推荐系统论文:Deep Interest Network for Click-Through Rate Prediction
论文地址:Deep Interest Network for Click-Through Rate Prediction
论文由阿里广告技术团队提出,是一篇实践性很强的文章。
ABSTRACT
目前基于深度学习的CTR预估方法,基本结构都是Embedding+MLP,高维稀疏特征映射为低维embedding,所有特征拼接起来喂给MLP学习特征的非线性。此时无论候选商品是什么,user vector被表示为某个固定的向量,这限制了从历史行为中捕捉用户兴趣的多样性。文章提出Deep Interest Network (DIN),根据候选商品的不同,适应性学习user vector的方法。
1. INTRODUCTION
Embedding+MLP的方法把用户多样的兴趣点都压缩到一个固定长度的向量中,这限制了模型的表达能力。如果直接增加user vector的维度,会增加参数量和计算量,并且有过拟合的风险。
此外,对于一个候选商品,没有必要把用户的所有兴趣点都映射到user vector中,因为只有部分兴趣会决定用户对候选商品的点击与否的行为。比如一位女士会点击推荐的泳镜,主要是因为她买了泳衣,而不是她上周买的一双鞋。
由此提出DIN,引入 local activation unit 计算历史行为与候选商品的相关性,之后对用户的兴趣点做weighted sum pooling ,得到对当前候选商品用户兴趣的表示向量。与候选商品相关性越高的行为,激活权重越大,在用户兴趣表征中占主导地位。那么对不同的候选商品,用户兴趣的表达向量是不同的,提高了模型在有限维度下的表征能力,能够更好地捕捉用户的各种兴趣。
文章还提出一种适应性的正则化方法,以及由PReLU推广而来的适应性的Dice激活函数。
2. RELATEDWORK
FM捕捉二阶交叉特征。Deep Crossing,Wide&Deep Learning 引入MLP提高模型表达能力。PNN引入 product 层捕捉高阶交叉特征。DeepFM在 WDL 基础上引入FM,并不再手动构造特征。
这些方法都是Embedding+MLP结构。但对于具有丰富用户行为的应用来说,把若干embeddings通过 sum/average pooling 得到fixed-length 向量是对信息的浪费。
3. DEEP INTEREST NETWORK
3.1 Feature Representation
对于某条数据,可以表示为如下形式:
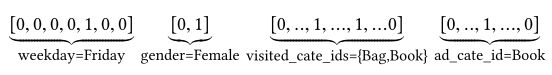
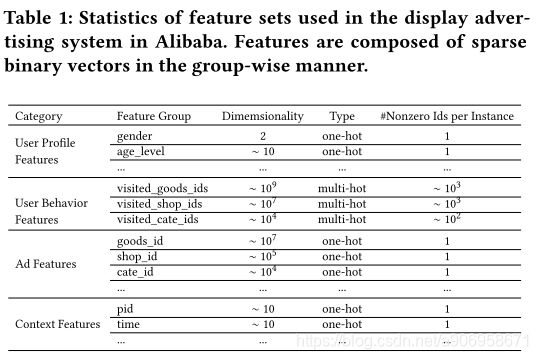
下表为使用全部特征,主要由4类组成:用户基本特征、用户行为特征、候选商品特征、上下文特征。
3.2 Base Model(Embedding&MLP)
主要包含:Embedding layer,Pooling layer and Concat layer,MLP。损失函数为二分类的交叉熵损失函数,S是N个训练样本,x是模型输入,标签y∈(0,1),p(x)是模型经过softmax层后的输出,代表这条样本x的候选商品被点击的概率。
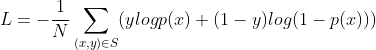
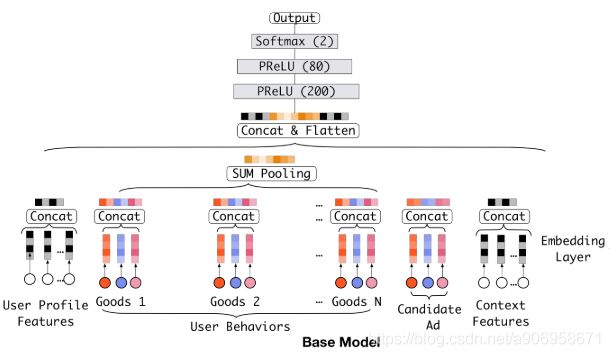
3.3 The structure of Deep Interest Network
用户行为特征至关重要,与候选商品相关的历史行为对点击有很大的影响。DIN考虑历史行为的相关性,自适应地计算用户兴趣的表示向量,而不是用同一个向量来表达所有的不同兴趣。
DIN引入 local activation unit,其他结构与 base model 相同,activation unit 应用在用户行为特征上,作为一个 weighted sum pooling,适应性的计算用户embedding向量。对于候选商品A,用户U的embedding向量可以表示为:
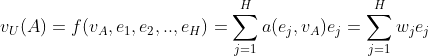
![]() 代表H个用户行为特征embedding,
代表H个用户行为特征embedding,![]() 代表候选商品的embedding,
代表候选商品的embedding,![]() 是一个前向网络,输入两个embedding向量,输出权重。
