1. Kafka消费方式:
通过Flume,将kafka消息存储到HDFS
通过Spark Streaming读取kafka消息,存储到redis
2. 高级API和低级API的区别
https://www.jianshu.com/p/2369a020e604
高级API在Spark的工作节点上创建消费者线程,订阅Kafka中的消息,数据会传输到Spark工作节点的执行器中,为了保证数据可靠性,需要在Spark Streaming中开启Write Ahead Logs(WAL)可以选择让Spark把WAL保存在HDFS中,高级API写起来简单,不需要自行管理offset,系统通过zookeeper自行管理,不需要管理分区、副本等情况,系统自动管理,消费者断线会自动根据上一次记录在zookeeper中的offset去接着获取数据(默认设置1min更新一下zookeeper中存的offset),可以使用group将对同一个topic的不同程序访问分离开来(不同的group记录不同的offset,这样不同程序读取同一个topic才不会因为offset互相影响);缺点是不能自行控制offset,不能细化控制分区、副本、zk等
低级API不需要建立消费者线程,使用createDirectStream接口直接读取Kafka的WAL,将Kafka分区与RDD分区做一对一映射,相较于第一种方法,不需要再维护一份WAL数据,提高了性能,读取数据的偏移量由Spark Streaming程序通过检查点机制自身处理,能够开发者自己控制offset,想从哪里读取就从哪里读取,自行控制连接分区,对分区自定义进行负载均衡,对zookeeper的依赖性降低(如:offset不一定非要靠zk存储,自行存储offset即可,比如存在文件或者内存中);缺点是太过复杂,需要自行控制offset,连接哪个分区,找到分区leader等
3. Kafka提供了单一的消费者模型:消费者组,消费者都有消费者组(不指定时默认为group),topic上的每个消息只会被订阅该主题的各消息组中的一个消费者收取
4. Kafka中,消息是由Consumer主动从Broker拉取,即Consumer和Broker建立连接后,根据自己的消费能力,主动pull(fetch)消息
5. kafka原理
https://blog.csdn.net/YChenFeng/article/details/74980531
6. Kafka Broker Leader的选举
Kafka集群通过zookeeper管理,所有kafka节点在zookeeper注册临时节点,只有一个节点可以注册成功,注册成功的节点成为Kafka Broker Controller,其他节点成为Kafka Broker Follower
7. Consumergroup:各个consumer可以组成一个组(Consumer group),partition中的每个message只能被组中的一个consumer消费
8. Kafka为了保证吞吐量,只允许同一个consumer group中的一个consumer线程去访问一个partition,然后通过增加partition数量来扩展,相应的增加consumer,如果想要多个业务都需要同一个topic的数据,则可以启动多个consumer group
9. 最优的设计是,consumer group下的consumer thread的数量等于partition数量,这样效率是最高的
10. Consumer Rebalance的触发条件:
Consumer的增加或删除
Broker的增加或减少
11. 如果producer的流量增大,当前的topic的partition数量 = consumer数量,这时候的应对方式是横向扩展,增加topic下的partition,同时增加这个consumer group下的consumer
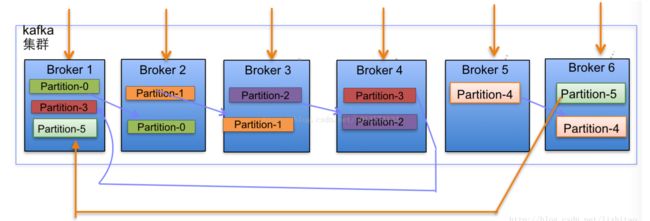
12. 一般来说,一个topic的partition数量 >= broker数量,可以提高吞吐量;同一个partition的replica尽量分散到不同的机器,高可用
13. topic分配partition和partition replica算法:
将broker(size = n)和待分配的partition排序,将第i个partition分配到第i%n个broker,将第i个partition的第j个replica分配到(i + j)%n个broker
14. ISR:in-sync Replica,Leader中记录的与其保持同步的Replica列表
15. producer采用异步push方式,极大提高Kafka系统的吞吐率
16. partition:topic物理上的分组,一个topic可以分为多个partition,每个partition是一个有序的队列
17. segment:partition物理上由多个segment组成,每个segment存着message信息
18. producer broker consumer
producer端使用zookeeper用来发现broker列表,以及和topic下每个partition leader建立socket连接并发送消息
broker端使用zookeeper注册broker信息,以及监测partition leader存活性
