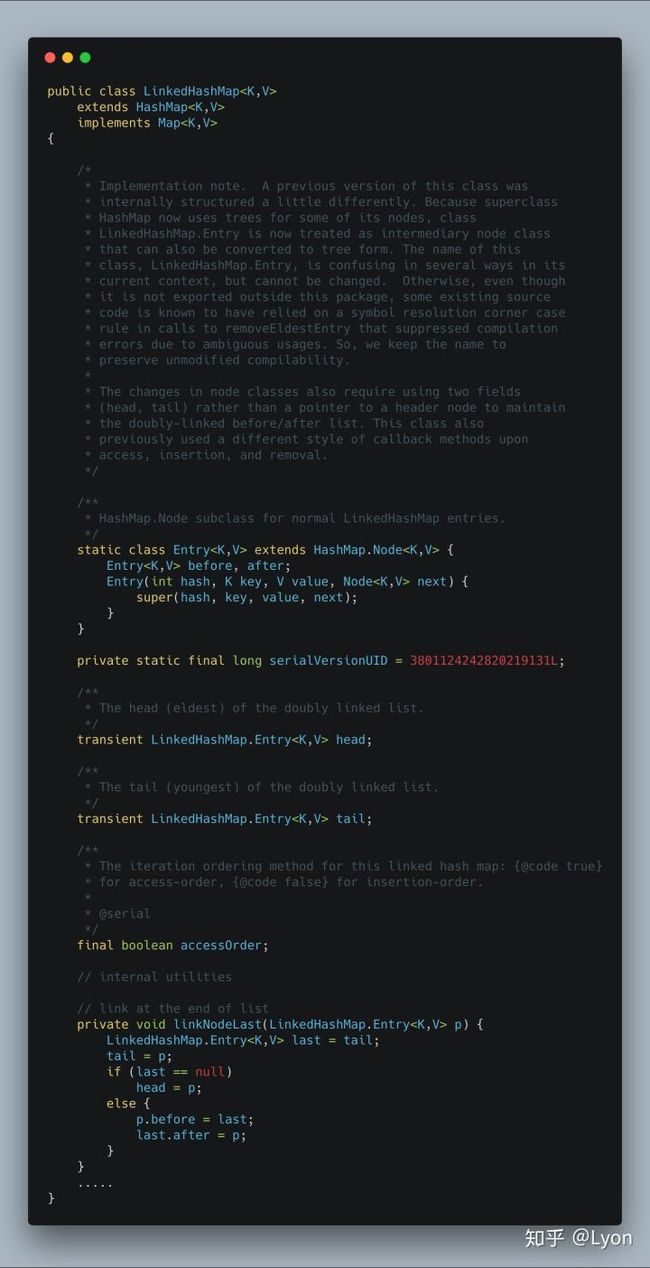
首先,类的定义:
public class LinkedHashMap extends HashMap implements Map
这个我们之前已经说过了,现在看一下LinkedHashMap中的成员变量吧:
boolean的成员变量:accessOrder
Entry
Entry
1.在看这些成员变量之前,我们首先来看一下内部类Entry
/**
* HashMap.Node subclass for normal LinkedHashMap entries.
*/
static class Entry extends HashMap.Node {
Entry before, after;
Entry(int hash, K key, V value, Node next) {
super(hash, key, value, next);
}
}
可以看见Entry继承了HashMap中的Node,Entry类中有两个Entry
总结下就是:LinkedHashMap中的节点Entry继承自HashMap中的节点Node,且Entry中添加了before和after用链接节点从而构成双链表。
2.回到LinkedHashMap中的成员变量:
boolean的成员变量:accessOrder
Entry
Entry
现在就很清楚了,head和tail就是用于标记双链表头和尾的指针节点。accessOrder是干嘛的?让我们看下源码上的注释:
/*
** The iteration ordering method for this linked hash map: {*@code true}
** for access-order, {@code *false} for insertion-order.
** @serial*
*/
翻译下:accessOrder用于标记此LinkedHashMap中遍历迭代的顺序
accessOrder = true时按访问顺序遍历,false时,按插入顺序遍历
3.解读LinkedHashMap的put()方法源码:
虽然,我们已经清楚地知道了LinkedHashMap双链表的底层实现—Entry
在源码中找了一圈,并没有发现put()方法,哈哈此处有坑!LinkedHashMap继承自HashMap,且并没有重写put()方法,LinkedHashMap添加元素用的就是HashMap中的put()方法。那么,问题又来了,如果没有重写put方法,那么添加元素的时候是如何记录顺序,链接节点的呢?
我们回到HashMap中putVal方法中,发现有个newNode()方法,每次添加新节点时总会通过newNode(hash, key, value, null);来生成一个新节点,然后再插入。哦,原来如此。
回到LinkedHashMap的源码中,果然我们发现了这个newNode()方法:
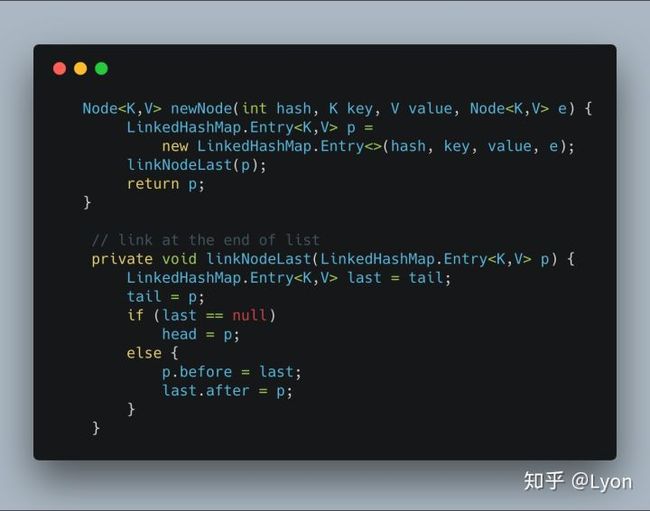
newNode()中new了一个Entry节点,然后调用linkNodeLast()方法将节点链接到链表尾。最后return了这个节点。现在,一切都清楚了:
一个LinkedHashMap对象调用put()方法添加对象时,调用的是其父类HashMap中的put方法,根据key,生成hash值再求出其在table中的索引i,然后放入相应桶中的过程完全一样。只是在new节点元素时将原Node节点变成了包含链表指针的Entry节点,然后多了移步操作:将此节点链接到双链表的表尾。
看完文章觉得不错亲盆好友们,麻烦高抬贵手,点个哦,谢谢~
下一篇文章:Java集合框架—TreeMap—源码研读