是一个前向网络,输入两个embedding向量,输出权重。
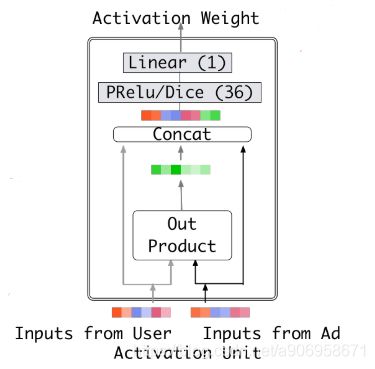
与传统attention方法不同,为了保留用户兴趣的强度,没有约束![]() 。这里的
。这里的![]() 可以被看作在某一方面激活用户兴趣强度的近似,比如某用户历史行为包括90%的衣服和10%的电子产品,那么对于T恤和手机两个候选商品,T恤将会激活历史行为中的大部分衣物行为,会得到更大的
可以被看作在某一方面激活用户兴趣强度的近似,比如某用户历史行为包括90%的衣服和10%的电子产品,那么对于T恤和手机两个候选商品,T恤将会激活历史行为中的大部分衣物行为,会得到更大的![]() ,也就是相比于手机,对T恤有更强烈的兴趣。
,也就是相比于手机,对T恤有更强烈的兴趣。
4. TRAINING TECHNIQUES
4.1 Mini-batch Aware Regularization
如果不适用正则化,在当前特征的规模下,模型会严重过拟合。但是,在具有稀疏输入和数亿参数的网络训练上,直接使用传统的正则化方法(L1、L2正则)又不现实。
例如,使用不带正则化的梯度下降优化方法时,只有在每个mini-batch中出现的非0稀疏特征的相关参数才会被更新。但是如果加入L2正则,那么对每个mini-batch,需要计算所有参数的L2范数,在参数规模达到数亿的情况下是无法接受的。
本文提出一种自适应的正则化方法,只计算在每个mini-batch中出现的特征的相关参数的L2范数。实际上,embedding dictionary 占据了网络模型的大部分参数量,令![]() 代表整个 embedding dictionary 的参数,D是embedding向量的维度,K是特征空间的维度,在样本上表示为:
代表整个 embedding dictionary 的参数,D是embedding向量的维度,K是特征空间的维度,在样本上表示为:
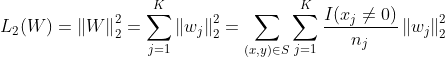
其中![]() 是第j个embedding向量,
是第j个embedding向量,![]() 代表样本x是否含有feature id j,
代表样本x是否含有feature id j,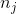 代表feature id j在所有样本中的出现次数。在mini-batch形式下,B代表batch的个数,
代表feature id j在所有样本中的出现次数。在mini-batch形式下,B代表batch的个数,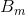 代表第m个batch,上式可表示为:
代表第m个batch,上式可表示为:
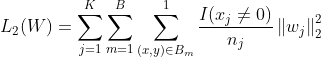
令 ![]() 代表在第m个batch中是否有至少一个样本包含feature id j,则上式可近似表示为:
代表在第m个batch中是否有至少一个样本包含feature id j,则上式可近似表示为:
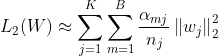
那么,得到一个近似的带有L2正则的mini-batch参数更新方法,对第m个batch,feature j的embedding权重更新为:

4.2 Data Adaptive Activation Function
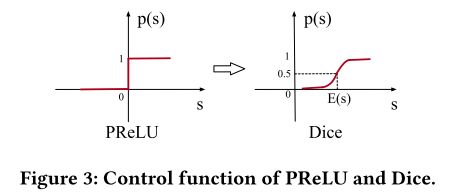
传统PReLU,![]() ,控制激活函数的选择。
,控制激活函数的选择。
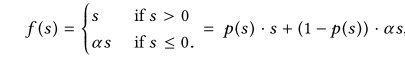
当各层的输入服从不同的分布时,PReLU取0值作为恒定的修正点可能不合适,因此提出一种根据输入的分布而自适应的激活函数,叫做Dice。当E和Var都为0时,Dice就退化为PReLU。
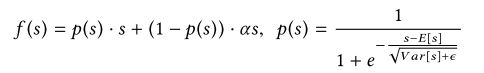
与PReLU的不同之处在于p(s),在训练时E和Var是每个mini-batch输入的均值和方差,在测试阶段,E和Var是数据E和Var的平均,ε防止分母为0,设为1e-8。
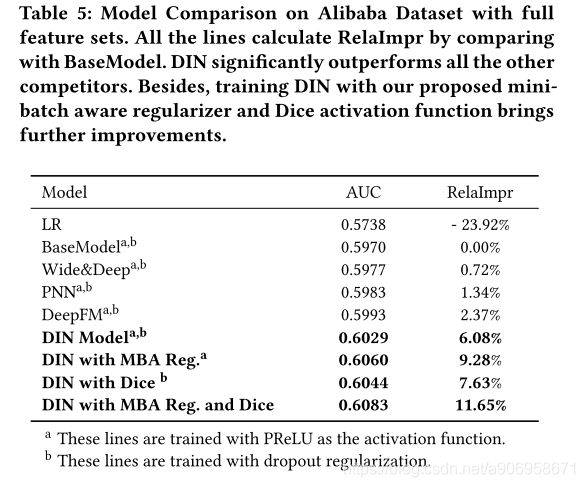
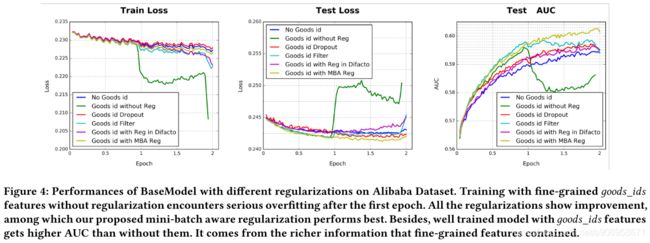
5. EXPERIMENTS