consumer端使用zookeeper注册consumer信息,其中包括consumer消费的partition列表,同时也用来发现broker列表,并和partition leader建立socket连接,并获取信息
19. Kafka的核心是日志文件,日志文件在集群中的同步是分布式数据系统最基础的要素
20. kafka动态维护了一个同步状态的副本的集合(a set of in-sync replicas),简称ISR,在这个集合中的节点都是和leader保持高度一致的,任何一条消息必须被这个集合中的每个节点读取并追加到日志中,才会通知外部,这个消息已经被提交,因此这个集合中每个节点随时都可以被选为leader。当所有副本都down掉时,选择所有节点中(不只是ISR)第一个恢复的节点作为leader
21. 创建副本的单位是topic的分区,每个分区都有一个leader和零~多个followers,所有读写操作都由leader处理,一般分区数量都比broker数量多的多,各分区的leader均匀分布在brokers中,followers像普通的consumer那样,从leader那里拉取消息并保存在自己的日志文件中
22. 利用kafka的compacted topic,offset以consumer group, topic与partition的组合作为key直接提交到compacted topic中,同时kafka又会在内存中维护了三元组来维护最新的offset信息,consumer来取最新的offset信息的时候,直接从内存中取即可,当然,kafka允许你快速的checkpoint最新的offset信息到磁盘中
23. 副本分配逻辑规则
在kafka集群中,每个broker都有均等分配partition的leader机会
每个broker(按照brokerid有序)依次分配主partition,下一个broker为副本,如此循环迭代分配,多副本都遵循此规则
副本分配算法:
将所有N broker和待分配的i个partiton排序
将第i个partition分配到第(i mod n)个broker上
将第i个partition的第j个副本分配到第((i + j) mod n)个broker上
24. 因每个partition只会被consumer group内的一个consumer消费,故kafka保证每个partition内的消息会被顺序的订阅
25. kafka支持以集合(batch)为单位发送消息,在此基础上,kafka还支持对消息集合进行压缩,producer端可以通过gzip或snappy格式对消息集合进行压缩,producer端进行压缩后,consumer端需要解压,压缩的好处是减少传输的数据量,减轻对网络传输的压力
26. producer以batch的方式推送数据可以极大的提高处理效率,kafka producer可以将消息在内存中累计到一定数量后作为一个batch发送请求,通过增加batch的大小,可以减少网络请求和磁盘IO的次数
27. 对于consumer group,允许consumer group(包含多个consumer,如一个集群同时消费)对一个topic进行消费,不同的consumer group之间独立消费;指定partition为最小的并行消费单位,即一个group内的consumer只能消费不同的partition
28. zookeeper协调控制
管理broker与consumer的动态加入与离开(producer不需要管理,随便一台计算机都可以作为producer向kafka broker发消息)
触发负载均衡,当broker或consumer加入或离开时会触发负载均衡算法,使得一个consumer group内的多个consumer的消费负载均衡(因为一个consumer消费一个或多个partition,一个partition只能被一个consumer消费)
维护消费关系以及每个partition的消费信息
29. kafka tool
http://www.kafkatool.com/
start:topic的开始offset
end:topic的最大offset
offset:当前消费者消费到的offset
lag:消费者还没有消费的消息
30. reblance
reblance本质是一种协议,规定一个consumer group下所有consumer如何达成一致来分配订阅topic的每个分区。比如某个group下有20个consumer,它订阅了一个具有100个分区的topic,正常情况下,kafka平均会为每个consumer分配5个分区,这个分配的过程叫做reblance
kafka新版本consumer默认提供两种分配策略:range和round-robin
31. 谁来执行reblance和consumer group管理
coordinator来执行对于consumer group的管理;每个consumer group都会被分配一个coordinator用于组管理和位移管理
32. 如何确定coordinator
a. 确定consumer group位移信息写入_consumers_offsets的哪个分区
b. 该分区leader所在的broker就是被选定的coordinator